基于大型语言模型爬虫项目Crawl4AI介绍

Crawl4AI是一款专为大型语言模型(LLMs)和AI应用设计的开源网页爬虫和数据提取工具。最近挺火的开源AI网络爬虫工具:Crawl4AI 可以直接用于大语言模型和AI应用。性能超快,还能输出适合大语言模型的格式,比如JSON、清理过的HTML和markdown。它还支持同时爬取多个网址,能提取所有媒体标签(图片、音频、视频),以及所有内外部链接。可以自定义用户代理,还能给网页截图,甚至在爬取之前执行自定义JavaScript。
一、概述
Crawl4AI旨在简化网页数据的抓取和提取过程,为数据科学家、研究人员、开发人员和AI应用开发者提供高效、便捷的数据获取解决方案。它针对LLM的训练和应用场景进行了优化,能够高效地从各类网站中提取高质量数据,为LLM提供丰富且优质的训练素材。
二、核心优势
- 开源免费:Crawl4AI是一款完全免费且开源的工具,用户可以自由地使用、修改和分发。
- LLM友好:支持LLM友好的输出格式,如JSON、清洁的HTML和Markdown,方便用户进行后续的数据处理和模型训练。
- 多URL支持:同时支持爬取多个URL,提高数据抓取的效率。
- 高级提取策略:提供多种高级提取策略,如余弦聚类、LLM等,帮助用户更精确地提取所需数据。
- 丰富功能:支持提取并返回所有媒体标签(图片、音频和视频),提取所有外部和内部链接,从页面提取元数据等。
- 灵活配置:提供自定义钩子用于认证、头部和爬取前的页面修改,用户代理自定义,截取页面屏幕截图,执行多个自定义JavaScript脚本等功能,满足用户多样化的需求。
三、应用场景
Crawl4AI适用于需要从网页中快速提取大量数据的场景,如:
- 数据科学研究:为数据科学家提供丰富的数据源,支持其进行数据分析、挖掘和建模。
- AI模型训练:为AI应用开发者提供高质量的训练数据,助力其提升模型的性能和准确性。
- 网络数据挖掘:帮助研究人员从大量网页中挖掘有价值的信息,支持其进行学术研究。
四、使用指南
Crawl4AI提供了详细的官方文档和安装指南,用户可以通过以下方式获取和使用:
- 访问官方网站:前往Crawl4AI官方网站或官方文档网站,了解工具的详细介绍和使用方法。
- 安装工具:用户可以通过pip安装Crawl4AI,也可以使用Docker容器来简化设置。在安装过程中,如果遇到与Playwright相关的错误,可以尝试手动安装Playwright。
- 编写爬虫代码:根据官方文档提供的示例代码和API文档,编写符合自己需求的爬虫代码。
- 运行爬虫:执行编写好的爬虫代码,开始从网页中提取数据。
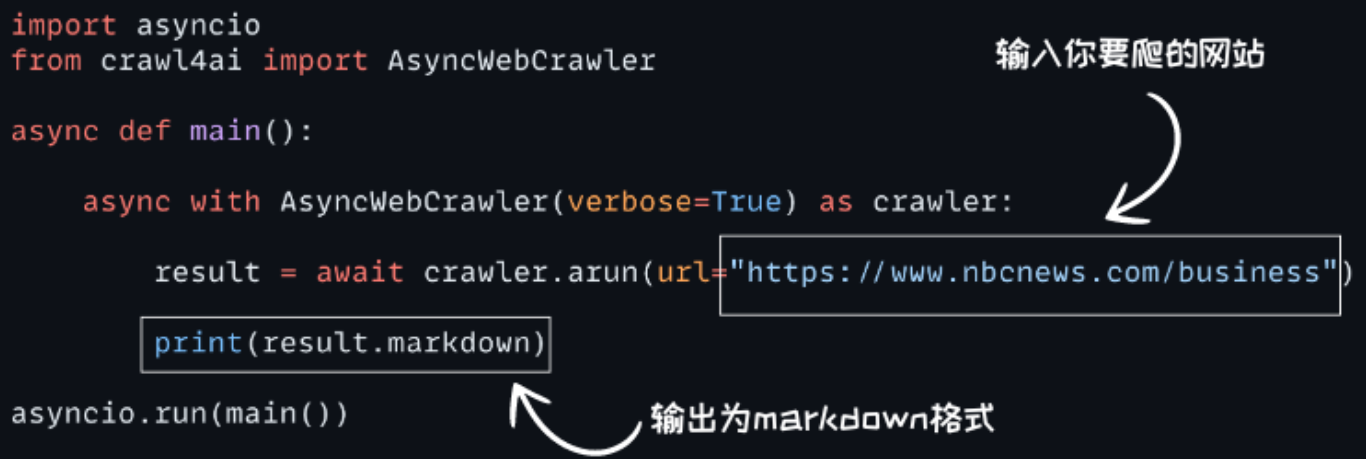
五、步骤示例
第 1 步:安装和设置
pip install “crawl4ai @ git+https://github.com/unclecode/crawl4ai.git"
第 2 步:数据提取
from crawl4ai import WebCrawler
# Create an instance of WebCrawler
crawler = WebCrawler()
# Warm up the crawler (load necessary models)
crawler.warmup()
# Run the crawler on a URL
result = crawler.run(url="https://openai.com/api/pricing/")
# Print the extracted content
print(result.markdown)
第 3 步:使用 LLM
使用 LLM (Large Language Model) 定义提取策略,并将提取的数据转换为结构化格式:
import os
from crawl4ai import WebCrawler
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from pydantic import BaseModel, Fieldclass OpenAIModelFee(BaseModel):
model_name: str = Field(..., description="Name of the OpenAI model.")
input_fee: str = Field(..., description="Fee for input token for the OpenAI model.")
output_fee: str = Field(..., description="Fee for output token ßfor the OpenAI model.")url = 'https://openai.com/api/pricing/'
crawler = WebCrawler()
crawler.warmup()result = crawler.run(
url=url,
word_count_threshold=1,
extraction_strategy= LLMExtractionStrategy(
provider= "openai/gpt-4o", api_token = os.getenv('OPENAI_API_KEY'),
schema=OpenAIModelFee.schema(),
extraction_type="schema",
instruction="""From the crawled content, extract all mentioned model names along with their fees for input and output tokens.
