JDK线程池详解(全网最全-原理解析、源码详解)
频繁创建新线程的缺点?
不受控风险
系统资源有限,每个人针对不同业务都可以手动创建线程,并且创建标准不一样(比如线程没有名字)。当系统运行起来,所有线程都在疯狂抢占资源,毫无规则,不好管控。
另外,过多的线程自然也会引起上下文切换的开销。
频繁创建开销大
new Thread() 在操作系统层面并没有创建新的线程;
真正转换为操作系统层面创建一个线程,还要调用操作系统内核的API,然后操作系统要为该线程分配一系列的资源。
new Object() 过程
Object obj = new Object();
- 分配一块内存 M
- 在内存 M 上初始化该对象
- 将内存 M 的地址赋值给引用变量 obj
创建线程过程
- JVM为一个线程栈分配内存,该栈为每个线程方法调用保存一个栈帧
- 每一栈帧由一个局部变量数组、返回值、操作数堆栈和常量池组成
- 一些支持本机方法的 jvm 也会分配一个本机堆栈
- 每个线程获得一个程序计数器,告诉它当前处理器执行的指令是什么
- 系统创建一个与Java线程对应的本机线程
- 将与线程相关的描述符添加到JVM内部数据结构中
- 线程共享堆和方法区域
使用线程池的优点
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,可以不需要等到线程创建就能立即执行。提高线程的可管理性。
- 统一管理线程,避免系统创建大量同类线程而导致消耗完内存。
并且在线程池在提交任务前,可以提前创建线程,ThreadPoolExecutor 提供了两个方法帮助我们在提交任务之前,完成核心线程的创建,从而实现线程池预热的效果,以便在应用程序开始处理请求时立即使用这些线程:
prestartCoreThread():启动一个线程,等待任务,如果已达到核心线程数,这个方法返回 false,否则返回 true;prestartAllCoreThreads():启动所有的核心线程,并返回启动成功的核心线程数。
线程池原理
JDK线程池参数
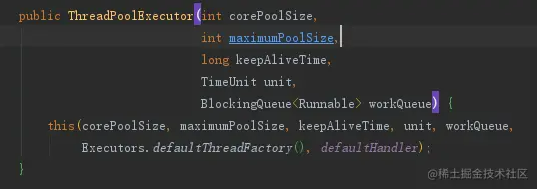
ThreadPoolExecutor 的通用构造函数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler);
-
corePoolSize:当有新任务时,如果线程池中线程数没有达到核心线程池的大小corePoolSize,则会创建新的线程执行任务,否则将任务放入阻塞队列。当线程池中存活的线程数总是大于 corePoolSize 时,应该考虑调大 corePoolSize。
-
maximumPoolSize:当阻塞队列填满时,如果线程池中线程数没有超过最大线程数maximumPoolSize,则会创建新的线程运行任务。如果线程池中线程数已经达到最大线程数maximumPoolSiz,则会根据拒绝策略处理新任务。非核心线程类似于临时借来的资源,这些线程在空闲时间超过 keepAliveTime 之后,就应该退出,避免资源浪费。
