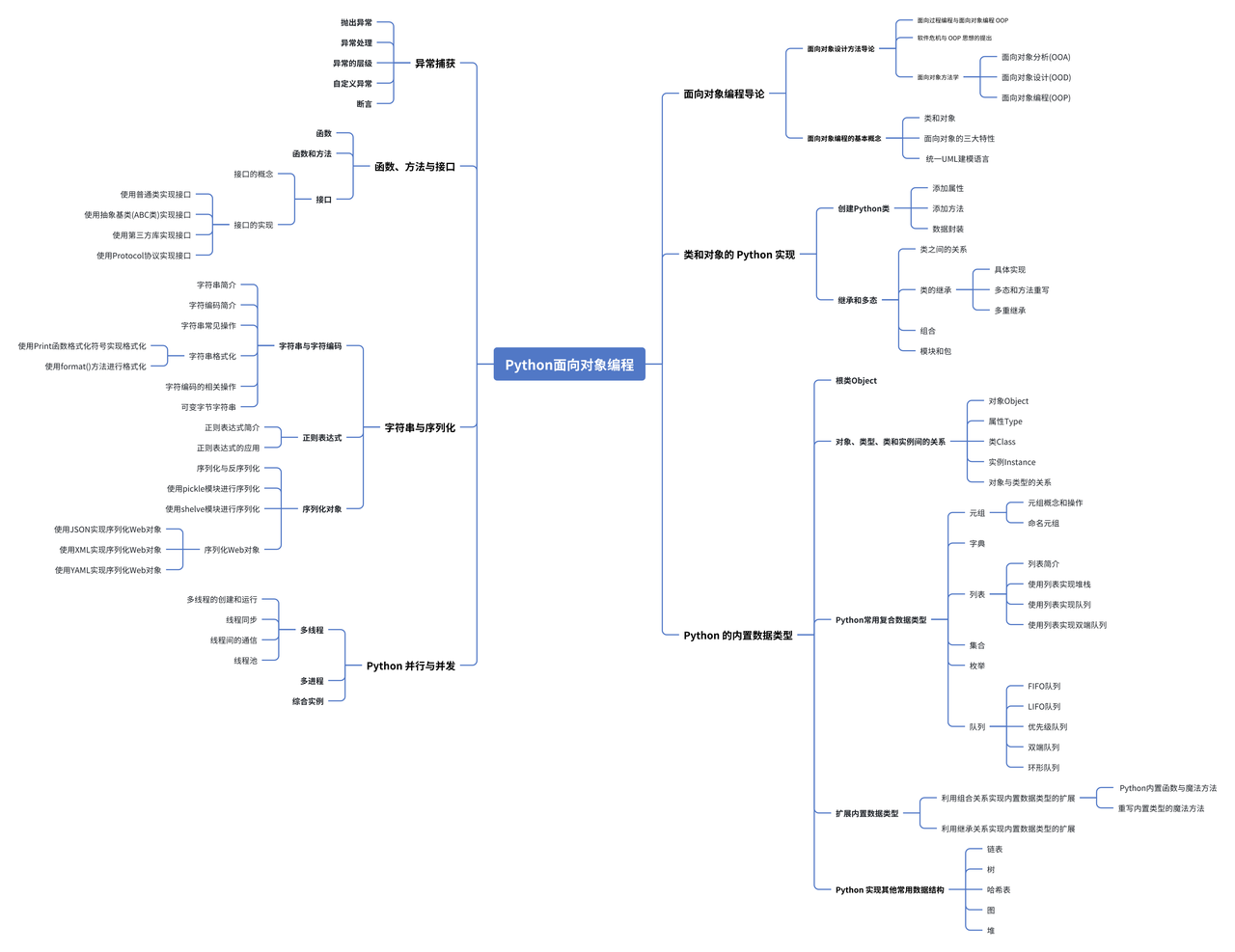
全网最适合入门的面向对象编程教程:57 Python字符串与序列化-序列化与反序列化
全网最适合入门的面向对象编程教程:57 Python 字符串与序列化-序列化与反序列化
摘要:
Python 序列化与反序列化是将 Python 对象转换为字节流(序列化)以便存储或传输,和将字节流转换回对象(反序列化)的过程,pickle 模块和 shelve 模块是 Python 内置的序列化工具,以将 Python 对象序列化为二进制数据并存储或传输。
原文链接:
往期推荐:
全网最适合入门的面向对象编程教程:00 面向对象设计方法导论
全网最适合入门的面向对象编程教程:01 面向对象编程的基本概念
全网最适合入门的面向对象编程教程:02 类和对象的 Python 实现-使用 Python 创建类
全网最适合入门的面向对象编程教程:03 类和对象的 Python 实现-为自定义类添加属性
全网最适合入门的面向对象编程教程:04 类和对象的Python实现-为自定义类添加方法
全网最适合入门的面向对象编程教程:05 类和对象的Python实现-PyCharm代码标签
全网最适合入门的面向对象编程教程:06 类和对象的Python实现-自定义类的数据封装
全网最适合入门的面向对象编程教程:07 类和对象的Python实现-类型注解
全网最适合入门的面向对象编程教程:08 类和对象的Python实现-@property装饰器
全网最适合入门的面向对象编程教程:09 类和对象的Python实现-类之间的关系
全网最适合入门的面向对象编程教程:10 类和对象的Python实现-类的继承和里氏替换原则
全网最适合入门的面向对象编程教程:11 类和对象的Python实现-子类调用父类方法
全网最适合入门的面向对象编程教程:12 类和对象的Python实现-Python使用logging模块输出程序运行日志
全网最适合入门的面向对象编程教程:13 类和对象的Python实现-可视化阅读代码神器Sourcetrail的安装使用
全网最适合入门的面向对象编程教程:全网最适合入门的面向对象编程教程:14 类和对象的Python实现-类的静态方法和类方法
全网最适合入门的面向对象编程教程:15 类和对象的 Python 实现-__slots__魔法方法
全网最适合入门的面向对象编程教程:16 类和对象的Python实现-多态、方法重写与开闭原则
全网最适合入门的面向对象编程教程:17 类和对象的Python实现-鸭子类型与“file-like object“
全网最适合入门的面向对象编程教程:18 类和对象的Python实现-多重继承与PyQtGraph串口数据绘制曲线图
全网最适合入门的面向对象编程教程:19 类和对象的 Python 实现-使用 PyCharm 自动生成文件注释和函数注释
全网最适合入门的面向对象编程教程:20 类和对象的Python实现-组合关系的实现与CSV文件保存
全网最适合入门的面向对象编程教程:21 类和对象的Python实现-多文件的组织:模块module和包package
全网最适合入门的面向对象编程教程:22 类和对象的Python实现-异常和语法错误