Do not miss any models in the entire content. One extracted model JSON format should look like this:
{"model_name": "GPT-4", "input_fee": "US$10.00 / 1M tokens", "output_fee": "US$30.00 / 1M tokens"}."""
),
bypass_cache=True,
)print(result.extracted_content)
第 4 步:与 AI 智能体集成
将 Crawl 与 Praison CrewAI 代理集成以实现高效的数据处理:
pip install praisonai
创建一个工具文件 (tools.py) 以封装 Crawl 工具:
# tools.py
import os
from crawl4ai import WebCrawler
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from pydantic import BaseModel, Field
from praisonai_tools import BaseToolclass ModelFee(BaseModel):
llm_model_name: str = Field(..., description="Name of the model.")
input_fee: str = Field(..., description="Fee for input token for the model.")
output_fee: str = Field(..., description="Fee for output token for the model.")class ModelFeeTool(BaseTool):
name: str = "ModelFeeTool"
description: str = "Extracts model fees for input and output tokens from the given pricing page."def _run(self, url: str):
crawler = WebCrawler()
crawler.warmup()result = crawler.run(
url=url,
word_count_threshold=1,
extraction_strategy= LLMExtractionStrategy(
provider="openai/gpt-4o",
api_token=os.getenv('OPENAI_API_KEY'),
schema=ModelFee.schema(),
extraction_type="schema",
instruction="""From the crawled content, extract all mentioned model names along with their fees for input and output tokens.
Do not miss any models in the entire content. One extracted model JSON format should look like this:
{"model_name": "GPT-4", "input_fee": "US$10.00 / 1M tokens", "output_fee": "US$30.00 / 1M tokens"}."""
),
bypass_cache=True,
)
return result.extracted_contentif __name__ == "__main__":
# Test the ModelFeeTool
tool = ModelFeeTool()
url = "https://www.openai.com/pricing"
result = tool.run(url)
print(result)
将 AI 代理配置为使用 Crawl 工具进行 Web 抓取和数据提取:
framework: crewai
topic: extract model pricing from websites
roles:
web_scraper:
backstory: An expert in web scraping with a deep understanding of extracting structured
data from online sources. https://openai.com/api/pricing/ https://www.anthropic.com/pricing https://cohere.com/pricing
goal: Gather model pricing data from various websites
role: Web Scraper
tasks:
scrape_model_pricing:
description: Scrape model pricing information from the provided list of websites.
expected_output: Raw HTML or JSON containing model pricing data.
tools:
- 'ModelFeeTool'
data_cleaner:
backstory: Specialist in data cleaning, ensuring that all collected data is accurate
and properly formatted.
goal: Clean and organize the scraped pricing data
role: Data Cleaner
tasks:
clean_pricing_data:
description: Process the raw scraped data to remove any duplicates and inconsistencies,
and convert it into a structured format.
expected_output: Cleaned and organized JSON or CSV file with model pricing
data.
tools:
- ''
data_analyzer:
backstory: Data analysis expert focused on deriving actionable insights from structured
data.
goal: Analyze the cleaned pricing data to extract insights
role: Data Analyzer
tasks:
analyze_pricing_data:
description: Analyze the cleaned data to extract trends, patterns, and insights
on model pricing.
expected_output: Detailed report summarizing model pricing trends and insights.
tools:
- ''
dependencies: []
Crawl 是一个强大的工具,它使 AI 代理能够更高效、更准确地执行 Web 爬虫和数据提取任务。
今天先到这儿,希望对云原生,技术领导力, 企业管理,系统架构设计与评估,团队管理, 项目管理, 产品管理,信息安全,团队建设 有参考作用 , 您可能感兴趣的文章:
构建创业公司突击小团队
国际化环境下系统架构演化
微服务架构设计
视频直播平台的系统架构演化
微服务与Docker介绍
Docker与CI持续集成/CD
互联网电商购物车架构演变案例
互联网业务场景下消息队列架构
互联网高效研发团队管理演进之一
消息系统架构设计演进
互联网电商搜索架构演化之一
企业信息化与软件工程的迷思
企业项目化管理介绍
软件项目成功之要素
人际沟通风格介绍一
精益IT组织与分享式领导
学习型组织与企业
企业创新文化与等级观念
组织目标与个人目标
初创公司人才招聘与管理
人才公司环境与企业文化
企业文化、团队文化与知识共享
高效能的团队建设
项目管理沟通计划
构建高效的研发与自动化运维
某大型电商云平台实践
互联网数据库架构设计思路
IT基础架构规划方案一(网络系统规划)
餐饮行业解决方案之客户分析流程
餐饮行业解决方案之采购战略制定与实施流程
餐饮行业解决方案之业务设计流程
供应链需求调研CheckList
企业应用之性能实时度量系统演变
如有想了解更多软件设计与架构, 系统IT,企业信息化, 团队管理 资讯,请关注我的微信订阅号:

作者:Petter Liu
出处:http://www.cnblogs.com/wintersun/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
该文章也同时发布在我的独立博客中-Petter Liu Blog。