架构和运行机制
本篇主要介绍Streamlit的核心架构和运行机制,
目的是希望朋友们能先从整体上宏观的了解Streamlit,利用它提供的机制开发性能更高效的应用。
1. 架构
Streamlit比较特殊,它对使用者来说是BS架构应用,而随开发者来说其实更像一个CS架构的应用。
为什么说Streamlit更像CS架构呢?
因为后端功能和前端UI部分都是用Python写,所以开发Streamlit应用时的感觉,就像开发桌面应用一样。
如果你有CS应用的开发经验,比如QT,.Net平台的winform或WPF等,那么开发Streamlit的应用会觉得非常亲切。
虽然最终是在浏览器中使用Streamlit应用,但是开发时完全不需要HTML、CSS或JavaScript等前端知识。
不过,Streamlit App部署之后,需要注意它BS应用的一面:
Streamlit App发布之后是多用户使用的,根据预估的用户量考虑服务器的配置资源- 用户端通过浏览器来使用
Streamlit App,所以无法访问服务器的文件、目录或操作系统。 - 如果需要与任何外围设备(如摄像头)通信,则必须使用
Streamlit命令或自定义组件,这些命令或组件将通过用户的浏览器访问这些设备
2. 运行流程
Streamlit的主要流程简单直接:
- 服务端通过
streamlit run命令启动 - 初始化
App页面 - 客户端打开浏览器访问
- 用户在浏览器中操作
- 服务端根据用户操作进行数据处理
- 处理之后更新页面
- 新的页面返回到浏览器
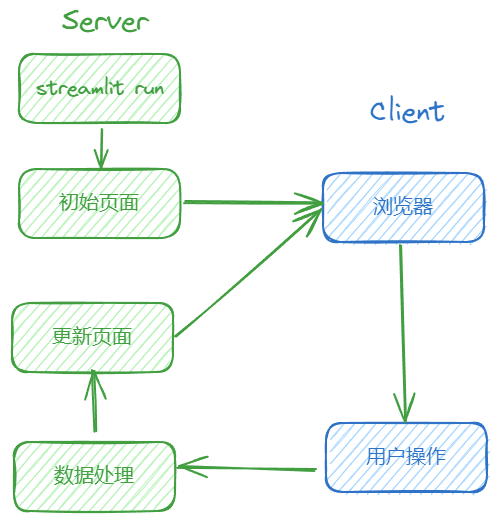
Streamlit App每次接收用户操作之后,会重新运行整个代码,然后将重新渲染的页面返回,
这样会带来两个显而易见的问题。
- 如果代码中加载了大量的数据,每次用户操作后都会重新加载数据,影响性能
比如:
import streamlit as st
import pandas as pd
from datetime import datetime
## 数据加载
def load_data():
df = pd.DataFrame()
