ElasticSearch降本增效常见的方法 | 京东云技术团队
Elasticsearch在db_ranking 的排名不断上升,其在存储领域已经蔚然成风且占有非常重要的地位。
随着Elasticsearch越来越受欢迎,企业花费在ES建设上的成本自然也不少。那如何减少ES的成本呢?今天我们就特地来聊聊ES降本增效的常见方法:
-
弹性伸缩
-
分级存储
-
其他:(1)数据压缩(2)off heap
1 弹性伸缩
所谓弹性伸缩翻译成大白话就是随时快速瘦身与增肥,并且是头痛医头,按需动态调整资源。当计算能力不足的时候我们可以快速扩充出计算资源;当存储资源不足时,能够快速扩容磁盘,。
1-1 计算存储分离
ES使用计算存储分离架构之后,解决了资源预留而造成资源浪费的问题。在早期大家认为的计算存储分离的实现方式为:使用云盘代替本地盘,这种实现方式可以提高数据的可靠性、可以快速弹扩磁盘资源和计算资源,但是es自身弹性需求是无法解决,即秒级shard搬迁和replica扩容。
那么如何解决es自身的弹性呢?本文该部分将给出答案。
共享存储版ES
本文该部分将介绍我们京东云-中间件搜索团队,研发的共享存储版本ES;计算存储分离架构如图1-2所示
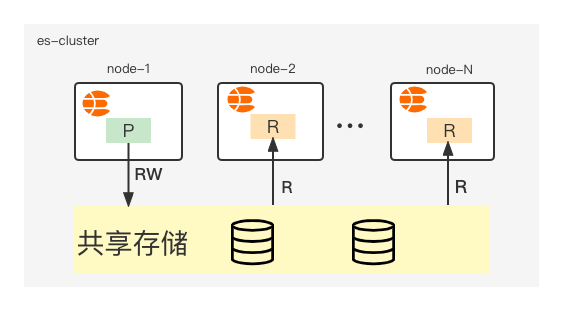
图 1-2 计算存储分离架构(共享)
如图1-2所示,我们只存储一份数据,primary shard负责读写,replica只负责读;当我们需要扩容replica的时候无需进行数据搬迁,直接跳过原生es的peer recover两阶段,秒级完成replica的弹扩。
当主分片发生relocating时,可以直接跳过原生es的peer recover第一阶段(该阶段最为耗时),同时也不需要原生es的第二阶段发送translog。
共享版本的计算存储分离ES,相对于原生的ES和普通版本的计算存储分离,具有如下突出的优势:
-
数据只保存一份,存储成本倍数级降低
-
存储容量按需自动拓展,几乎无空间浪费
-
按实际用量计费,无需容量规划
性能测试
-
数据集为esrally提供的http_logs
-
共享版ES7.10.2: 3个data节点(16C64GB)
-
原生ES7.10.2: 3个data节点(16C64GB)
表 1-1 1副本性能测试对比
| refreh | 原生本地ssd盘(doc/s) | 原生云盘(doc/s) | 共享存储(doc/s) | 性能对比(本地盘) |
|---|---|---|---|---|
| 默认 | 107159 | 97240.9 | 148965 | 39% |
| 5s | 111394 | 97933 | 125957 | 13% |
| 15s | 111837 | 96842.9 | 141363 | 26% |
我们的初步性能测试结果如表1-1所示;副本数越多,共享版本的es越具有优势;
从表1-1所示我们可以看出性能似乎提升的不是特别理想,目前我们正从两个方面进行优化提升:
-
底层依赖的云海存储,目前正在有计划地进行着性能提升
-
源码侧,我们也在正在优化ing
在研发es计算存储分离的过程中,我们攻克了很多的问题,后续将输出更加详细的文章进行介绍,比如:主写副只读的具体实现,replica的访问近实时问题,ES的主分片切换脏写问题等等。
1-2 外部构建Segment
对于有大量写入的场景,通常不会持续的高流量写入,而只有1-2个小时写入流量洪峰;在写入过程中最耗费时间的过程并不是写磁盘而是构建segment,既然构建segment如此耗时,那么我们是否可以将该部分功能单独出来,形成一个可快速扩展的资源(避免去直接改动es源码而引入其他问题)。
目前业界已经有比较好的案例外部构建Segment,相对于共享存储版的es实现起来更简单;它的核心解决方案使用了spark或者map reduce这种批处理引擎进行批量计算处理,然后将构建好的segment搬运到对应的索引shard即可。
外部构建segment的功能也在我们的规划中。
2 分级存储
ES实现降本增效的另外一个方向:分级存储,该解决方案主要是针对数据量大查询少且对查询耗时不太敏感的业务。分级存储,比较成熟的解决方案有es冷热架构和可搜索快照。
2-1 冷热架构
冷热架构适用场景:时序型数据或者同一集群中同时存在这两个索引(一个热数据,另外一个冷数据)
es冷热架构架构,该功能已经在京东云上线有一段时间了,欢迎大家根据自己的业务形态进行试用,冷数据节点开启如图2-1所示

图 2-1 冷数据节点开启