-
BlockingQueue:阻塞队列,存储等待运行的任务。
-
keepAliveTime:非核心线程空闲后,保持存活的时间,此参数只对非核心线程有效。设置为0,表示多余的空闲线程会被立即终止。
-
TimeUnit:keepAliveTime的时间单位TimeUnit.DAYS
-
TimeUnit.HOURS
-
TimeUnit.MINUTES
-
TimeUnit.SECONDS
-
TimeUnit.MILLISECONDS
-
TimeUnit.MICROSECONDS
-
TimeUnit.NANOSECONDS
-
-
ThreadFactory:每当线程池创建一个新的线程时,都是通过线程工厂方法来完成的。在 ThreadFactory 中只定义了一个方法 newThread,每当线程池需要创建新线程就会调用它。
public class MyThreadFactory implements ThreadFactory {
private final String poolName;
public MyThreadFactory(String poolName) {
this.poolName = poolName;
}
public Thread newThread(Runnable runnable) {
return new MyAppThread(runnable, poolName);//将线程池名字传递给构造函数,用于区分不同线程池的线程
}
}
-
RejectedExecutionHandler:当队列和线程池都满了的时候,根据拒绝策略处理新任务。
-
AbortPolicy:默认的策略,直接抛出RejectedExecutionException。如果是比较关键的业务,推荐使用此拒绝策略,这样子在系统不能承载更大的并发量的时候,能够及时的通过异常发现。
-
DiscardPolicy:不处理,直接丢弃。建议是一些无关紧要的业务采用此策略。
-
DiscardOldestPolicy:将等待队列队首的任务丢弃,并执行当前任务。得根据实际业务是否允许丢弃老任务来认真衡量。
-
CallerRunsPolicy:由调用线程处理该任务CallerRunsPolicy:由调用线程处理该任务
-
线程池的核心组成
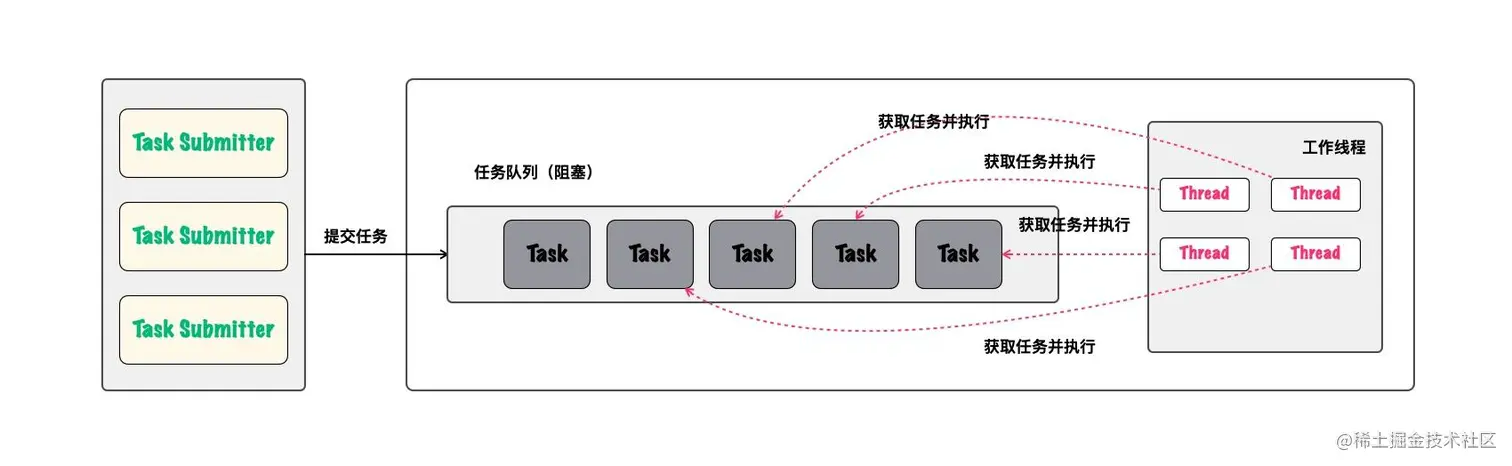
一个完整的线程池,应该包含以下几个核心部分:
-
任务提交:提供接口接收任务的提交;
-
任务管理:选择合适的队列对提交的任务进行管理,包括对拒绝策略的设置;
-
任务执行:由工作线程来执行提交的任务;
-
线程池管理:包括基本参数设置、任务监控、工作线程管理等
线程池执行具体过程
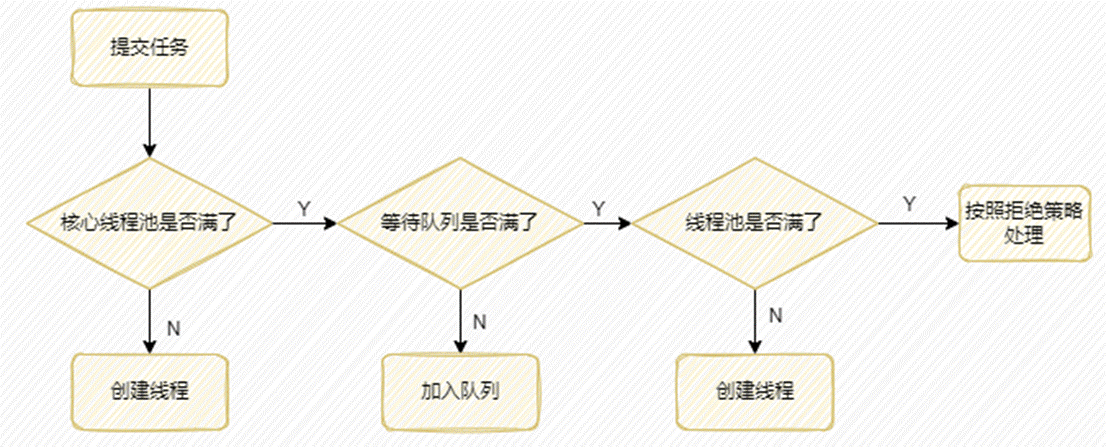