df.index = pd.date_range("2024/10/01", periods=20)
df["A"] = range(20)
df["B"] = range(20)
st.text(f"加载数据时间:{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}")
return df
# 加载数据
data = load_data()
date_range = st.slider(
"日期范围",
min_value=datetime(2024, 10, 1),
max_value=datetime(2024, 10, 20),
value=(datetime(2024, 10, 1), datetime(2024, 10, 20)),
)
data = data[data.index >= date_range[0]]
data = data[data.index <= date_range[1]]
st.table(data)
每次加载数据时,会显示数据加载的时间:st.text(f"加载数据时间:{datetime.now().strftime("%Y-%m-%d %H:%M:%S")}")
每次移动日期范围时,都会重新加载整个数据。
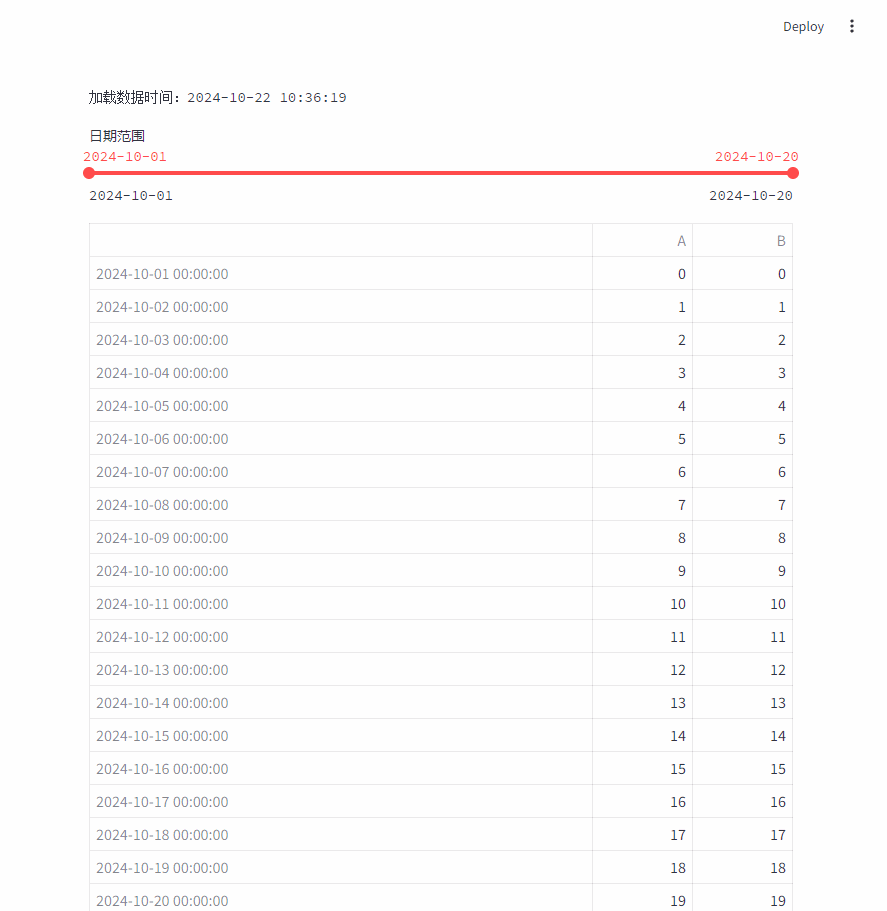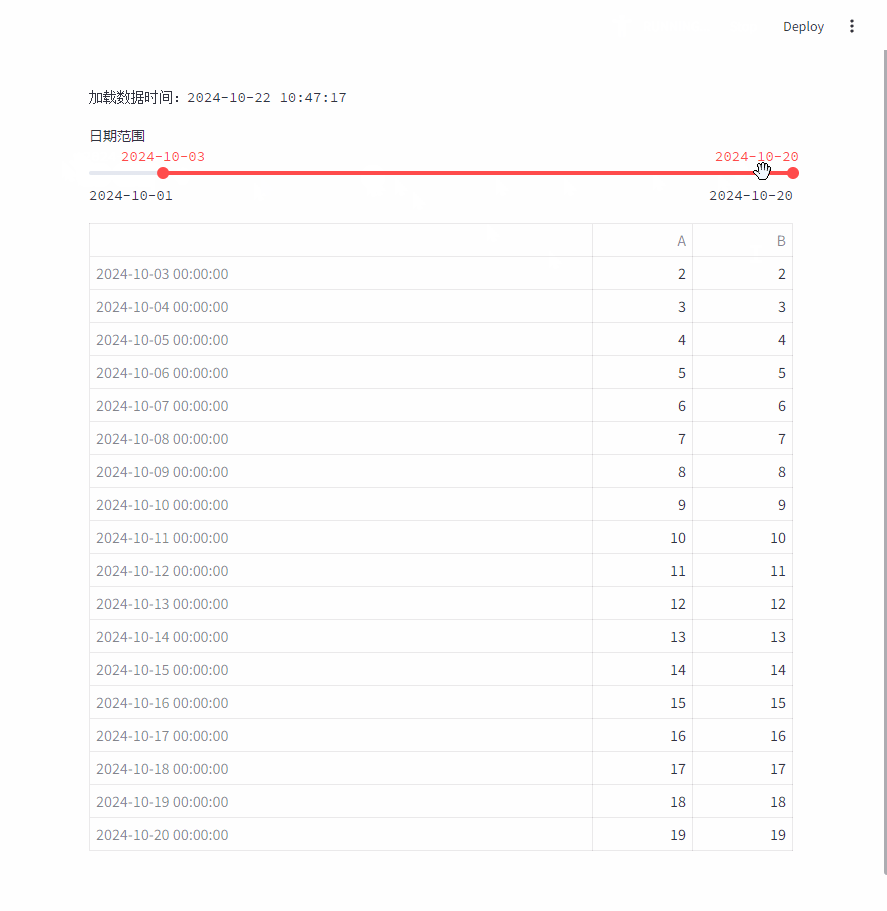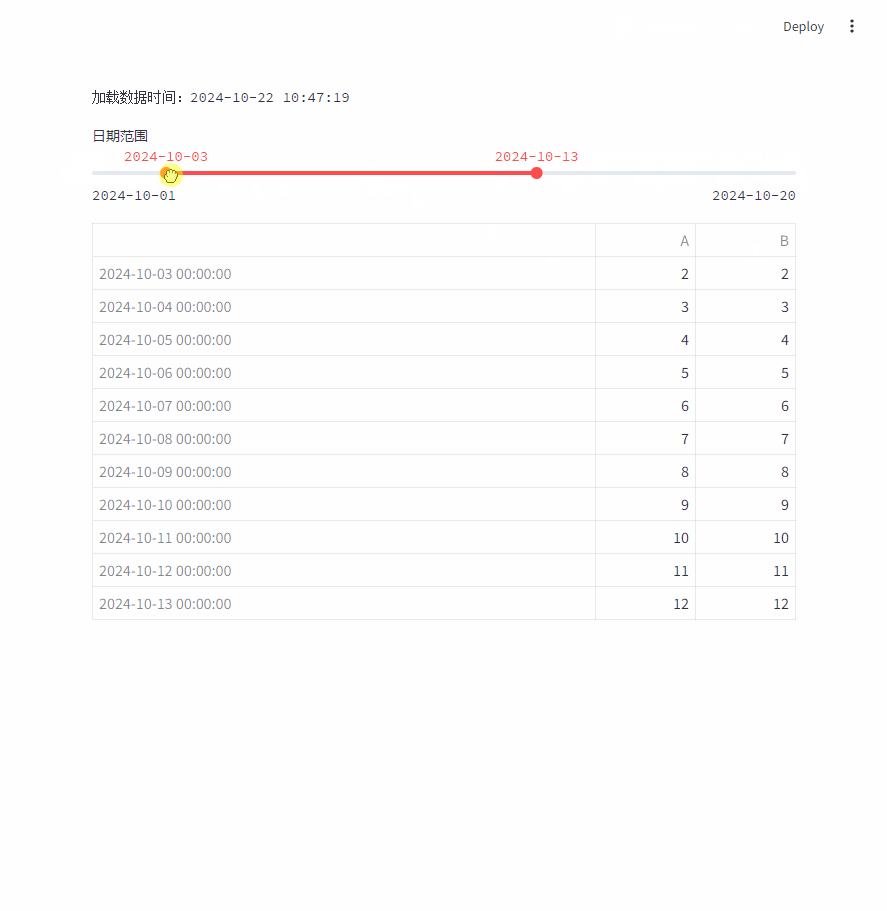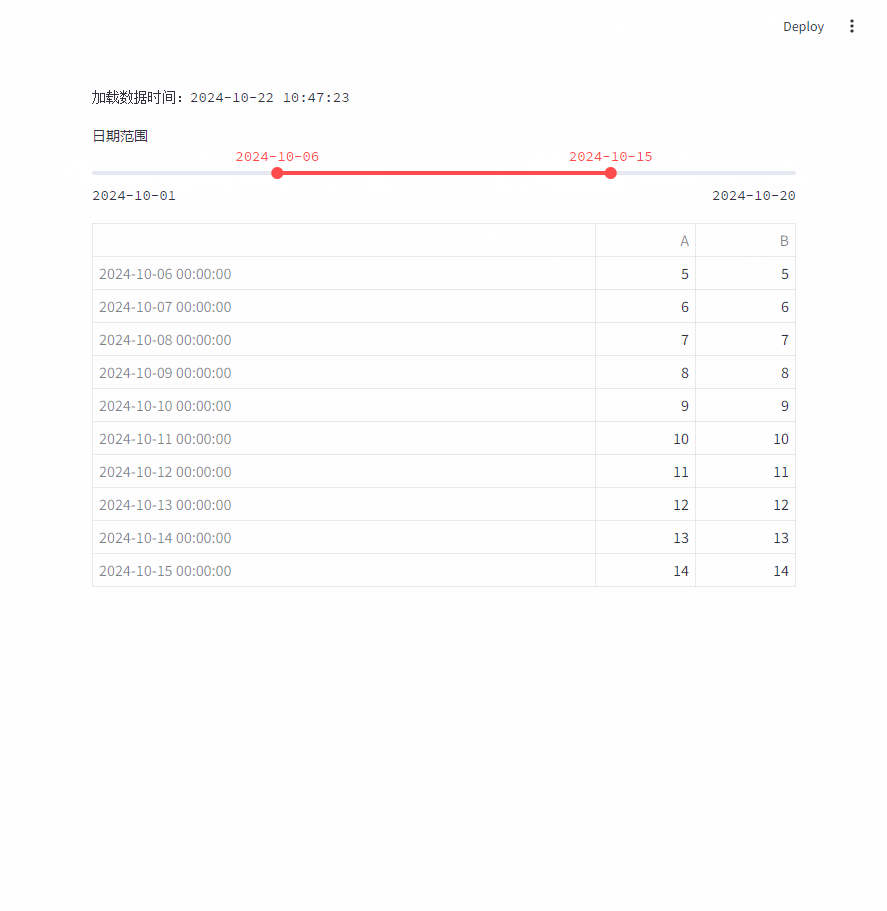
- 多个用户操作直接如果有联系,操作之间的状态无法保持
比如:
count = 0
st.text(f"Click {count}")
if st.button("ADD"): # 点击按钮时执行
count += 1

点击上面的按钮ADD,文本显示的始终是:Click 0。
因为,点击按钮时,执行count += 1之后,还会将整个代码重新执行,count=0 也被重新执行。
下一节介绍如何解决这两个问题。
