作业帮基于 DolphinScheduler 的数据开发平台实践
摘要
随着任务数量、任务类型需求不断增长,对我们的数据开发平台提出了更高的要求。本文主要分享我们将调度引擎升级到 Apache DolphinScheduler 的实践经验,以及对数据开发平台的一些思考。
1. 背景
首先介绍下我们的大数据平台架构:

数据计算层承接了全公司的数据开发需求,负责运行各类指标计算任务。
其中批计算任务运行在 UDA 数据开发平台,支持任务全链路的开发场景:开发、调试、环境隔离、运维、监控。这些功能的支持、任务的稳定运行,强依赖底层的调度系统。
原有调度系统是 2015 年 (抑或更早) 自研的,随着任务类型新增、任务数量增多,暴露出诸多问题:

- 稳定性:频繁出现 mysql 连接不释放、锁超时等问题;数据库压力进一步导致调度性能瓶颈,任务无法及时调度。
- 可维护性:核心调度器通过 php 开发,代码古老又经历多次交接,外围模块实现时采用了 go java python 多种语言;再加上功能上也存在单点,维护成本很高。
- 扩展性:业务高速发展,不同任务类型需求越来越多,但是调度作为底层服务在支撑上一直力不从心。
- 可观测性:由于是定时nohup启动任务进程的方式,经常出现任务跑飞了的情况,系统暴露出来的可观测指标几乎为 0。
对调度系统的核心诉求,我觉得分为功能和系统两部分:

功能上,调度系统的核心能力是解决数仓构建的依赖调度问题,因此需要支持多种依赖形式;支持丰富的任务类型,同时可扩展自定义新的任务类型。以及上线管控、历史版本回滚、任务血缘等提高易用性的能力。
系统上,稳定性是第一位的,因此需要具备高可用的能力。同时支持租户隔离、线性扩展、可观测,以方便的对系统进行开发、维护和预警。
历史上我们调研过Airflow、DolphinScheduler 等多种选型,在过去大概一年的时间里,我们将大部分任务从自研调度系统迁移到了 DolphinScheduler 上。
当前调度系统概况如下:
- 任务类型上:HiveSQL、SparkSQL、DorisSQL、PrestoSQL、部分 shell 任务,均通过 DolphinScheduler 调度;遗留部分 shell 任务在原调度系统。
- 任务数量上:DolphinScheduler 天级别调度数万工作流实例,数十万任务实例,高峰时期同时运行 4K+ 工作流实例。迁移完成后,预计工作流实例实例数翻倍。
2. 数据开发平台实践
2.1. 基于 DolphinScheduler 的改造
对 DolphinScheduler 的改造围绕稳定性和易用性展开,对于原有调度系统设计良好的功能,需要兼容以降低任务迁移成本。
我们基于 DolphinScheduler 做了如下升级:

