《An End-to-end Model for Entity-level Relation Extraction using Multi-instance Learning》阅读笔记
预备知识:
1.什么是MIL?
多示例学习(MIL)是一种机器学习的方法,它的特点是每个训练数据不是一个单独的实例,而是一个包含多个实例的集合(称为包)。每个包有一个标签,但是包中的实例没有标签。MIL的目的是根据包的标签来学习实例的特征和分类规则,或者根据实例的特征来预测包的标签。MIL的应用场景包括药物活性预测、图像分类、文本分类、关系抽取等。MIL的挑战在于如何处理实例之间的相关性、标签的不确定性和数据的不平衡性。MIL的常用算法有基于贝叶斯、KNN、决策树、规则归纳、神经网络等的方法,以及基于注意力机制、自编码器、变分推断等的方法。
2.什么是基于跨度(span)的命名实体识别方法?
跨度分类是一种常用的嵌套命名实体识别方法。为了识别全跨度命名实体,基于跨度的模型必须枚举和验证句子中所有可能的实体跨度,这会导致计算复杂性和数据不平衡等严重问题。
3.什么是基于跨度的联合实体关系抽取?
在基于跨度的联合实体关系抽取方法中,对句子中的词跨度进行枚举,并在一个模型中共享跨度的表示嵌入,以完成NER和RE的任务。
4.什么是前馈神经网(feed-forward neural network,FFNN)?
前馈神经网络是人工神经网络中最简单的一种。在这个网络中,信息只向一个方向移动——从输入节点,通过隐藏节点(如果有的话),到达输出节点。网络中没有循环。
5.CNN和FFNN有什么区别?
卷积神经网络是一种结构化的神经网络,其中前几层是稀疏连接的,以便处理信息(通常是视觉信息)。前馈网络被定义为不包含任何循环。如果它有循环,它就是一个循环神经网络。
6.什么是重叠的提及(overlapping mentions)?
重叠的提及 (overlapping mentions) 是指在文档中,一个实体可能有多个不同的表达方式,这些表达方式被称为提及 (mentions)。例如,下面这句话中,“Barack Obama”和“he”都是指代同一个实体,因此它们是重叠的提及:Barack Obama was the 44th president of the United States. He served two terms from 2009 to 2017.
重叠的提及给文档级关系抽取带来了一些挑战,因为需要识别出文档中所有的提及,并将它们与对应的实体进行匹配。同时,还需要考虑不同提及之间的指代关系,以及它们在不同句子中的语义信息。
本文提出了一种从文档中抽取实体级关系的联合模型,与其他方法不同的是,该模型不需要在提及级别上进行注释,而是直接在实体级别上运行。为了实现这一目标,本文采用了一种多任务方法,首先利用共同参考解析来识别文档中的实体,其次通过多实例学习来抽取实体之间的关系,最后通过多层次表示来融合全局实体和局部提及的信息。在DocRED数据集上的实验结果表明,该模型在实体级关系提取任务上达到了最先进的性能。本文还报告了第一个实体级端到端关系提取结果,为未来的研究提供了一个新的基准。最后,本文的分析结果显示,该模型与特定任务学习相比,具有更高的效率和泛化能力,这主要归功于参数和训练步骤的共享。
1 Introduction
随着神经网络的发展,关系抽取领域出现了两个重要的转变:
-
从句子级层面的抽取转向了从长文本段落(文档级)的抽取,这样可以利用更多的上下文信息,提高关系抽取的准确性和鲁棒性。
-
从使用单独的模型解决实体提及检测和关系提取转向了使用联合模型解决这些任务,这样可以避免错误传播,提高模型的效率和泛化能力。
本文提出了JEREX(Joint Entity-Level Relation Extractor),作为一种新颖的联合信息提取方法,它能够在文档级别上抽取实体和关系。与传统方法不同,JEREX无需对每个实体提及进行标注,而是将文档中的实体聚类为实体集群,并使用多实例学习(MIL)的方法预测集群之间的关系。JEREX还能够同时在提及检测、共指消解、实体分类和关系提取等任务上进行联合训练(见图1)。此外,本文还提出了一种新的关系提取表示,它能够结合实体集群的全局信息和实体提及的局部信息,从而提高关系抽取的性能。为了验证JEREX,本文在DocRED数据集上进行了实体级关系提取的实验,该数据集是一个大规模的文档级关系提取数据集,包含了多个领域和多种关系类型。实验结果表明,本文的方法在关系提取的准确率和召回率上均优于最近的基于图传播或预训练的方法,达到了当前的最佳水平。本文还在DocRED数据集上进行了端到端关系提取的实验,这是首次在该数据集上进行这样的实验,为未来的研究提供了一个基准。通过消融研究,本文证明了(1)全局和局部表示的结合对于关系提取是有效的,(2)联合训练的方法与单独训练每个任务的方法相比没有显著差异。