全网最适合入门的面向对象编程教程:23 类和对象的Python实现-抛出异常
全网最适合入门的面向对象编程教程:24 类和对象的Python实现-异常的捕获与处理
全网最适合入门的面向对象编程教程:25 类和对象的Python实现-Python判断输入数据类型
全网最适合入门的面向对象编程教程:26 类和对象的Python实现-上下文管理器和with语句
全网最适合入门的面向对象编程教程:27 类和对象的Python实现-Python中异常层级与自定义异常类的实现
全网最适合入门的面向对象编程教程:28 类和对象的Python实现-Python编程原则、哲学和规范大汇总
全网最适合入门的面向对象编程教程:29 类和对象的Python实现-断言与防御性编程和help函数的使用
全网最适合入门的面向对象编程教程:30 Python的内置数据类型-object根类
全网最适合入门的面向对象编程教程:31 Python的内置数据类型-对象Object和类型Type
全网最适合入门的面向对象编程教程:32 Python的内置数据类型-类Class和实例Instance
全网最适合入门的面向对象编程教程:33 Python的内置数据类型-对象Object和类型Type的关系
全网最适合入门的面向对象编程教程:34 Python的内置数据类型-Python常用复合数据类型:元组和命名元组
全网最适合入门的面向对象编程教程:35 Python的内置数据类型-文档字符串和__doc__属性
全网最适合入门的面向对象编程教程:36 Python的内置数据类型-字典
全网最适合入门的面向对象编程教程:37 Python常用复合数据类型-列表和列表推导式
全网最适合入门的面向对象编程教程:38 Python常用复合数据类型-使用列表实现堆栈、队列和双端队列
全网最适合入门的面向对象编程教程:39 Python常用复合数据类型-集合
全网最适合入门的面向对象编程教程:40 Python常用复合数据类型-枚举和enum模块的使用
全网最适合入门的面向对象编程教程:41 Python常用复合数据类型-队列(FIFO、LIFO、优先级队列、双端队列和环形队列)
全网最适合入门的面向对象编程教程:42 Python常用复合数据类型-collections容器数据类型
全网最适合入门的面向对象编程教程:43 Python常用复合数据类型-扩展内置数据类型
全网最适合入门的面向对象编程教程:44 Python内置函数与魔法方法-重写内置类型的魔法方法
全网最适合入门的面向对象编程教程:45 Python实现常见数据结构-链表、树、哈希表、图和堆
全网最适合入门的面向对象编程教程:46 Python函数方法与接口-函数与事件驱动框架
全网最适合入门的面向对象编程教程:47 Python函数方法与接口-回调函数Callback
全网最适合入门的面向对象编程教程:48 Python函数方法与接口-位置参数、默认参数、可变参数和关键字参数
全网最适合入门的面向对象编程教程:49 Python函数方法与接口-函数与方法的区别和lamda匿名函数
全网最适合入门的面向对象编程教程:50 Python函数方法与接口-接口和抽象基类