建议如果索引表是按天/小时,这种周期存储的数据,且数据查询具有冷热性,建议开启冷节点;开启冷节点后你可能会获得如下的收益:
-
开启冷节点后可以降低你的存储成本,因为存放冷节点的索引我们可以选择减少副本数、冷节点的存储介质更便宜
-
集群可以存放更多的数据
-
冷数据forcemerge,提升冷数据的查询性能
-
冷数据从热节点迁移走之后,减少热节点的资源占用,从而使热查询更快
冷热架构的核心技术为
shard-allocation-filtering;
冷热架构实现原理:
es的hot节点增加如下配置
node.attr.box_type: hot
es的warm节点增加如下配置
node.attr.box_type: warm
热数据索引setting增加如下配置,即可限制shard分配在hot节点
"index.routing.allocation.require.box_type": "hot"
当数据查询减弱,我们通过如下配置,即可使数据由hot节点迁移到warm节点
"index.routing.allocation.require.box_type": "warm"
2-2 可搜索快照
可搜索快照是在冷热架构的基础上更进一步的分级存储,在之前我们将数据快照之后是无法对快照的数据进行搜索,如果要对快照的数据进行搜索,则需将快照数据先restore(restore的过程可能会比较长)之后才能被搜索。
在引入可搜索快照之后,我们可以直接搜索快照中的数据,大大降低了没必要的资源使用.
3 其他
3-1 数据压缩
除了从资源的角度进行降低存储成本之外,基于数据自身的特性,使用优秀的压缩算法也是一种必不可少的搜索;针对时序数据facebook开源了一个非常优秀的压缩算法zstd,目前已经在业界被大量使用。
表 3-1 三种压缩算法的对比测试结果
| 压缩算法 | 加载时间(1 Shard) | 加载时间(5 Shards) | Fields(*fdt)文件大小 | 索引总大小 |
|---|---|---|---|---|
| LZ4 | 1143769ms | 420447ms | 4.15 GB | 6.3 GB |
| Deflate | 1270408ms | 448738ms | 2.56 GB | 4.7 GB |
| Zstandard(16K Chunk) | 1109414ms | 415256ms | 2.93 GB | 5.1 GB |
| Zstandard(32K Chunk) | 1088959ms | 406661ms | 2.67 GB | 4.8 GB |
目前在lucene的代码库中也有开源爱好者提交了custom codec providing Zstandard compression/decompression (zstd pr)
3-2 off heap
es单个节点存储数据量受到jvm堆内存的限制,为了使单个节点能够存储更多的数据,因此我们需要减少堆内存中的数据。
ES 堆中常驻内存中占据比重最大是 FST,即 tip(terms index) 文件占据的空间,1TB 索引大约占用2GB 或者更多的内存,因此为了节点稳定运行,业界通常认为一个节点 open 的索引不超过5TB。现在,从 ES 7.3版本开始,将 tip 文件修改为通过mmap的方式加载,这使 FST占据的内存从堆内转移到了堆外(即off Heap技术 )由操作系统的 pagecache 管理[6]。
使用esrally官方数据集geonames写入索引1TB,使用 _cat/segments API 查看 segments.memory内存占用量,对比 offheap 后的内存占用效果,如表3-2所示;JVM 内存占用量降低了表 3-2 segments.memory内存占用量
| store.type | segments.memory |
|---|---|
| niofs | 4.7GB |
| hybrids | 1.06GB |
4 参考
[1] Indexing Service
[2] ES-Fastloader
[3] 大规模测试新的 Elasticsearch 冷层可搜索快照
[4] Introducing Elasticsearch searchable snapshots
[5] 7.7 版本中的新改进:显著降低 Elasticsearch 堆内存使用量
[6] Elasticsearch 7.3 的 offheap 原理
作者:京东科技 杨松柏
来源:京东云开发者社区 转载请注明来源
热门相关:霸宠天下:腹黑帝君妖娆后 拳罡 锦绣医妃之庶女凰途 唐土万里 唐土万里