一下午连续故障两次,谁把我们接口堵死了?!
唉。。。
大家好,我是程序员鱼皮。又来跟着鱼皮学习线上事故的处理经验了喔!

事故现场
周一下午,我们的

看到这些我真的非常难受,我们团队的开发同学也第一时间展开了排查。
简单看了下前端向后端发的请求,发现所有的请求都一直阻塞,直到超时。直接请求后端服务器的接口也是一样的,等了很久都没有正常返回数据。最关键的是,所有接口都阻塞住了,哪怕只是请求个健康检查接口(后端直接返回 "ok",不查询数据库),也无法正常响应。
我们的后端服务是部署在容器托管平台的,正常情况下如果资源(比如 CPU 和内存)占用超过一定比例,会自动扩容节点来让服务承载更多的并发请求,但为什么这次没有扩容呢?
其实有经验的朋友应该已经能猜到接口堵死的原因了,下面我带大家揭开谜团。
事故排查
根据上面的现象,推测大概率是接口层出了问题,而不涉及到业务和数据库等依赖资源。由于我们的后端使用的是 Spring Boot + 内嵌的 Tomcat 服务器,而 Tomcat 同时处理请求的最大线程数是固定的(默认是 200),所以当同时处理的请求过多,并且每个请求一直没有处理完成时,所有的线程都在繁忙,没有办法处理新的请求,就会导致新的请求排队等待处理,从而造成了接口堵死(迟迟无法响应)的现象。
这里我用一个简单的程序来模拟下接口堵死和排查过程。
首先写一个非常简单的测试接口,在返回内容前加一个 Thread.sleep,模拟耗时的操作,让处理请求的线程进入较长的等待。

然后更改下 Tomcat 的最大线程数为 5,便于我们模拟线程数不够的情况:

启动项目,在 Thread.sleep 打断点,然后连续请求 6 次接口。
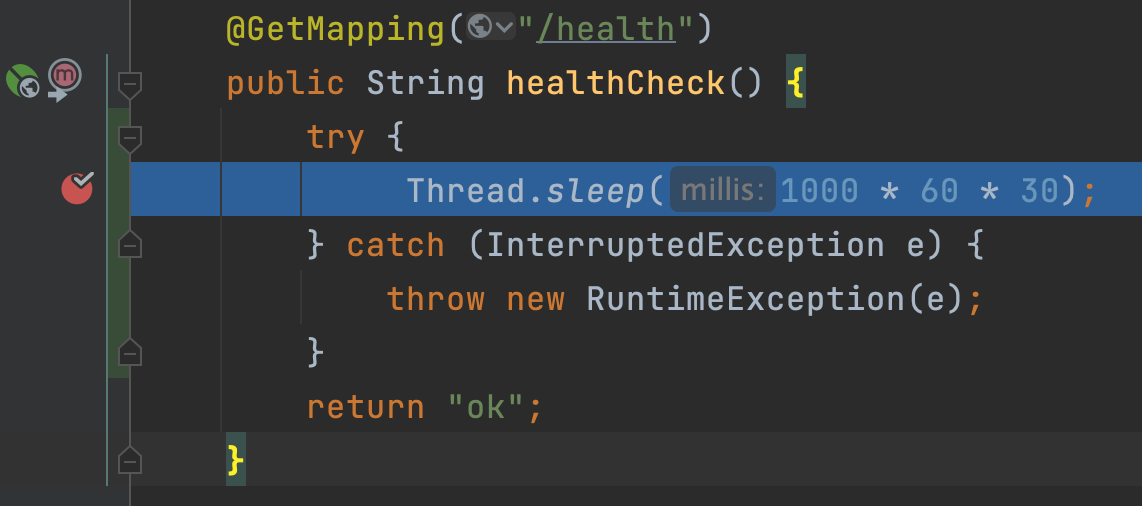
应该只有 5 次请求会进入断点,最后一次请求会一直转圈卡住,没有线程来处理。这样我们就还原了事故现场。