全网最适合入门的面向对象编程教程:51 Python函数方法与接口-使用Zope实现接口
全网最适合入门的面向对象编程教程:52 Python函数方法与接口-Protocol协议与接口
全网最适合入门的面向对象编程教程:53 Python字符串与序列化-字符串与字符编码
全网最适合入门的面向对象编程教程:54 Python字符串与序列化-字符串格式化与format方法
全网最适合入门的面向对象编程教程:55 Python字符串与序列化-字节序列类型和可变字节字符串
全网最适合入门的面向对象编程教程:56 Python字符串与序列化-正则表达式和re模块应用
更多精彩内容可看:
给你的 Python 加加速:一文速通 Python 并行计算
一个MicroPython的开源项目集锦:awesome-micropython,包含各个方面的Micropython工具库
SenseCraft 部署模型到Grove Vision AI V2图像处理模块
文档和代码获取:
可访问如下链接进行对文档下载:
https://github.com/leezisheng/Doc
本文档主要介绍如何使用 Python 进行面向对象编程,需要读者对 Python 语法和单片机开发具有基本了解。相比其他讲解 Python 面向对象编程的博客或书籍而言,本文档更加详细、侧重于嵌入式上位机应用,以上位机和下位机的常见串口数据收发、数据处理、动态图绘制等为应用实例,同时使用 Sourcetrail 代码软件对代码进行可视化阅读便于读者理解。
相关示例代码获取链接如下:https://github.com/leezisheng/Python-OOP-Demo
正文
序列化与反序列化
我们已经明确,在程序执行的过程中,所有的变量均存储在内存中。举例来说,我们定义了一个名为 d 的字典,其中包含 name、age、grade 和 score 等键值对。在程序运行过程中,我们可以随时更改这些变量的值,例如将 name 的值从'Larry'修改为'david'。然而,一旦程序执行完毕,这些变量所占用的内存将被操作系统全部回收。值得注意的是,如果我们在程序运行过程中对变量进行了修改,但未将这些修改后的数据持久化至磁盘,那么在下一次重新运行程序时,这些变量将重新初始化为原始状态,即 name 的值仍为'Larry'。因此,为了确保数据的连续性和一致性,我们需要在适当的时候将关键数据写入磁盘,以便在程序重启后能够恢复到正确的状态。
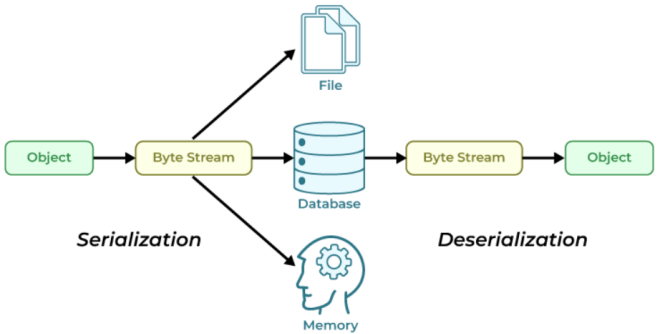
另一方面,存储在内存够中的对象由于编程语言、网络环境等等因素,很难在网络中进行传输交互。由此,就诞生了一种机制,可以实现内存中的对象与方便持久化在磁盘中或在网络中进行交互的数据格式(字符串、字节等)之间的相互转换。这种机制就叫序列化与反序列化:
- 序列化:将内存中的不可持久化和传输对象转换为可方便持久化和传输对象的过程,在 Python 中叫 pickling,在其他语言中也被称之为 serialization,marshalling,flattening 等等,都是一个意思,序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上;
