为什么访问同一个网址却返回不同的内容
哈喽大家好,我是咸鱼。今天给大家分享一个关于 HTTP 有趣的现象
链接:https://csvbase.com/meripaterson/stock-exchanges
我们用浏览器访问这个链接,可以看到下面的网页

但如果我们使用 curl 命令去访问这个链接呢?

可以看到返回的是一个 csv 文件
我们用 wget 命令下载下来看看

可以看到 text/csv 字段,表示下载了一个 csv 格式的文件
奇怪,同样的 url ,为什么浏览器返回的内容跟 curl、wget 命令返回的内容却不一样
内容协商
当 HTTP 客户端去发送响应给 HTTP 服务端的时候,响应里面会包含响应头(headers)
我们来看下 Google浏览器发送的响应头
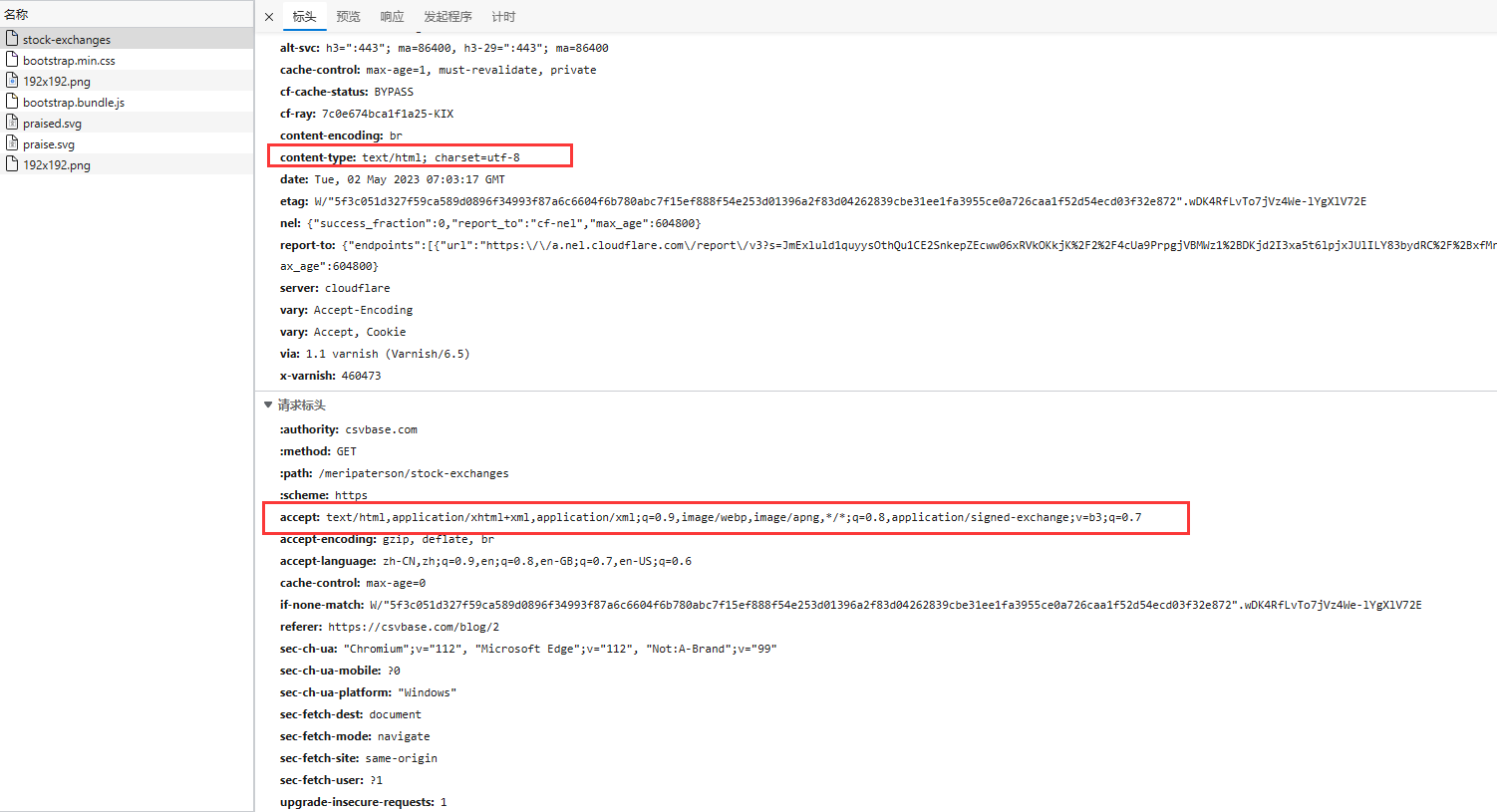
我们着重注意一下响应头里的 accept 字段