2 Related Work
Document-level Relation Extraction
最近在文档级关系抽取方面的工作聚焦于从文档中直接学习实体(同一实体的不同提及)之间的关系,而无需对每个提及对进行关系标注。为了获取跨句子的相关信息,多实例学习被成功地应用于这个任务。在多实例学习中,目标是给实体对(作为包)分配关系标签,每个实体对包含多个提及对(作为实例)。Verga等人(2018)利用多实例学习来检测生物文本中的特定领域关系。他们计算两个实体集合中每个提及对的关系分数,并使用平滑的最大池化操作来聚合这些分数。Christopoulou等人(2019)和Sahu等人(2019)通过构建文档级图来模拟全局交互,从而改进了Verga等人(2018)的方法。虽然上述模型都是针对具有少量关系类型的非常特定的领域,但最近发布的DocRED数据集(Yao等人,2019)使得在丰富的关系类型集合(96种)上进行通用领域的研究成为可能。Yao等人(2019)提供了几种基线模型,例如基于CNN、LSTM或Transformer的模型,它们都是基于全局的、提及平均的实体表示进行关系抽取的。Wang等人(2019)使用两步过程,首先识别相关实体,然后对它们进行关系分类。Tang等人(2020)采用了一个分层推理网络,将实体表示与对单个句子的注意力相结合,形成最终的关系判断。Nan等人(2020)应用了一个图神经网络(Kipf和Welling,2017),构建了一个由提及、实体和元依赖节点组成的文档级图。目前的最先进的模型是Ye等人(2020)提出的CorefRoBERTa模型,它是一个RoBERTa(Liu等人,2019)的变体,它是在检测共指短语上进行预训练的。他们表明,用CorefRoBERTa替换RoBERTa可以提高在DocRED上的性能。
所有这些模型都有一个共同的假设,就是实体和它们的提及都是已知的。与之相反,本文的方法同时抽取提及,将它们聚类为实体,并对实体对进行关系分类。
Joint Entity Mention and Relation Extraction
以前的联合模型主要关注句子中提及级别的关系抽取。这些模型通常使用BIO(或BILOU)标记来识别提及,并将它们配对进行关系分类。但是,这些模型无法处理重叠的实体提及之间的关系。最近,基于跨度的方法(Lee等人, 2017)在这个任务上取得了成功(Luan等人, 2018; Eberts和Ulges, 2020)。这些方法通过枚举句子中的所有词跨度,可以自然地处理重叠的提及。Sanh等人 (2019)训练了一个多任务模型,同时进行命名实体识别、共指消解和关系抽取。Luan等人 (2019)通过引入共指消解作为辅助任务,实现了通过共指链的信息传递。然而,这些模型仍然依赖于提及级别的标注,只能检测句内的提及关系。与之不同的是,本文的模型显式地构建了共指提及的簇,并利用多实例推理的方法,检测长文档中的复杂实体级别的关系。
3 Approach
JEREX是一个能够从多句文档中自动识别、聚类和分类实体及其关系的端到端的关系提取模型。它由四个任务特定的组件组成,它们共享相同的编码器和提及表示,并联合训练。JEREX首先对输入文档进行标记,产生n个BPE (Sennrich等人, 2016)标记序列。然后,JEREX使用预训练的transformer网络BERT (Devlin等人, 2019)来获取每个BPE标记的上下文化嵌入
3.1 Model Architecture
本文使用一个多层次的模型:
-
通过基于跨度的方法定位文档中的所有实体提及。
-
通过共指消解将检测到的提及聚类为实体。
-
通过对局部提及表示的融合(实体分类)对每个实体簇的类型(如人或公司)进行分类。
-
通过对提及对的推理提取实体之间的关系。
完整的模型架构图2所示。