- 反序列化:将可持久化和传输对象转换为不可持久化和传输对象的过程,即把变量内容从序列化的对象重新读到内存里,也称为 unpickling。
在 Python 中常见序列化对象的方式有 pickle、shelve、JSON 三种方式:json 模块常用于编写 web 接口,将 Python 数据转换为通用的 json 格式传递给其它系统或客户端;也可以用于将 Python 数据保存到本地文件中;pickle 模块实现了用于序列化和反序列化 Python 对象结构的二进制协议;shelve 模块可以看做是 pickle 模块的升级版,因为 shelve 使用的就是 pickle 的序列化协议,但是 shelve 比 pickle 提供的操作方式更加简单、方便。
使用 pickle 模块进行序列化
Python 的 pickle 模块通过一种面向对象的方式直接将对象存储为特殊存储格式。将对象(它所持有的一切对象都作为属性存在)转换为字节序列是很有必要的,可以在我们需要的时候进行存储或传输。


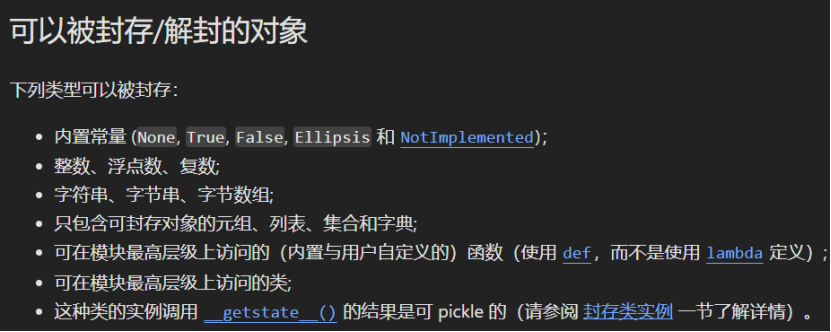
pickle 具有如下方法,用于存储和载入数据:
| 方法 | 作用 | 操作对象 |
|---|---|---|
| ** **** **dump | dump 方法接受一个对象和一个类文件对象并将序列化字节写入文件。文件对象必须拥有一个 write 方法,且这一方法必须知道如何处理 bytes 参数(这样以文本输出模式打开的文件就无法使用了)。所谓类文件对象(file-like object),简单说就是类似文件对象的对象,至少要具备 read ()和 write ()两个方法。 | 类文件(file-like)对象 |
| load | load 方法文件对象中读取序列化的对象。这里的文件对象必须拥有合适的 read 和 readline 方法,当然它们都必须返回 bytes 类型。pickle 模块将会从这些字节中载入对象,而 load 方法将会返回完全重建的对象。 | |
| dumps | 将封存以后的对象作为 bytes 类型直接返回,而不是将其写入到文件。 | bytes 对象 |
| loads | 重建并返回一个对象的封存表示形式 data 的对象层级结构。data 必须为 bytes-like object。 |

要序列化某个包含层次结构的对象,只需调用 dumps() 函数即可。同样,要反序列化数据流,可以调用 loads() 函数。但是,如果要对序列化和反序列化加以更多的控制,可以分别创建 Pickler 或 Unpickler 对象。



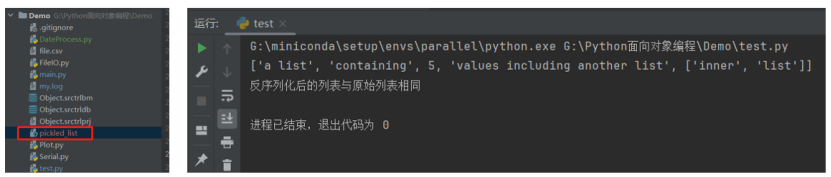
下面我们尝试使用 pickle 模块完成列表对象的存储和载入,示例代码如下:
import pickle
_# 待序列化的列表对象_
some_data = ["a list", "containing", 5, "values including another list", ["inner", "list"]]