- 当线程池里存活的线程数小于核心线程数corePoolSize时,这时对于一个新提交的任务,线程池会创建一个线程去处理任务。当线程池里面存活的线程数小于等于核心线程数corePoolSize时,线程池里面的线程会一直存活着,就算空闲时间超过了keepAliveTime,线程也不会被销毁,而是一直阻塞在那里一直等待任务队列的任务来执行。因为keepAliveTime只对非核心线程有效。
- 当线程池里面存活的线程数已经等于corePoolSize了,这是对于一个新提交的任务,会被放进任务队列workQueue排队等待执行。
- 当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列也满了,假设maximumPoolSize>corePoolSize,这时如果再来新的任务,线程池就会继续创建新的线程来处理新的任务,直到线程数达到maximumPoolSize,就不会再创建了。
- 如果当前的线程数达到了maximumPoolSize,并且任务队列也满了,如果还有新的任务过来,那就直接采用拒绝策略进行处理。默认的拒绝策略是抛出一个RejectedExecutionException异常。
线程池生命周期
| 线程池状态 | 状态释义 |
|---|---|
| RUNNING | 线程池被创建后的初始状态,能接受新提交的任务,并且也能处理阻塞队列中的任务 |
| SHUTDOWN | 关闭状态,不再接受新提交的任务,但仍可以继续处理已进入阻塞队列中的任务 |
| STOP | 会中断正在处理任务的线程,不能再接受新任务,也不继续处理队列中的任务 |
| TIDYING | 所有的任务都已终止,workerCount(有效工作线程数)为0 |
| TERMINATED | 线程池彻底终止运行 |
Tips:千万不要把线程池的状态和线程的状态弄混了。补一张网上的线程状态图
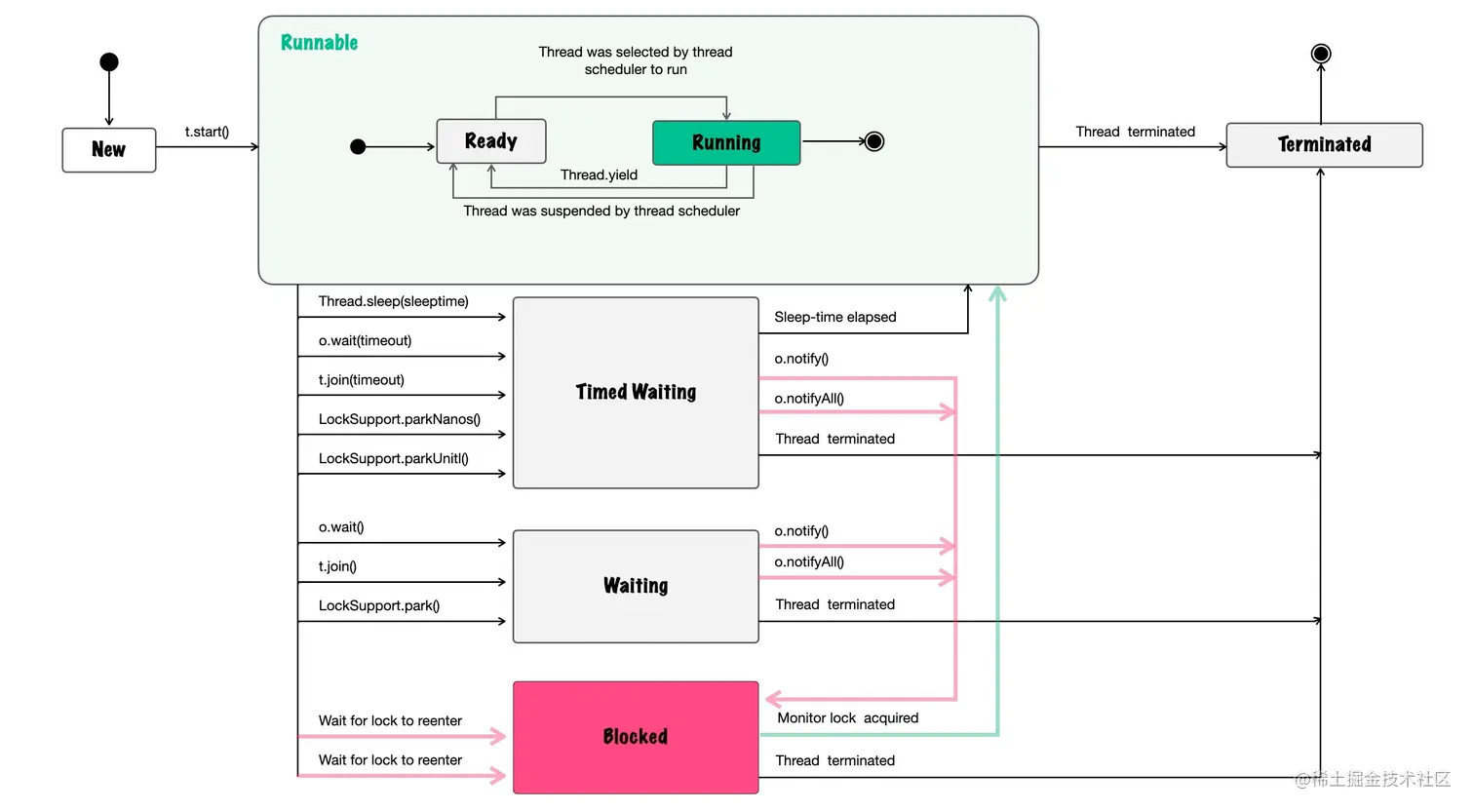
Tips:当线程调用start(),线程在JVM中不一定立即执行,有可能要等待操作系统分配资源,此时为READY状态,当线程获得资源时进入RUNNING状态,才会真正开始执行。
线程池的预初始化机制
线程池的预初始化机制是指在线程池创建后,立即创建并启动一定数量的线程,即使这些线程暂时还没有任务要执行。这样做的目的是减少在实际接收到任务时创建线程所需的时间,从而提高响应速度。ThreadPoolExecutor提供了预初始化线程的功能。
预初始化方法(prestartCoreThread / prestartAllCoreThreads): ThreadPoolExecutor提供了两个方法来预初始化线程:
-
prestartCoreThread():预初始化一个核心线程。如果核心线程数已经达到了设定的数量,则此方法不会有任何效果。