由于 DolphinScheduler 的架构设计比较好,优化基本上可以围绕单点或者复用现有能力展开,而无需对架构进行大刀阔斧的改造。
我们的 SQL 任务都是多个 SQL 组成,但是原生的 SQL 任务只能提交单个。为了确保系统简洁,我没有引入各类 client(hive-client、spark-client 等),而是通过 SQL 解析、连接池管理方式重构等方式,通过 JDBC 协议支持了单任务多 SQL 的提交。
同时充分复用了 DolphinScheduler 对于数据源的设计,赋予数据源更多的属性,比如连接不同的 HiveServer2、Kyubbi、Presto Coordinator 等,对于计算运行在 Yarn 上的任务,单个数据源也只允许使用单个队列。对数据源增加权限控制,这样不同任务就只能使用有权限的集群资源。
我们将资源文件、DQL运行的结果数据,都统一上传到了腾讯云的 COS 对象存储,以确保做到 Worker 真正的无状态。(注:日志上传进行中)
此外包括对负载均衡进行优化、多业务线的租户调度隔离、数据库使用优化等。
2.2. 平滑的大规模迁移
尽管两个调度系统,在功能以及架构上存在巨大差异,但是需要做到平滑的迁移,主要三个原因:
- 原有调度系统服务多年,用户对于功能设计、系统专有字段名词等都已经养成习惯
- 2W+ 工作流的迁移预计耗时较久,涵盖公司众多重要数据流,问题影响程度高
- 用户覆盖了公司众多业务线 (平台、直播课、硬件、图书),问题影响面广
如此大规模的迁移我们做到了对用户几乎无感知,主要依赖新旧调度系统的打通和 DIFF。
接下来介绍下具体是怎么做的。
2.2.1. 新旧调度系统打通
任务迁移阶段,一部分任务运行在新的调度系统上,一部分运行在原有调度系统上,就需要解决两个问题:
- 用户能够查看所有任务实例的运行情况,包括一些内部已经习惯的调度名词 (run_index、result_ftp、log_ftp、csv_result_path 等),这部分信息在 DolphinScheduler 调度里显然没有
- 任务和任务之间有依赖关系,两个系统间调度任务时,也需要查询对方系统调度的任务实例状态,用于判断当前任务依赖是否就绪。
因此,我们在迁移阶段,架构是这样:
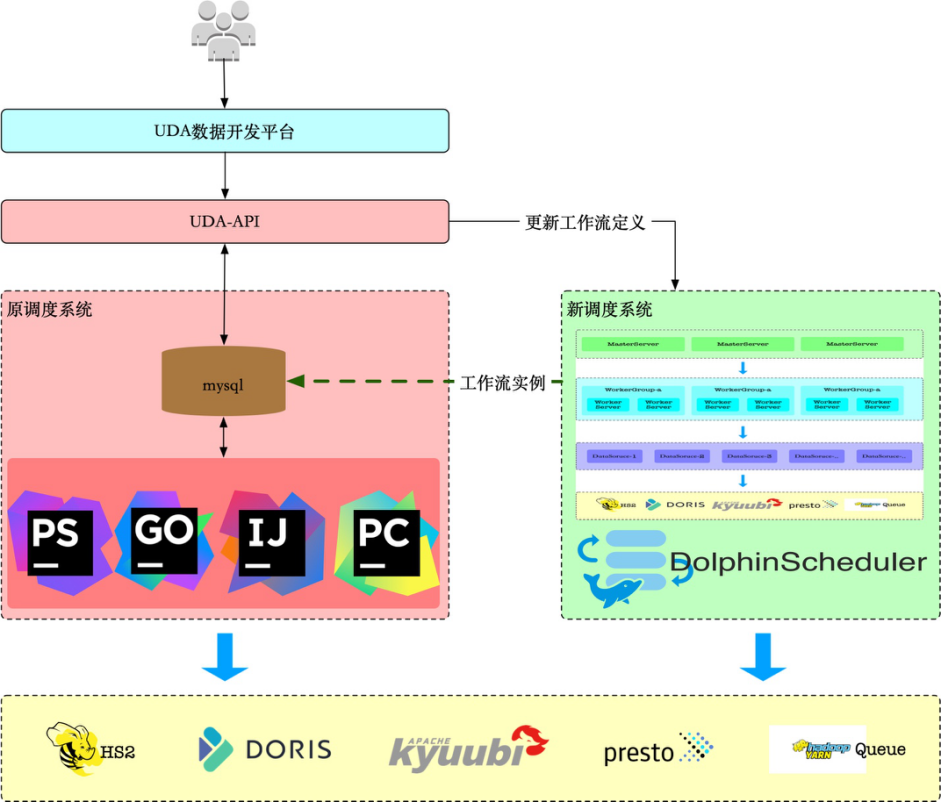
核心设计有两处。
首先任务实例状态统一到原调度系统数据库,对平台而言:
- 查询方式、字段、API 跟之前一致
- 任务更新时,如果该任务已经迁移到了新调度系统,则同时更新 DolphinScheduler 里的工作流定义
因此平台在使用上,对用户没有感知。
其次我们修改了 DolphinScheduler DependentTaskProcessor 的代码,支持查询 DolphinScheduler 及原有调度系统的任务实例状态。这样 DolphinScheduler 调度的任务,就可以自由依赖两个调度系统的任务实例了。
因此在调度能力上,也做到了对用户没有感知。
上述架构,未来在迁移完成后,就可以仅通过 UDA-API + DolphinScheduler 提供完整的调度能力了。
同时,我们在配置依赖的易用性上也做了优化,历史上支持了多种依赖方式:文件依赖、任务依赖、hql依赖、prestosql 依赖等。后两者都需要用户手动配置查询对应表,我们都优化为了表依赖。平台解析用户的 sql,针对读取的表,自动添加对应的依赖。既提高了易用性,也对用户屏蔽了底层具体表存储类型 (Hive/Presto/Iceberg/...) 的细节:

对任务依赖,也支持了全局搜索、偏移量、偏移单位以进一步提高易用性。
2.2.2. 新旧调度系统 DIFF
其次是新旧调度系统的 DIFF.
作为基础平台,服务的业务线众多,再加上 YARN 资源极其紧张,因此我们对调度系统的稳定性要求很高。为了确保迁移顺利,专门基于 DolphinScheduler DryRun 的能力做了一版定制:

