【开源项目】轻量元数据管理解决方案——Marquez

大家好,我是独孤风。
又到了本周的开源项目推荐。最近推荐的元数据管理项目很多,但是很多元数据管理平台的功能复杂难用。
那么有没有轻量一点的元数据管理项目呢?
今天为大家推荐的开源项目,就是一个轻量级的元数据管理工具。虽然轻量,但是元数据的收集、展示、数据血缘等功能都是支持的。
让我们一起来看看吧~

Marquez概述
今天为大家推荐的开源项目名为Marquez。这是WeWork开源的元数据管理工具,可以对元数据进行收集,聚合和可视化。
Marquez提供了开源的元数据服务,用于数据生态系统元数据的收集、聚合和可视化。通过它可以对数据集整体的产生和消费情况进行把控。
并提供数据处理全过程的数据可视化,并可以对数据集的生命周期进行集中管理。

该项目还在蓬勃发展中,目前标星数为1.5K,最新版本为三周前发布的0.43.1。主要开发语言为Java和TS。
Marquez的部署与Java项目类似,只要启动对应的Web端服务和API服务就可以了。
特别强调一下Marquez的血缘API非常的简洁,可以轻松建立数据血缘依赖关系,这可以为数据质量等原因分析提供保证。
可在大数据流动后台回复“Marquez”获取安装包,源代码与学习资料。
功能演示
请参考大数据流动视频号的功能演示:
如何安装?
可以docker快速安装,需要至少满足如下版本。
拉取项目
$ git clone https://github.com/MarquezProject/marquez && cd marquez
可以用下面的命令启动
$ ./docker/up.sh --seed
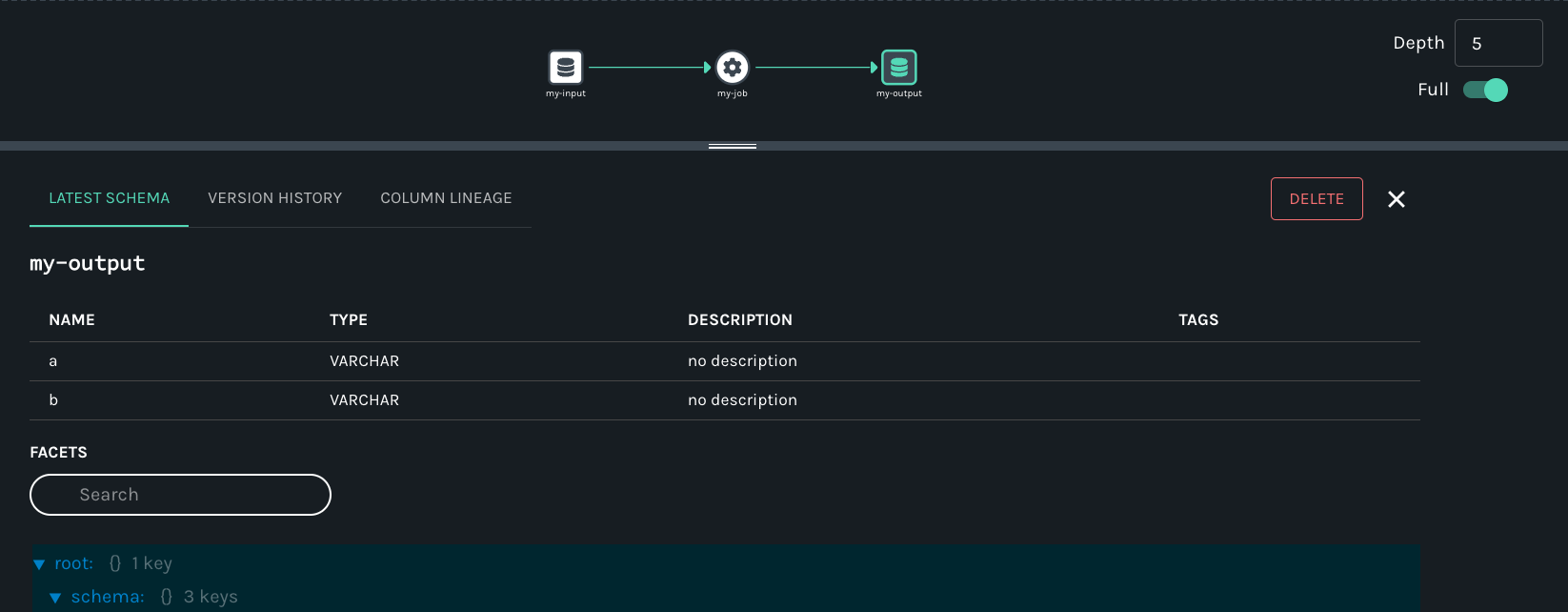
请通过访问http://localhost:3000浏览到 UI 。然后,使用页面右上角的搜索栏搜索该职位etl_delivery_7_days。要查看 的沿袭元数据etl_delivery_7_days,请从下拉列表中单击该作业:

您应该看到作业namespace、name和数据集,input并且output作业运行标记为COMPLETED:

最后,单击 的输出数据public.delivery_7_days集etl_delivery_7_days。您应该看到数据集name、schema和description:

API的使用
项目启动后就可以调用API了。
下面是一个简单的例子,首先我们要启动一个血缘事件。
$ curl -X POST http://localhost:5000/api/v1/lineage \
-i -H 'Content-Type: application/json' \
-d '{
"eventType": "START",
"eventTime": "2020-12-28T19:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "my-namespace",
"name": "my-job"
},
"inputs": [{
"namespace": "my-namespace",
"name": "my-input"
}],
"producer": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client",
"schemaURL": "https://openlineage.io/spec/1-0-5/OpenLineage.json#/definitions/RunEvent"
}'
随后完成该任务。
$ curl -X POST http://localhost:5000/api/v1/lineage \
-i -H 'Content-Type: application/json' \
-d '{
"eventType": "COMPLETE",
"eventTime": "2020-12-28T20:52:00.001+10:00",
"run": {
"runId": "d46e465b-d358-4d32-83d4-df660ff614dd"
},
"job": {
"namespace": "my-namespace",
"name": "my-job"
},
"outputs": [{
"namespace": "my-namespace",
"name": "my-output",
"facets": {
"schema": {
"_producer": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client",
"_schemaURL": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/spec/OpenLineage.json#/definitions/SchemaDatasetFacet",
"fields": [
{ "name": "a", "type": "VARCHAR"},
{ "name": "b", "type": "VARCHAR"}
]
}
}
}],
"producer": "https://github.com/OpenLineage/OpenLineage/blob/v1-0-0/client",
"schemaURL": "https://openlineage.io/spec/1-0-5/OpenLineage.json#/definitions/RunEvent"
}'
注意运行正常的话我们应该接到201 CREATED的响应。
在页面搜索,将得到血缘展示。
这只是Marquez的基本用法。
Marquez提供元数据采集的一个标准方案,目前支持Spark,Airflow的表级别和列级别的数据血缘收集。
而Flink暂时只支持表级别的血缘收集。
相信Marquez未来会支持越来越多的数据源,让我们一起期待一下吧~