但以上只是推测,实际线上项目中,怎么去排查确认 Tomcat 线程都阻塞了呢?又怎么确认是哪个接口或代码让 Tomcat 线程阻塞等待了呢?
其实很简单,首先用 jps -l 命令查看 Java 后端服务对应的进程 PID:
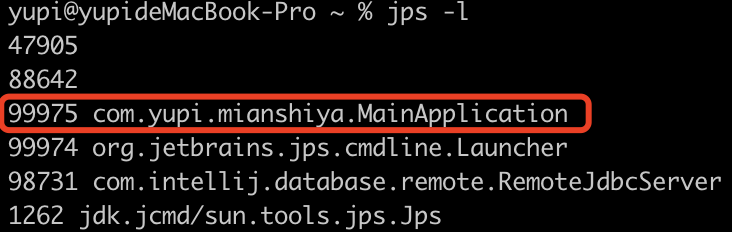
然后使用 jstack 命令生成线程快照,并保存为文件。具体命令如下:
jstack <进程PID> > thread_dump.txt
打开线程快照文件,所有线程的状态一目了然,搜索 http-nio 就能看到 Tomcat 的请求处理线程,果然所有的请求处理线程状态都是 TIMED_WAITING ,表示线程正在等待另一个线程执行特定的动作,但是有一个指定的等待时间。而且能直接看到请求是阻塞在了哪个代码位置。

利用这个方法,我们也很快定位到了编程导航接口堵死的原因,是发生在一个从数据库查询用户的方法。由于我们昨天下午执行了短信群发召回老用户的动作,导致大量用户同时访问编程导航并执行这个方法。由于涉及的数据库查询操作执行较慢,每个请求都需要等待数据库查询出结果后,才能响应数据,下一个请求才能再进来查询数据库,就导致大量 Tomcat 请求处理线程阻塞在等待数据库查询上,再进一步导致新的请求要排队等待处理。
真相大白了!
如何解决?
其实我们这次遇到的问题就是典型的 “线上连接池爆满问题”,面试的时候也是经常问的。前面讲了怎么排查此类问题,那如何解决这类问题呢?
首先遇到连接池爆满的情况,先保护现场,比如按照鱼皮上面的操作 dump 线程信息,然后赶紧重启服务或启动新的实例,让用户先能正常使用。再进行排查分析和优化。
如何优化线上连接池爆满问题?首先肯定还是要优化造成请求阻塞的代码。比如数据库查询慢,我们就通过添加索引来提升查询速度。
还可以增加数据库连接池的大小,在 Spring Boot 中,默认使用 HikariCP 作为数据源连接池,而 HikariCP 的 maximumPoolSize(最大连接池大小)默认值只有 10,显然是不足以应对高并发场景的。可以把下面的配置数值调大一点:
spring
由于后端请求操作不止有查询数据库,所以 Tomcat 线程池的最大线程数和最小空闲线程数也可以按需调整,比如下列配置:
# 设置 Tomcat 最大线程数
server.tomcat.threads.max=300
# 设置 Tomcat 最小空闲线程数
server.tomcat.threads.min-spare=20
适当调大 Tomcat 的最大线程数,可以增加并发请求的处理能力。适当调大 Tomcat 的最小空闲线程数,可以确保在并发高峰时刻,Tomcat 能迅速响应新的请求,而不需要重新创建线程。
其实我们大多数情况下,线上服务器(容器)的内存利用率是不高的,所以可以根据实际的资源和并发情况,适当地改一改配置。记得多做做测试,因为过高的线程数可能导致线程调度开销增加,反而降低性能。
现实
好吧,以上只是我遇到此类问题的解决方案。但现实可能没那么理想,其实慢 SQL 这个问题我们在上一次故障时就已经定位到,并且在群内同步了。结果你猜怎么着,我们团队的开发同学发了一堆监控的截图,但是没有一个人真正去解决了这个问题,这才导致了故障在多日之后重新上演!

一旦发现了问题,就必须要想到尽可能长久支持的解决方案,要不然这监控不是白做了?
为什么这次事故持续了这么久呢?也是因为我团队的开发同学缺少线上问题处理的经验,在那一通分析,结果忘了恢复服务,过了半个小时用户还是无法访问,直到我去提醒。。。

所以这个时候就知道平时背的八股文有多重要了吧?Tomcat 的连接器配置和性能优化也是一道经典的八股文,也是我们