(a) Entity Mention Localization
本文的模型对文档中的所有子序列(或跨度spans)进行搜索,以找出实体提及。与基于BIO/BILOU的方法不同,该方法可以检测出重叠的提及。给定一个候选跨度 






其中

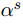


(b) Coreference Resolution
在输入文档中,可能有多个指代同一实体的提及,例如“Elizabeth II.”和“the Queen”。为了在实体级别上提取关系,需要通过指代消解,将这些局部提及分组到文档级别的实体簇中。本文使用一个简单的提及对模型(Soon等人, 2001),来判断检测到的实体提及对

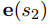




与跨度分类类似,本文使用 sigmoid 激活函数进行二元分类,得到两个提及的相似度得分:

其中





(c) Entity Classification
接下来,需要给每个实体指定一个类型,比如位置或人物等。为此,本文首先对一个实体簇中的所有提及

然后,利用这个实体表示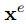

将概率最高的类型赋给实体。
(d) Relation Classification
最后一个组件的任务是给每一对实体分配一种关系类型。在这个过程中,需要考虑两个方面:一是关系的方向性,即确定哪个实体是关系的头,哪个实体是关系的尾;二是关系的多样性,即同一个实体对在文档中可能存在多种不同的关系。本文假设有一组预定义的关系类型

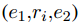




Global Relation Classifier (GRC)
全局分类器利用实体对 




接着,将这个表示输入到一个两层的




Multi-instance Relation Classifier (MRC)
与全局分类器(GRC)相比,多实例关系分类器在提及层面上进行操作。由于只有实体级别的标签可用,本文将实体提及对视为潜在变量,并通过对这些提及对的融合来估计关系。对于任意一对实体簇

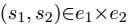

此外,由于本文期望相邻的提及是关系的更强指示器,本文添加了两个提及之间的距离

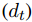


这个提及对表示被一个单层的前馈神经网络映射到原始的词嵌入大小(768):

这些聚焦的表示然后通过最大池化进行组合:

与 GRC 类似,本文将

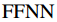




3.2 Training
本文提出了一个有监督的多任务学习框架,它可以同时处理四个子任务:实体提及定位、共指消解、实体分类和关系分类。每个训练文档都有这四个子任务的真实标签。本文的目标是最小化所有四个子任务的联合损失函数:

其中,






-
实体提及定位:使用文档中所有的真实实体提及
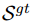


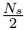
-
共指消解:在所有真实实体簇


-
实体分类:在所有真实实体簇上训练实体分类器。由于实体分类器在推理时只接收假定的实体簇,因此不需要采样负样本。
-
关系分类:使用真实实体簇之间的关系作为正样本,从


本文通过对所有样本求平均来计算每个子任务的损失,在训练过程中,学习子任务特定层的参数和元嵌入,并且还对BERT进行了微调。
4 Experiments
本文使用DocRED数据集来评估JEREX模型。DocRED是目前最具多样性的关系抽取数据集,涵盖了6种实体类型和96种关系类型。它包含了超过5000篇文档,每篇文档都由多个句子构成。Yao等人 (2019)指出,DocRED需要运用多种推理能力,如逻辑推理或常识推理,才能推断出关系。
以往的工作只是利用DocRED进行关系抽取(相当于本文的关系分类器部分),并且假设实体已经给定(例如Wang等人, 2019; Nan等人, 2020)。而DocRED则对提及、实体和实体级关系进行了全面的标注,使其适用于端到端的系统。因此,本文不仅将JEREX作为关系分类器(与现有方法进行比较),还将其作为联合模型(作为未来联合实体级关系抽取研究的基准)。
尽管之前的联合模型只专注于提及级别的关系(例如Gupta等人,2016; Bekoulis等人,2018; Chi等人,2019),但本文将严格的评估标准扩展到实体级别:只有当提及的跨度与真实的提及跨度完全一致时,才认为提及是正确的。只有当实体簇与真实的簇完全一致,并且相应的提及跨度也正确时,才认为实体簇是正确的。同样,只有当簇和实体类型与真实的实体完全一致时,才认为实体是正确的。最后,只有当关系的参数实体和关系类型与真实的关系完全一致时,才认为关系是正确的。本文分别对每个子任务计算精确率、召回率和微平均F1值,并报告微平均得分。
Dataset split
原始的DocRED数据集分为训练集(3,053篇文档)、开发集(1,000篇文档)和测试集(1,000篇文档)。但测试集的关系标签不公开,评估需要在Codalab上提交结果。为了对端到端的系统进行评估,本文把训练集和开发集合并,重新划分为训练集(3,008篇文档)、开发集(300篇文档)和测试集(700篇文档)。这里剔除了45篇文档,因为它们的实体标注有误,同一个实体的不同提及被标为不同的类型。表2展示了本文端到端划分的统计数据,同时本文把这个划分作为未来研究的基准发布。