所谓镜像任务,是指我们在迁移新调度之前,会先在 DolphinScheduler 镜像一份完全相同的任务,任务同样经过变量替换等操作,只是该任务标记了不真正执行。
这样我们就可以比较两个系统间的 DIFF,主要包括:
- 调度时间是否基本一致:用于验证依赖配置、定时设置等的兼容性
- SQL 是否完全一致:验证变量替换、SQL 屏蔽、队列配置后,真正提交的 SQL 是否完全相同
经过上述空跑观察一段时间,确保无 diff 后,线上任务就真正迁移到新的调度引擎上了。
2.2.3. 系统的可观测性
在有限的时间里,我们做了上述准备,但是仍然不够充分。
系统需要具备良好的可观测性,DolphinScheduler 对外提供了 Prometheus 格式的基础指标。我们增加了一些高优指标,同时转化为 Falcon 格式对接到公司内部的监控系统。
通过监控大盘来查看调度系统的健康状况,并针对不同级别的指标和阈值,配置电话 / 钉钉报警:

可观测性提高后,分析问题的人力成本也得到控制,例如对于这种曲线:
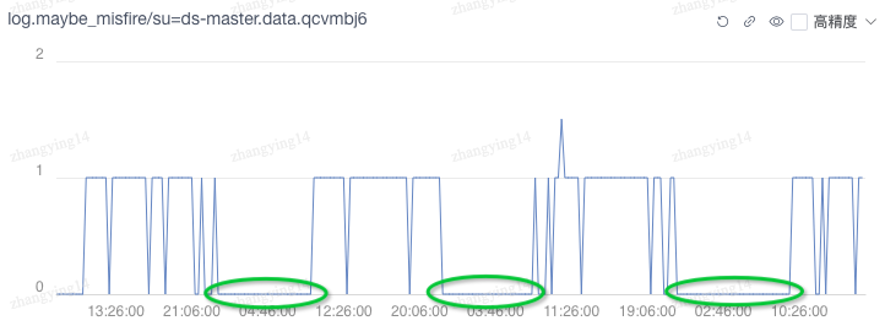
容易观察到在非工作时间曲线值基本为 0,因此就能判断指标异常 (=1) 很可能是用户修改后触发的,相比之前出现问题只能靠猜和逐台机器登录分析日志的方式,通过 metrics 分析能够更早发现和预警问题。
在迁移启动后,对于 misfire、worker 线程池饱和度、连接池饱和度、io-util、overload 等指标,都重点关注和评估,以确保迁移顺利。
2.3. 迁移收益
目前迁移已经进行了一大半,我们针对新旧调度系统的数据库以及调度机资源使用做了对比:
-
数据库:
-
QPS: 10000+ -> 500
-
负载:4.0 -> 1.0
-
-
资源使用降低 65%
我们在迁移过程中,通过 DolphinScheduler 以极低的开发成本支持了 SparkSQL、DorisSQL,以及高版本 PrestoSQL 这类业务新的调度需求。
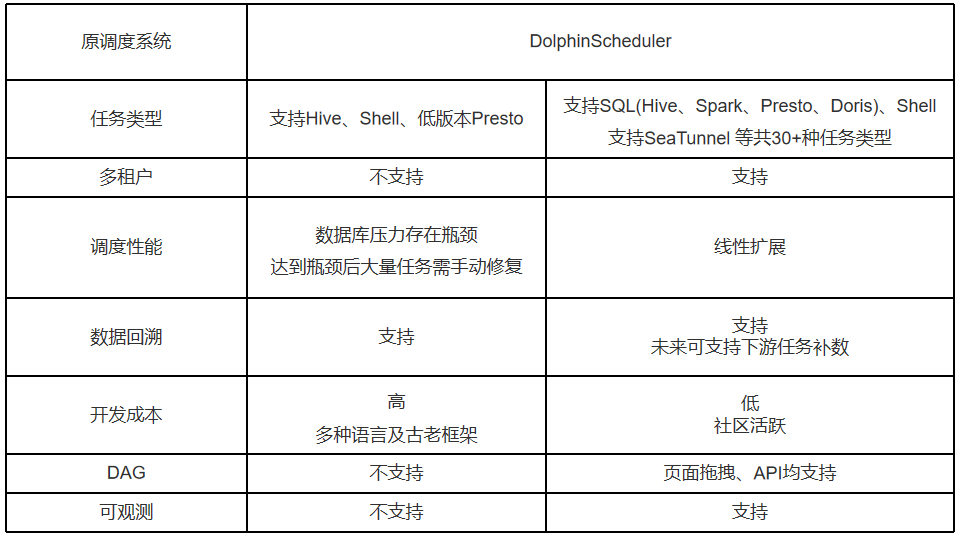
功能上的其他对比:
3. 未来规划
- 例行任务、调试能力全部迁移 DolphinScheduler,沉淀线上操作SOP
- 结合社区的容器化进度,实现模块 K8S 部署。当前 API 模块已经在生产环境使用,Worker、Master 进行中
- 全链路的一键数据回溯能力
- 离线、实时平台打通
本文由 白鲸开源 提供发布支持!