3. 缓存和状态
解决Streamlit App的数据和状态无法保存的问题,就要用到缓存(cache)和状态(session)两个重要的功能。
首先,用缓存来改进上一节中的数据加载问题。
## 数据加载
@st.cache_data
def load_data():
#... 省略 ...
修改方法非常简单,只要在原来代码中的load_data函数上面加一个装饰器@st.cache_data就足够了。
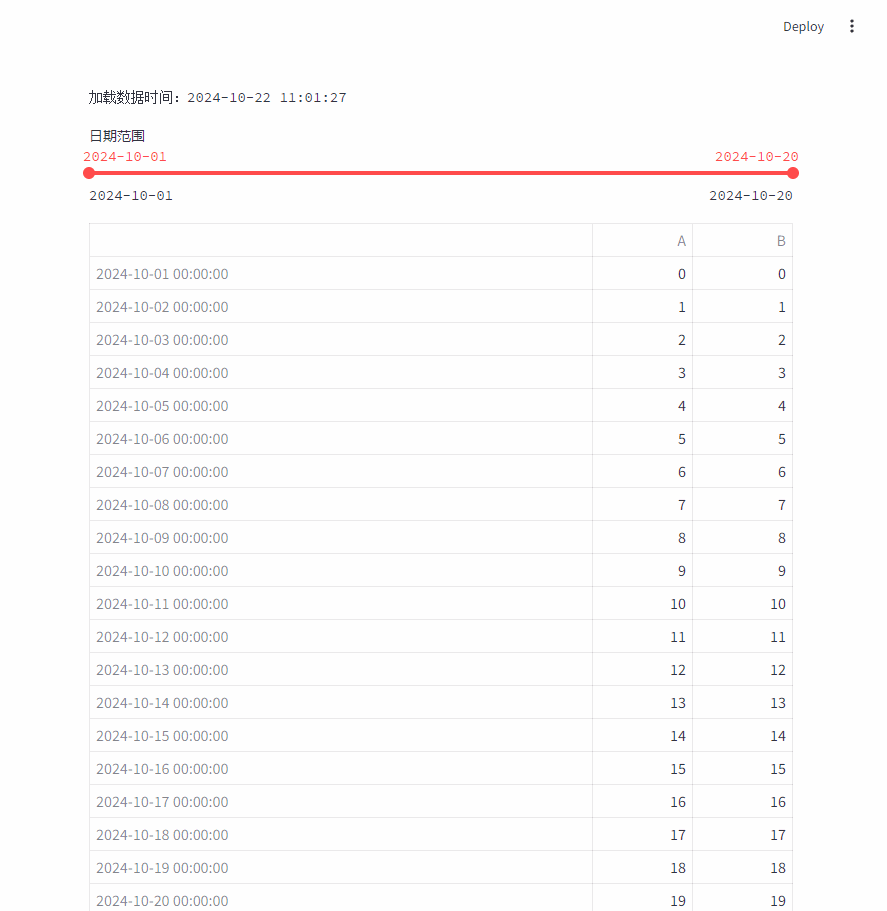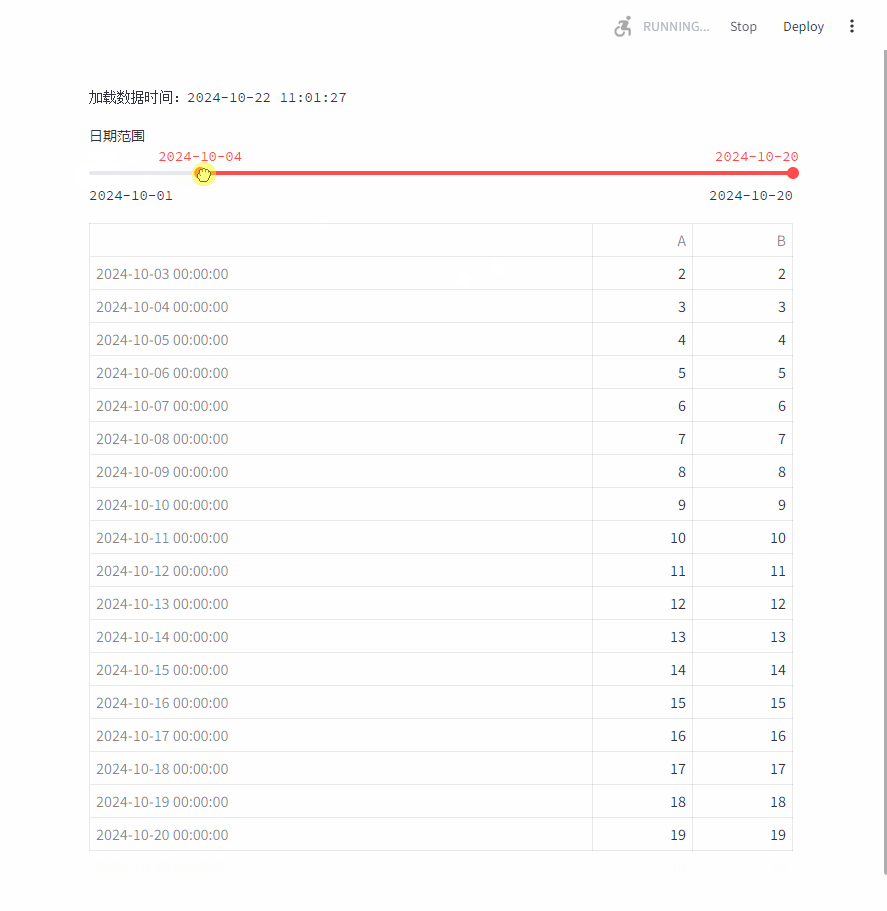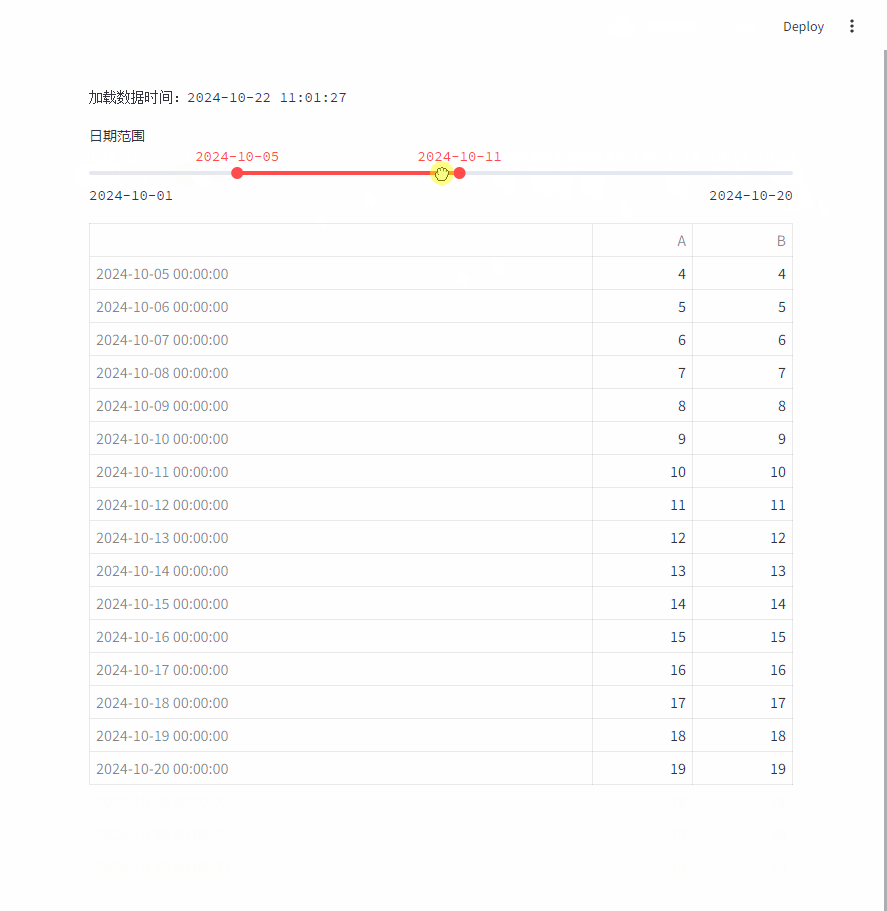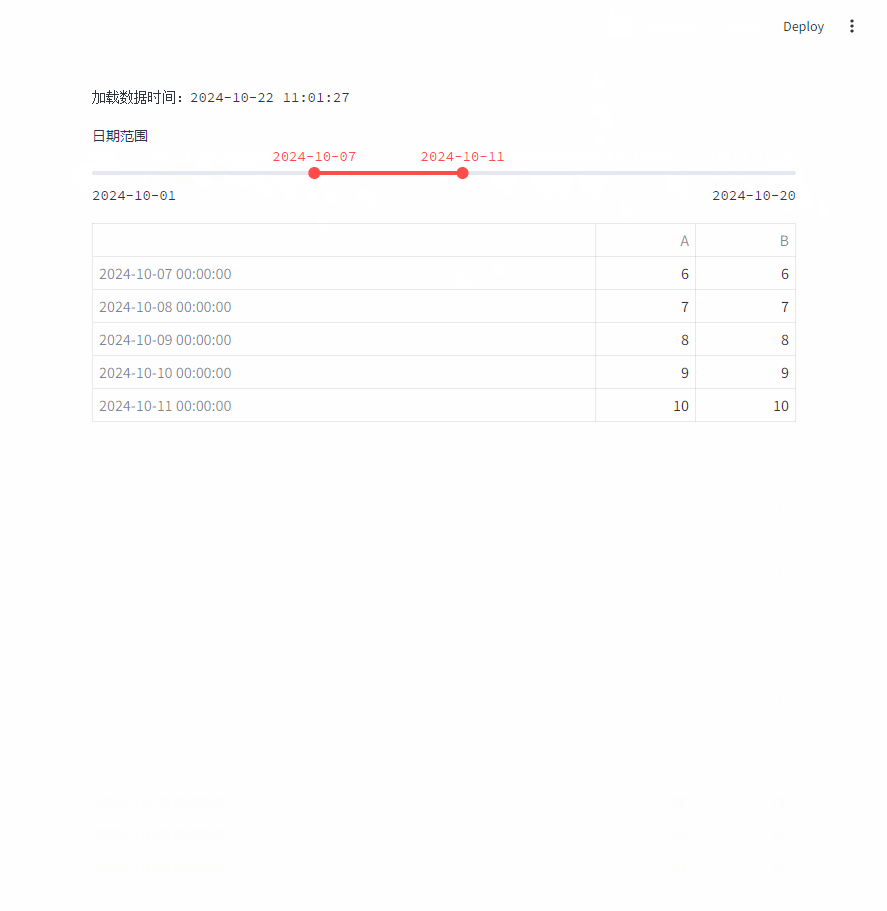
改进之后,移动日期范围时,加载数据时间一直没变,说明没有反复的加载数据。
接下来,用状态(session)来修复上一节中计数无法增加的问题。
if "count" not in st.session_state:
st.session_state.count = 0
st.text(f"Click {st.session_state.count}")
if st.button("ADD"):
st.session_state.count += 1
把计数用的count放入st.session_state中。

st.session_state用于在用户的每次会话中共享变量,确保这些变量在重新运行时仍然可用。
4. 总结
本篇讨论了Streamlit的架构和运行机制,整体来看它的设计简单直接,很好理解。
随后介绍了Streamlit中的缓存cache和状态session,它们在数据处理、存储和持久性方面有着重要作用。
使用时,注意区分缓存cache和状态session的使用场景。
缓存cache主要用于提高应用性能,通过存储和重用之前计算过的结果来避免重复计算。它关注的是数据的处理效率和资源消耗;
而状态session主要用于在用户的会话中共享变量和状态信息。它关注的是用户数据的持久性和在不同事件回调之间的数据一致性。