_# 序列化对象,将列表存储到文件中_
_# 使用 open() 函数打开一个名为 "pickled_list" 的文件_
_# 以二进制写入模式 'wb' 打开文件_
with open("pickled_list", 'wb') as file:
_# 使用 pickle.dump() 方法将 some_data 对象序列化并写入到文件中_
pickle.dump(some_data, file)
_# 反序列化对象,将文件中列表载入_
_# 开同一个文件,以二进制读取模式 'rb' 打开文件_
with open("pickled_list", 'rb') as file:
_# 使用 pickle.load() 方法从文件中反序列化出 some_data 对象_
loaded_data = pickle.load(file)
_# 打印载入后的列表_
print(loaded_data)
_# 判断列表文件是否相同_
if loaded_data == some_data:
print("反序列化后的列表与原始列表相同")
运行结果如下,可以看到新出现了一个 pickled_list 二进制文件,同时反序列化后的列表与原始列表相同:
两个 dump 方法均设有可选的 protocol 参数。若我们所保存和载入的对象仅限于 Python 3 程序使用,则无需指定此参数。然而,若我们所存储的对象可能需要与旧版本的 Python 兼容,那么我们只能使用相对低效的旧协议。为确保数据的兼容性和安全性,我们在使用时需要仔细考虑此参数的设定。
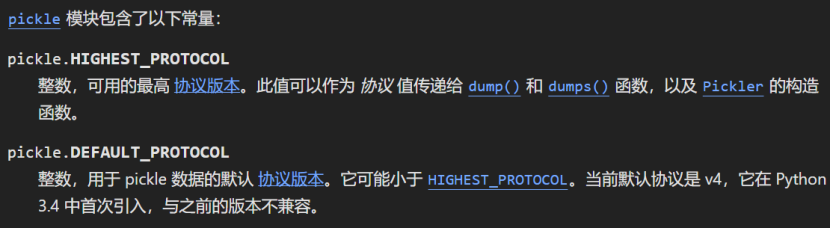
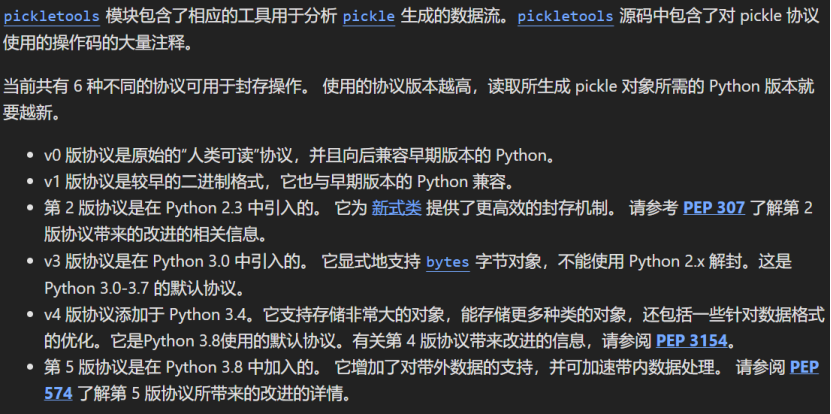
当数据反序列化回来的时候,会先假定所有的源数据时可用的。 模块、类和函数会自动按需导入进来。对于 Python 数据被不同机器上的解析器所共享的应用程序而言, 数据的保存可能会有问题,因为所有的机器都必须访问同一个源代码。
pickle 在加载时有一个副作用就是它会自动加载相应模块并构造实例对象。
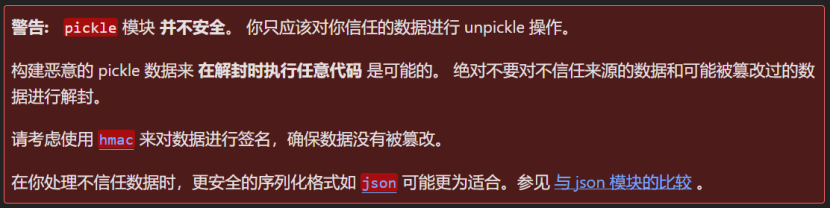
在使用 pickle 时,需要注意它不是一个安全的格式,从未知或不能信任的来源载入序列化对象有可能引入恶意代码/病毒,因此不要通过互联网将 pickle 传送给未知的解释器。
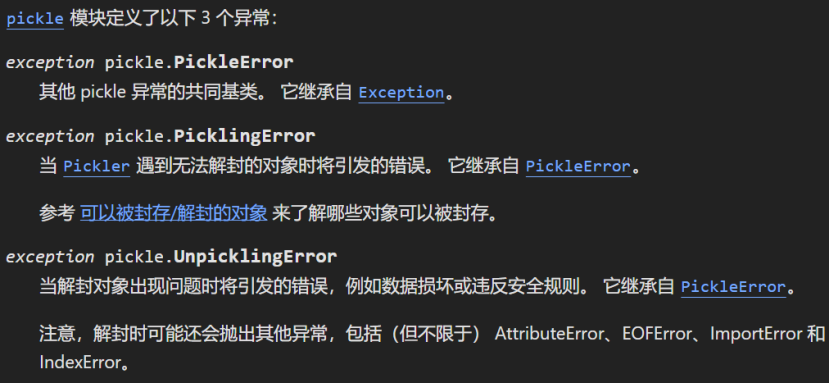
同时 pickle 模块中,也内置了一些有关序列化和反序列化操作失败的异常:
可以向一个打开的文件多次执行 dump 或 load 方法。每次调用 dump 将会存储一个单独的对象(加上它包含的所有对象),而执行 load 也只会载入、返回一个对象。因此对于单独的文件,每次调用 dump 来存储对象时应该有一个相关联的 load 调用。
pickle 对于大型的数据结构比如使用 array 或 numpy 模块创建的二进制数组效率并不是一个高效的编码方式。如果你需要移动大量的数组数据,你最好是先在一个文件中将其保存为数组数据块或使用更高级的标准编码方式如 HDF5 (需要第三方库的支持)。
对于最常见的 Python 对象,pickle 就能够很好地完成序列化。诸如整数、浮点数和字符串这些基本类型都可以进行序列化,包括任何容器对象,如列表或字典。除此之外,重要的是,任何对象都可以进行 pickle 序列化,只要其所有的属性都是可 pickle 的。
但是需要注意,与时间相关的属性或依赖外部系统状态的对象尽可能不要用 pickle 模块进行序列化。例如,打开的网络套接字、打开的文件、正在运行的线程、或者数据库连接,在未来的某个时间点尝试重新加载这些对象是不合理的,因为许多与之相关的系统状态信息可能已经不再存在。
在想要对存在与时间相关的属性的对象进行序列化时,我们可以自定义这种短暂存在的数据的存储和载入过程。用户自定义类可以通过提供 getstate()和 setstate()方法来绕过这些限制。如果定义了这两个方法,pickle.dump()就会调用 getstate()获取序列化的对象。类似的,setstate() 在反序列化时被调用。
在如下的代码中,我们定义了个名为 UpdatedURL 的类,该类用于定期更新指定 URL 的内容:
- 在类的初始化方法中,传入一个 URL 参数,并调用 update()方法来获取该 URL 的内容和最后更新时间。然后调用 schedule()方法来设置定时器,每隔一小时(3600 秒)调用一次 update()方法;
- update()方法使用 urlopen()函数打开指定的 URL,读取其中的内容,并记录当前时间作为最后更新时间。然后再次调用 schedule()方法来设置下一次定时器;
- schedule()方法创建一个 Timer 对象,将 update()方法作为回调函数,并设置为守护线程,最后启动定时器。
需要注意的是,这段代码中使用了 urlopen()、datetime.datetime.now()和 Timer 等函数或类,需要先导入相应的模块才能正常运行。
示例代码如下:
from threading import Timer
import datetime
from urllib.request import urlopen
import pickle
class UpdatedURL:
def __init__(self, url):
self.url = url
self.contents = ''
self.last_updated = None
self.update()
def update(self):
self.contents = urlopen(self.url).read()
self.last_updated = datetime.datetime.now()
self.schedule()
def schedule(self):
self.timer = Timer(3600, self.update)
self.timer.daemon = True
self.timer.start()
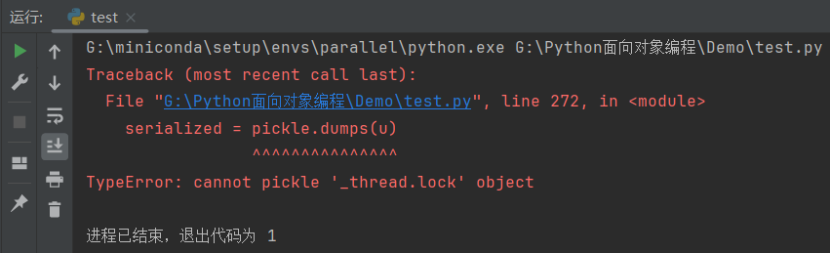
u = UpdatedURL("http://www.people.com.cn/")
url、contents 和 last_updated 都是可序列化的,接下来我们尝试序列化这个类的实例:
serialized = pickle.dumps(u)
运行结果如下:
当 pickle 模块对对象进行序列化时,它会首先尝试检查对象是否存在 __getstate__ 方法。如果存在此方法,pickle 则会选择存储 __getstate__ 方法的返回结果,反之,它会尝试存储该对象的 __dict__ 属性。__dict__ 是一个字典,它映射了对象的所有属性名称及其对应的值。
接下来,我们通过重写 UpdatedURL 类的__getstate__方法,实现对存在与时间相关的属性的对象进行序列化,在此__getstate__方法中,首先使用复制了该类实例的所有属性和值到一个新的字典对象 new_state 中。然后检查 new_state 中是否包含名为'timer'的键,如果存在则删除该键及其对应的值。最后返回新的字典对象:
def __getstate__(self):
new_state = self.__dict__.copy()
if 'timer' in new_state:
del new_state['timer']
return new_state
现在序列化这个对象,就不会再失败了。而且也可以成功地通过 loads 载入。不过,重新载入的对象不再拥有 timer 属性,因此将不能按照最初设计的那样定期刷新内容,我们需要为反序列化的对象创建一个新的 timer。
和重写__getstate__方法实现自定义序列化操作一样,我们也可以通过设置__setstate__方法实现自定义的反序列化操作。这个方法只接受一个参数,即__getstate__方法返回的对象。如果同时实现这两个方法,那么__getstate__就不一定非要返回一个字典对象了。因为不管返回什么对象__setstate__都是可以处理的。在这里,我们通过自定义__setstate__方法,重新修复__dict__。
def __setstate__(self, data):
self.__dict__ = data
self.schedule()
接着,我们对序列化后的 serialized 使用 load 方法进行反序列化:
u2 = pickle.loads(serialized)
_# 使用hasattr()函数判断对象是否包含对应属性_
print(hasattr(u2,'timer'))
print(u2.timer)
输出结果如下:
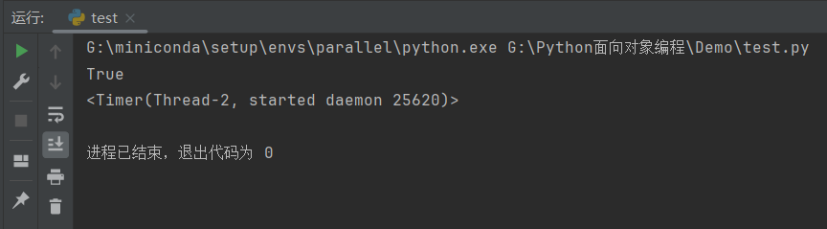
我们可以看到通过重写__setstate__方法我们可以实现自定义的反序列化操作,为反序列化的对象创建一个新的 timer。
使用 shelve 模块进行序列化
Shelve 模块是 Python 标准库中的一部分,它使用了 Python 的 pickle 模块,可以序列化和反序列化 Python 对象,将它们保存到磁盘文件中。但与 pickle 模块不同的是,它存储数据时使用键值对存储数据,类似于字典。
Shelve 模块是 Python 标准库的一部分,因此无需额外安装。要使用 Shelve,只需在 Python 脚本中导入它即可。在使用 Shelve 保存数据时,通常会创建一个 Shelve 文件,Shelve 文件实际上是一个包含键值对的数据库文件,通常以.db、.shelf 或.dat 为扩展名。
在接下来的示例中,我们创建一个 Shelve 文件,并将数据存储到文件中,我们可以使用键来访问和存储数据。
import shelve
_# 使用shelve.open()函数创建或打开一个Shelve文件_
with shelve.open('mydata.db') as shelf:
_# 使用 shelf['key'] = value 的方式将键值对写入到 Shelve 文件中_
shelf['name'] = 'Alice'
shelf['age'] = 30
shelf['scores'] = [95, 88, 72]
_# 使用 shelf['key'] 的方式从 Shelve 文件中读取数据_
_# 将其赋值给相应的变量_
name = shelf['name']
age = shelf['age']
scores = shelf['scores']
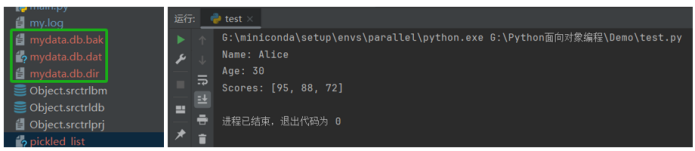
print(f'Name: {name}')
print(f'Age: {age}')
print(f'Scores: {scores}')
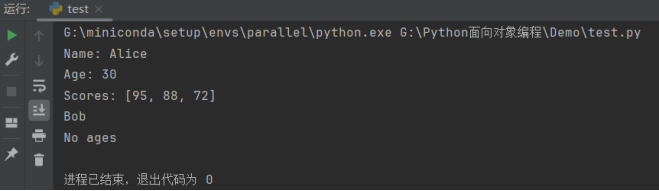
运行结果如下:
我们也可以像字典一样更新 Shelve 文件中的数据。如果使用已存在的键来存储新的值,它会覆盖旧的值。同样,也可以删除键以删除相应的值。
with shelve.open('mydata.db', writeback=True) as shelf:
_# 更新数据_
shelf['name'] = 'Bob'
_# 删除数据_
del shelf['age']
name = shelf['name']
print(name)
try:
age = shelf['age']
print(age)
except:
print("No ages")
虽然 Shelve 模块非常方便,但它也有一些限制和注意事项:Shelve 不支持多线程写操作。如果需要在多线程环境中写入 Shelve 文件,可以考虑使用线程锁来保护文件操作;同时 Shelve 文件的键必须是字符串,而值可以是任何可可序列化的 Python 对象。同时 Shelve 通常适用于小型应用程序、配置文件和简单的数据库需求,但不适合存储大量数据,因为它们需要在内存中加载整个数据库。
在使用 pickle 模块和 shelve 模块时,我们需要注意由于使用其特有的序列化协议,其序列化之后的数据只能被 Python 识别,因此只能用于 Python 系统内部。另外,Python 2.x 和 Python3.x 默认使用的序列化协议也不同,如果需要互相兼容需要在序列化时通过 protocol 参数指定协议版本。除了上面这些缺点外,pickle 模块和 shelve 模块相对于 json 模块的优点在于对于自定义数据类型可以直接序列化和反序列化,不需要编写额外的转换函数或类。