Hyperparameters
本文使用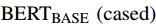







4.1 End-to-End Relation Extraction



JEREX在DocRED上进行了训练和评估。本文对每个实验重复了5次,并报告了平均结果。为了研究联合训练的效果,本文尝试了两种方法:(a)所有四个子任务在一个单一的模型中联合训练;(b)构建了一个流水线系统,分别训练每个子任务,而不共享文档编码器。
表1展示了联合方法(左)和流水线方法(右)的结果。如第3节所述,每个子任务都基于前一个子任务的结果进行推理。本文发现关系分类任务的性能下降最大,说明检测文档级关系是一项困难的任务。此外,基于多实例的关系分类器(MRC)比全局关系分类器(GRC)的F1分数高出约2.4%。本文认为,通过多实例学习融合局部证据,有助于模型关注文档中的重要部分,并减轻长文档中的噪声影响。而且,本文发现多实例选择提供了良好的可解释性,通常选择最相关的实例(见图3的例子)。总的来说,本文发现联合训练和流水线系统的性能相近。
这一发现也得到了表4中的结果的支持,其中本文独立地评估了四个子任务,即每个子任务从层次结构中的前一步接收真实样本(例如,用于共指消解的真实提及)。同样,本文发现联合模型和流水线模型之间的性能差异可以忽略不计。这表明,没有必要为每个子任务构建单独的模型,这将导致由于多次昂贵的BERT传递而产生的训练和推理开销。相反,一个单一的神经模型能够联合学习文档级关系抽取所需的所有子任务,从而简化了训练、推理和维护的过程。
4.2 Relation Extraction

JEREX在DocRED关系抽取任务上与最新技术进行了比较。在这个任务中,实体簇是已知的。本文在DocRED原始数据集的划分上训练和测试了关系分类组件。由于测试集的标签是不公开的,本文通过CodaLab提交了开发集上的最佳结果,以获得测试集的评分。表3展示了当前最先进模型的先前报告的结果。本文的全局分类器(GRC)与(Yao等人, 2019)的基线类似。但是,本文用最大池化代替了提及跨度的平均,并且也用最大池化将提及聚合成实体表示,这样就显著提高了基线的性能。另外,使用多实例分类器(MRC)可以进一步提升约4.5%的性能。在这里,本文的模型也超越了基于图注意力网络(Nan等人, 2020)或专门预训练(Ye等人, 2020)的复杂方法,在DocRED的关系抽取任务上达到了新的最高水平。
4.3 Ablation Studies

为了评估本文提出的多实例关系分类器的改进效果,本文进行了几个消融实验:分别去掉了全局实体表示
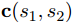
5 Conclusions
本文提出了一种新颖的多任务模型JEREX,它能够端到端地进行关系抽取。不同于以往的系统,JEREX能够同时定位实体提及并消解指代,从而在实体级别上抽取实体类型和关系。本文首次给出了实体级别、端到端关系抽取的结果,为未来的工作提供了参考标准。此外,本文在DocRED关系抽取任务上达到了最佳的性能,通过利用全局实体表示和局部上下文来增强多实例推理,优于几种更复杂的方法。本文还展示了使用单个模型同时训练所有子任务,而不是采用流水线方式,可以获得近似的效果,从而避免了训练多个模型的开销,提高了推理速度。然而,本文仍然面临一个挑战,就是如何减少根据实体类型推断出的假阳性关系,这些关系在文档中并没有明确表达。探索解决这个问题的方法似乎是一个有趣的未来研究方向。