这个 accept 报头是一个无序列表,它告诉了 HTTP 服务端应该返回什么媒体类型(又称内容类型或文件格式)的内容给我
以上面 Google 浏览器的 accept 报头为例:这段 accept 报头表示该请求中浏览器可接受的媒体类型(或文件格式)的偏好。从左到右,各类型的优先级逐渐降低
text/html: 浏览器首选的媒体类型,即 HTML 文本。application/xhtml+xml: 次选的媒体类型,即 XHTML 文本。application/xml;q=0.9: 服务器可以发送的 XML 类型的文本,但是客户端更愿意接收前面的两种媒体类型,所以权重为 0.9。image/avif,image/webp,image/apng: 浏览器能够接受的图片类型,优先级逐渐降低。如果服务器返回多种可接受的图片类型,则浏览器将选择优先级最高的那个。*/*;q=0.8: 如果服务器无法以以上任何一种类型响应,则浏览器愿意接受任何类型,但是这个类型的优先级最低,只有 0.8。application/signed-exchange;v=b3;q=0.7: 该媒体类型是用于实现 Web 页面“前进”和“后退”功能的标准。客户端更愿意接受前面提到的其他媒体类型,所以该类型的权重为 0.7。
所以说我们用 Google 浏览器去访问这个 url (csvbase.com)时,会跟 HTTP 服务端去协商:你应该返回什么类型的内容给我,优先是 text/html
而 curl 命令或者 wget 命令去访问请求这个 url 时,默认情况下发送的请求头中的 Accept 字段的值是 */*,表示支持接受所有类型的响应
而这个网站 csvbase 默认格式是 csv,所以说当 curl 命令或者 wget 命令去访问请求这个 url 时,得到的是一个 csv 格式返回内容
这就是 HTTP 协议中的内容协商(content negotiation)
HTTP内容协商是指客户端和服务器端协商出最适合的响应数据格式、语言等内容的过
HTTP中的内容协商机制,可以确保客户端和服务器端发送和接收的内容格式是一致的,从而提高通信的效率和可靠性
HTTP内容协商通常有三种类型:
- 基于请求头的内容协商(Header-based content negotiation)
- 基于URL的内容协商(URL-based content negotiation)
- 基于实体的内容协商(Entity-based content negotiation)
基于请求头的内容协商是指客户端在请求头中指定自己可以接受的内容类型(MIME类型),服务器根据客户端的请求头中所指定的信息,选择最合适的响应内容类型进行响应
常用的请求头字段是 Accept 和 Accept-Language。服务器端根据 Accept 字段的内容,选择最匹配的响应类型进行响应
如果客户端所能接受的响应类型都不能满足服务器端的响应类型,则会返回一个 406 Not Acceptable 的错误状态码
那有小伙伴可能会想:我用 curl 命令或者 wget 命令不想得到一个 csv 格式的响应,我想 HTTP 服务端返回其他类型的响应,这时候该怎么办
我们可以手动修改请求头来告诉 HTTP 服务端它可以接受的媒体类型(即文件格式)的偏好

参考文章: