DNS解析与优化
这篇笔记总结自网课👉DNS解析和优化【渡一教育】
DNS用于将域名转换成IP地址。
特点:
-
DNS解析过程耗费时间长;
-
DNS有本地缓存。
DNS解析完成得到IP地址,这个IP地址会存储到本地设备,后续再读这个域名会直接返回本地缓存的IP地址。
用户浏览网页中的DNS解析流程
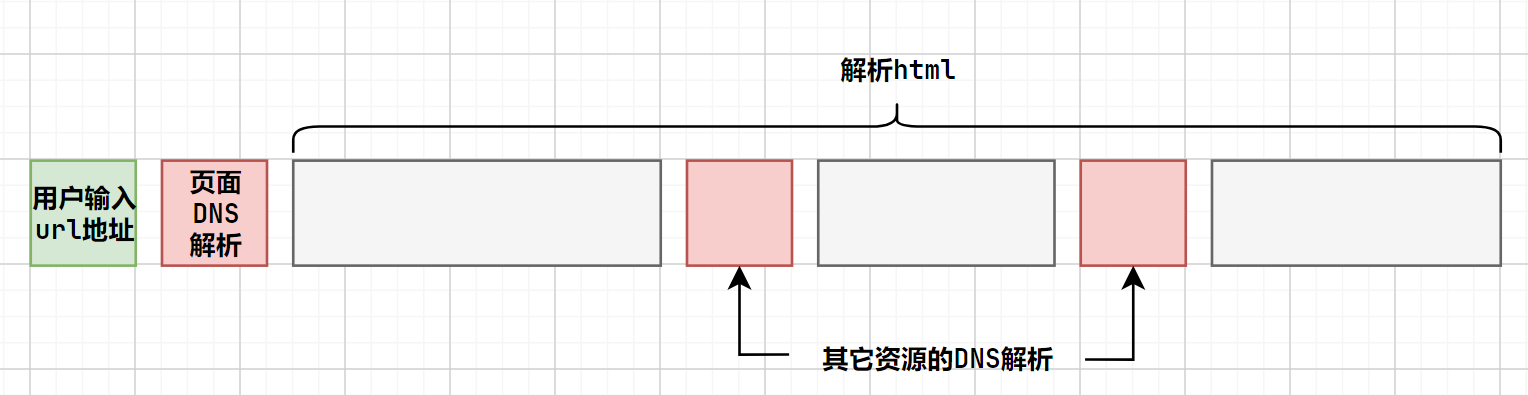
- 首先用户输入url地址,然后需要对网站的域名进行DNS解析,这个解析过程无法优化。
- 而在站点中可能还用到了很多其它域名下的资源,在解析
html的过程也会触发DNS解析。
例如:<img>标签的src引用了其它域名站点的图片,或者<script>标签引入了外部的脚本文件,或者<link>标签引入了其它域名站点的css文件。
当解析html的过程中遇到了站外的
script标签且本地无缓存时,解析html的进度会暂停,直到script标签引入并执行再继续。
随着网站规模越来越大,这种外部资源的引入可能越来越多。而多次的DNS解析会耗费许多时间。
优化思路:源代码中使用的外部域名是已知的,可以把它们都提取到html的头部,提前异步解析。
提前异步解析DNS

使用link标签的dns-prefetch
<html>
<head>
<link rel="dns-prefetch" href="https://www.a.com"/>
<link rel="dns-prefetch" href="https://www.b.com"/>
<link rel="dns-prefetch" href="https://www.c.com"/>
...
</head>
<body>
...
</body>
</html>
但是,考虑到我们平时的开发环境有以下特点:
- 使用框架开发,不同的域名分散在不同的组件;
- 多人开发,不知道其他人有没有引入外部域名;
- 一般不会手动编辑打包后的
index.html文件。
我们需要较为自动化的脚本协助完成整个项目中的外部域名统计,并写入到最终打包的index.html头部。
脚本编写
目的:读取dist文件夹中的.css,.js文件,统计外部域名并写入到index.html头部。
创建脚本:项目根目录下创建文件夹/scripts,创建文件dns-prefetch.js;
脚本内容:
const fs = require('fs');
const path = require('path');
const { parse } = require('node-html-parse');
const { glob } = require('glob');
const urlRegex = require('url-regex');
// 获取外部链接的正则表达式
const urlPattern = /(https?:\/\/[^/]*)/i;
const urls = new Set();
// 遍历dist目录中的所有HTML, JS, CSS文件
async function searchDomain(){
const files = await glob('dist/**/*.{html,css,js}');
for(const file of files){
const source = fs.readFileSync(file, 'utf-8');
const matches = source.match(urlRegex({strict: true}));
if(matches){
matches.forEach((url)=>{
const match = url.match(urlPattern);
if(match && match[1]){
urls.add(match[1]);
}
});
}
}
}
async function insertLinks(){
const files = await glob('dist/**/*.html');
const links = [...urls]
.map((url) => `<link rel="dns-prefetch" href="${url}"/>`)
.join('\n');
for(const file of files){
const html = fs.readFileSync(file, 'utf-8');
const root = parse(html);
const head = root.querySelector('head');
head.insertAdjacentHTML('afterbegin', links);
fs.writeFileSync(file, root.toString());
}
}
async function main(){
await searchDomain();
// 在<head>标签中添加预取链接
await insertLinks();
}
main();
glob用于使用正则表达式将匹配的文件都找到;fs用于读取选中的文件;urlRegex用于分析出文件中的URL地址;node-html-parse用于在脱离浏览器的环境下,将读取到的html代码文本转换为节点。
当脚本编写完成之后,将其添加到打包代码的工具流程中。
在package.json文件中:
{
"scripts": {
"build": "vite build && node ./scripts/dns-prefetch.js"
}
}
热门相关:佣兵之王都市行 1号婚令:早安,大总裁! 北宋闲王 唐朝贵公子 黑暗血时代