public boolean prestartCoreThread() { return workerCountOf(ctl.get()) < corePoolSize && addWorker(null, true); } -
prestartAllCoreThreads():预初始化所有核心线程,即创建并启动等于核心线程数的线程
public int prestartAllCoreThreads() { int n = 0; while (addWorker(null, true)) ++n; return n; }
拒绝策略
-
CallerRunsPolicy:调用执行自己的线程运行任务,也就是直接在调用
execute方法的线程中运行(run)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果你的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。 -
AbortPolicy:抛出
RejectedExecutionException来拒绝新任务的处理。 -
DiscardPolicy:不处理新任务,直接丢弃掉。
-
DiscardOldestPolicy:此策略将丢弃最早的未处理的任务请求。
当没有显示指明拒绝策略时,默认使用AbortPolicy
CallerRunsPolicy
如果不允许丢弃任务,就应该选择CallerRunsPolicy。CallerRunsPolicy 和其他的几个策略不同,它既不会抛弃任务,也不会抛出异常,而是将任务回退给调用者,使用调用者的线程来执行任务。
public static class CallerRunsPolicy implements RejectedExecutionHandler {
public CallerRunsPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// 直接主线程执行,而不是线程池中的线程执行
r.run();
}
}
}
存在的问题:如果走到CallerRunsPolicy的任务是个非常耗时的任务,且处理提交任务的线程是主线程,可能会导致主线程阻塞,进而导致后续任务无法及时执行,严重的情况下很可能导致 OOM。
当然,采用CallerRunsPolicy其实就是希望所有的任务都能够被执行,暂时无法处理的任务又被保存在阻塞队列BlockingQueue中。这样的话,在内存允许的情况下,就可以增加阻塞队列BlockingQueue的大小并调整堆内存以容纳更多的任务,确保任务能够被准确执行。为了充分利用 CPU,还可以调整线程池的maximumPoolSize (最大线程数)参数,这样可以提高任务处理速度,避免累计在 BlockingQueue的任务过多导致内存用完。
但是,如果服务器资源达到可利用的极限了呢?导致主线程卡死的本质就是因为不希望任何一个任务被丢弃。换个思路,有没有办法既能保证任务不被丢弃且在服务器有余力时及时处理呢?
可以考虑任务持久化的思路,这里所谓的任务持久化,包括但不限于:
- 设计一张任务表间任务存储到 MySQL 数据库中。
Redis缓存任务。- 将任务提交到消息队列中。
这里以方案一为例,简单介绍一下实现逻辑:
- 实现
RejectedExecutionHandler接口自定义拒绝策略,自定义拒绝策略负责将线程池暂时无法处理(此时阻塞队列已满)的任务入库(保存到 MySQL 中)。注意:线程池暂时无法处理的任务会先被放在阻塞队列中,阻塞队列满了才会触发拒绝策略。 - 继承
BlockingQueue实现一个混合式阻塞队列,该队列包含JDK自带的ArrayBlockingQueue。另外,该混合式阻塞队列需要修改取任务处理的逻辑,也就是重写take()方法,取任务时优先从数据库中读取最早的任务,数据库中无任务时再从ArrayBlockingQueue中去取任务。
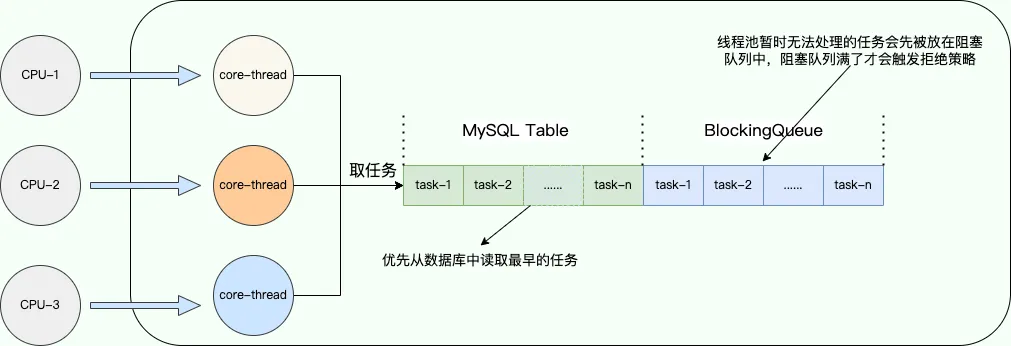
也就是说,一旦线程池中线程达到满载时,就可以通过拒绝策略将最新任务持久化到 MySQL 数据库中,等到线程池有了有余力处理所有任务时,让其优先处理数据库中的任务以避免"饥饿"问题。
当然,对于这个问题,也可以参考其他主流框架的做法:
- 以 Netty 为例,它的拒绝策略则是直接创建一个线程池以外的线程处理这些任务,为了保证任务的实时处理,这种做法可能需要良好的硬件设备且临时创建的线程无法做到准确的监控:
private static final class NewThreadRunsPolicy implements RejectedExecutionHandler {
NewThreadRunsPolicy() {
super();
}
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
try {
//创建一个临时线程处理任务
final Thread t = new Thread(r, "Temporary task executor");
t.start();
} catch (Throwable e) {
throw new RejectedExecutionException(
"Failed to start a new thread", e);
}
}
}
- ActiveMQ 则是尝试在指定的时效内尽可能的争取将任务入队,以保证最大交付:
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(final Runnable r, final ThreadPoolExecutor executor) {
try {
//限时阻塞等待,实现尽可能交付
executor.getQueue().offer(r, 60, TimeUnit.SECONDS);
} catch (InterruptedException e) {
throw new RejectedExecutionException("Interrupted waiting for BrokerService.worker");
}
throw new RejectedExecutionException("Timed Out while attempting to enqueue Task.");
}
});
任务执行机制
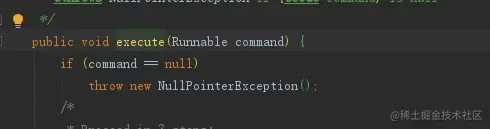
- 通过执行execute方法 该方法无返回值,为ThreadPoolExecutor自带方法,传入Runnable类型对象
- 通过执行submit方法 该方法返回值为Future对象,为抽象类AbstractExecutorService的方法,被ThreadPoolExecutor继承,其内部实现也是调用了接口类Executor的execute方法,通过上面的类图可以看到,该方法的实现依然是ThreadPoolExecutor的execute方法
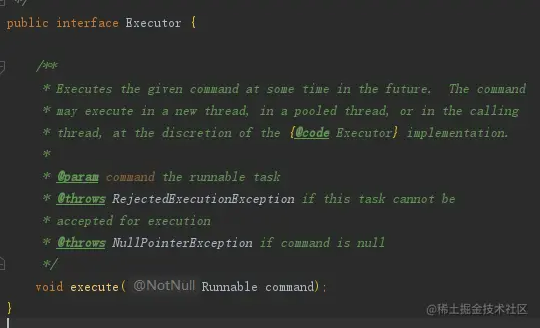
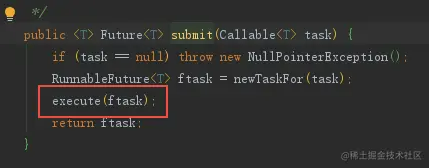
execute()执行流程图
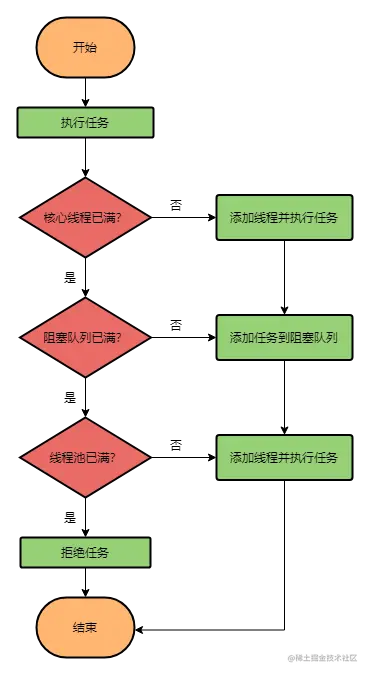
execute()源码
// 使用原子操作类AtomicInteger的ctl变量,前3位记录线程池的状态,后29位记录线程数
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// Integer的范围为[-2^31,2^31 -1], Integer.SIZE-3 =32-3= 29,用来辅助左移位运算
private static final int COUNT_BITS = Integer.SIZE - 3;
// 高三位用来存储线程池运行状态,其余位数表示线程池的容量
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池状态以常量值被存储在高三位中
private static final int RUNNING = -1 << COUNT_BITS; // 线程池接受新任务并会处理阻塞队列中的任务
private static final int SHUTDOWN = 0 << COUNT_BITS; // 线程池不接受新任务,但会处理阻塞队列中的任务
private static final int STOP = 1 << COUNT_BITS; // 线程池不接受新的任务且不会处理阻塞队列中的任务,并且会中断正在执行的任务
private static final int TIDYING = 2 << COUNT_BITS; // 所有任务都执行完成,且工作线程数为0,将调用terminated方法
private static final int TERMINATED = 3 << COUNT_BITS; // 最终状态,为执行terminated()方法后的状态
// ctl变量的封箱拆箱相关的方法
private static int runStateOf(int c) { return c & ~CAPACITY; } // 获取线程池运行状态
private static int workerCountOf(int c) { return c & CAPACITY; } // 获取线程池运行线程数
private static int ctlOf(int rs, int wc) { return rs | wc; } // 获取ctl对象
public void execute(Runnable command) {
if (command == null) // 任务为空,抛出NPE
throw new NullPointerException();
int c = ctl.get(); // 获取当前工作线程数和线程池运行状态(共32位,前3位为运行状态,后29位为运行线程数)
if (workerCountOf(c) < corePoolSize) { // 如果当前工作线程数小于核心线程数
if (addWorker(command, true)) // 在addWorker中创建核心线程并执行任务
return;
c = ctl.get();
}
// 核心线程数已满(工作线程数>核心线程数)才会走下面的逻辑
if (isRunning(c) && workQueue.offer(command)) { // 如果当前线程池状态为RUNNING,并且任务成功添加到阻塞队列
int recheck = ctl.get(); // 双重检查,因为从上次检查到进入此方法,线程池可能已成为SHUTDOWN状态
if (! isRunning(recheck) && remove(command)) // 如果当前线程池状态不是RUNNING则从队列删除任务
reject(command); // 执行拒绝策略
else if (workerCountOf(recheck) == 0) // 当线程池中的workerCount为0时,此时workQueue中还有待执行的任务,则新增一个addWorker,消费workqueue中的任务
addWorker(null, false);
}
// 阻塞队列已满才会走下面的逻辑
else if (!addWorker(command, false)) // 尝试增加工作线程执行command
// 如果当前线程池为SHUTDOWN状态或者线程池已饱和
reject(command); // 执行拒绝策略
}
execute体现的就是线程池的工作原理,addWorker则是更复杂的逻辑来保证worker的原子性地插入
private boolean addWorker(Runnable firstTask, boolean core) {
retry: // 循环退出标志位
for (;;) { // 无限循环
int c = ctl.get();
int rs = runStateOf(c); // 线程池状态
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN && firstTask == null && ! workQueue.isEmpty()) // 换成更直观的条件语句
// (rs != SHUTDOWN || firstTask != null || workQueue.isEmpty())
)
// 返回false的条件就可以分解为:
//(1)线程池状态为STOP,TIDYING,TERMINATED
//(2)线程池状态为SHUTDOWN,且要执行的任务不为空
//(3)线程池状态为SHUTDOWN,且任务队列为空
return false;
// cas自旋增加线程个数
for (;;) {
int wc = workerCountOf(c); // 当前工作线程数
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize)) // 工作线程数>=线程池容量 || 工作线程数>=(核心线程数||最大线程数)
return false;
if (compareAndIncrementWorkerCount(c)) // 执行cas操作,添加线程个数
break retry; // 添加成功,退出外层循环
// 通过cas添加失败
c = ctl.get();
// 线程池状态是否变化,变化则跳到外层循环重试重新获取线程池状态,否者内层循环重新cas
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
// 简单总结上面的CAS过程:
//(1)内层循环作用是使用cas增加线程个数,如果线程个数超限则返回false,否者进行cas
//(2)cas成功则退出双循环,否者cas失败了,要看当前线程池的状态是否变化了
//(3)如果变了,则重新进入外层循环重新获取线程池状态,否者重新进入内层循环继续进行cas
// 走到这里说明cas成功,线程数+1,但并未被执行
boolean workerStarted = false; // 工作线程调用start()方法标志
boolean workerAdded = false; // 工作线程被添加标志
Worker w = null;
try {
w = new Worker(firstTask); // 创建工作线程实例
final Thread t = w.thread; // 获取工作线程持有的线程实例
if (t != null) {
final ReentrantLock mainLock = this.mainLock; // 使用全局可重入锁
mainLock.lock(); // 加锁,控制并发
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get()); // 获取当前线程池状态
// 线程池状态为RUNNING或者(线程池状态为SHUTDOWN并且没有新任务时)
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // 检查线程是否处于活跃状态
throw new IllegalThreadStateException();
workers.add(w); // 线程加入到存放工作线程的HashSet容器,workers全局唯一并被mainLock持有
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock(); // finally块中释放锁
}
if (workerAdded) { // 线程添加成功
t.start(); // 调用线程的start()方法
workerStarted = true;
}
}
} finally {
if (! workerStarted) // 如果线程启动失败,则执行addWorkerFailed方法
addWorkerFailed(w);
}
return workerStarted;
}
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w); // 线程启动失败时,需将前面添加的线程删除
decrementWorkerCount(); // ctl变量中的工作线程数-1
tryTerminate(); // 尝试将线程池转变成TERMINATE状态
} finally {
mainLock.unlock();
}
}
final void tryTerminate() {
for (;;) {
int c = ctl.get();
// 以下情况不会进入TERMINATED状态:
//(1)当前线程池为RUNNING状态
//(2)在TIDYING及以上状态
//(3)SHUTDOWN状态并且工作队列不为空
//(4)当前活跃线程数不等于0
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
if (workerCountOf(c) != 0) { // 工作线程数!=0
interruptIdleWorkers(ONLY_ONE); // 中断一个正在等待任务的线程
return;
}
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 通过CAS自旋判断直到当前线程池运行状态为TIDYING并且活跃线程数为0
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated(); // 调用线程terminated()
} finally {
ctl.set(ctlOf(TERMINATED, 0)); // 设置线程池状态为TERMINATED,工作线程数为0
termination.signalAll(); // 通过调用Condition接口的signalAll()唤醒所有等待的线程
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}
Worker源码
Worker是ThreadPoolExecutor类的内部类,此处只讲最重要的构造函数和run方法
private final class Worker extends AbstractQueuedSynchronizer implements Runnable {
// 该worker正在运行的线程
final Thread thread;
// 将要运行的初始任务
Runnable firstTask;
// 每个线程的任务计数器
volatile long completedTasks;
// 构造方法
Worker(Runnable firstTask) {
setState(-1); // 调用runWorker()前禁止中断
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); // 通过ThreadFactory创建一个线程
}
// 实现了Runnable接口的run方法
public void run() {
runWorker(this);
}
... // 此处省略了其他方法
}
Worker实现了Runable接口,在调用start()方法候,实际执行的是run方法Worker实现了Runable接口,在调用start()方法候,实际执行的是run方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask; // 获取工作线程中用来执行任务的线程实例
w.firstTask = null;
w.unlock(); // status设置为0,允许中断
boolean completedAbruptly = true; // 线程意外终止标志
try {
// 如果当前任务不为空,则直接执行;否则调用getTask()从任务队列中取出一个任务执行
while (task != null || (task = getTask()) != null) {
w.lock(); // 加锁,保证下方临界区代码的线程安全
// 如果状态值大于等于STOP且当前线程还没有被中断,则主动中断线程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt(); // 中断当前线程
try {
beforeExecute(wt, task); // 任务执行前的回调,空实现,可以在子类中自定义
Throwable thrown = null;
try {
task.run(); // 执行线程的run方法
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown); // 任务执行后的回调,空实现,可以在子类中自定义
}
} finally {
task = null; // 将循环变量task设置为null,表示已处理完成
w.completedTasks++; // 当前已完成的任务数+1
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
从任务队列中取出一个任务
private Runnable getTask() {
boolean timedOut = false; // 通过timeOut变量表示线程是否空闲时间超时了
// 无限循环
for (;;) {
int c = ctl.get(); // 线程池信息
int rs = runStateOf(c); // 线程池当前状态
// 如果线程池状态>=SHUTDOWN并且工作队列为空 或 线程池状态>=STOP,则返回null,让当前worker被销毁
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount(); // 工作线程数-1
return null;
}
int wc = workerCountOf(c); // 获取当前线程池的工作线程数
// 当前线程是否允许超时销毁的标志
// 允许超时销毁:当线程池允许核心线程超时 或 工作线程数>核心线程数
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 如果(当前线程数大于最大线程数 或 (允许超时销毁 且 当前发生了空闲时间超时))
// 且(当前线程数大于1 或 阻塞队列为空)
// 则减少worker计数并返回null
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 根据线程是否允许超时判断用poll还是take(会阻塞)方法从任务队列头部取出一个任务
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();//线程池重用逻辑:没有任务了就阻塞在这里,等待新的任务
if (r != null)
return r; // 返回从队列中取出的任务
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
总结一下哪些情况getTask()会返回null:
-
线程池状态为SHUTDOWN且任务队列为空
-
线程池状态为STOP、TIDYING、TERMINATED
-
线程池线程数大于最大线程数
-
线程可以被超时回收的情况下等待新任务超时
工作线程退出
private void processWorkerExit(Worker w, boolean completedAbruptly) {
// 如果completedAbruptly为true则表示任务执行过程中抛出了未处理的异常
// 所以还没有正确地减少worker计数,这里需要减少一次worker计数
if (completedAbruptly)
decrementWorkerCount();
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 把将被销毁的线程已完成的任务数累加到线程池的完成任务总数上
completedTaskCount += w.completedTasks;
workers.remove(w); // 从工作线程集合中移除该工作线程
} finally {
mainLock.unlock();
}
// 尝试结束线程池
tryTerminate();
int c = ctl.get();
// 如果是RUNNING 或 SHUTDOWN状态
if (runStateLessThan(c, STOP)) {
// worker是正常执行完
if (!completedAbruptly) {
// 如果允许核心线程超时则最小线程数是0,否则最小线程数等于核心线程数
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
// 如果阻塞队列非空,则至少要有一个线程继续执行剩下的任务
if (min == 0 && ! workQueue.isEmpty())
min = 1;
// 如果当前线程数已经满足最小线程数要求,则不需要再创建替代线程
if (workerCountOf(c) >= min)
return; // replacement not needed
}
// 重新创建一个worker来代替被销毁的线程
addWorker(null, false);
}
}
submit源码
提交任务到线程池有两种方法,一种是execute,另一种是submit。区别是execute没有返回值,submit是有返回值的,如果有异常抛出,submit同样可以获取异常结果。
// AbstractExecutorService.submit
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
}
submit中调用了newTaskFor方法来返回一个ftask对象,然后execute这个ftask对象,newTaskFor代码如下:
// AbstractExecutorService.newTaskFor
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
}
newTaskFor又调用FutureTask的有参构造器来创建一个futureTask实例,代码如下:
// FutureTask有参构造器
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
这个有参构造器中又调用了Executors的静态方法callable创建一个callable实例来赋值给futureTask的callable属性,代码如下:
// Executors.callable
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
最后还是使用了RunnableAdapter来包装这个task,代码如下:
// Executors.RunnableAdapter类
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
梳理一下整个流程,run和call的关系的伪代码如下
// submit
run(){
// RunnableAdapter.call
call(){
// task.run
run(){
// 实际的任务
}
}
}
为什么要这么麻烦封装一层又一层呢?
可能是为了适配。submit的返回值是futureTask,但是传给submit的是个runnable,然后submit会把这个runnable继续传给futureTask,futureTask的结果值是null,但是又由于futureTask的run方法已经被重写成执行call方法了,所以只能在call方法里面跑真正的run方法了
线程池提交一个任务占多大内存
提交任务到线程池有两种方法,一种是execute,一种是submit
那么这两种提交方式占用的内存是一样大的吗?一个空任务究竟占多少内存?
execute提交
使用execute提交一个任务,这个任务究竟多大呢?
使用得最多的就是使用lambda表达式来提交任务
threadPoolExecutor.execute(() -> {
// ...
});
那么这个lambda实例占用多少个字节呢?16字节;在开了指针压缩的情况下,对象头占12个字节,4个字节用于填充补齐到8的整数倍,由于这个lambda实例中没有其他成员变量了,所以它就是占据16个字节
除此之外,如果使用的是LinkedBlockingQueue阻塞队列来存放任务,那么还涉及到LinkedBlockingQueue中的Node,LinkedBlockingQueue会使用这个Node来封装任务
static class Node<E> {
E item;
/**
* One of:
* - the real successor Node
* - this Node, meaning the successor is head.next
* - null, meaning there is no successor (this is the last node)
*/
Node<E> next;
Node(E x) { item = x; }
}
这个Node占多少字节呢?24个字节;同样对象头占12字节,item是一个4字节的引用,next也是一个4字节的引用,一共20字节,4个字节用于填充对齐,所以一个node对象是24字节。
所以在使用execute且阻塞队列是LinkedBlockingQueue时一个任务占用40个字节,如果execute 20 w个任务,会占用 800w 个字节,约7.6MB内存
堆快照如下:
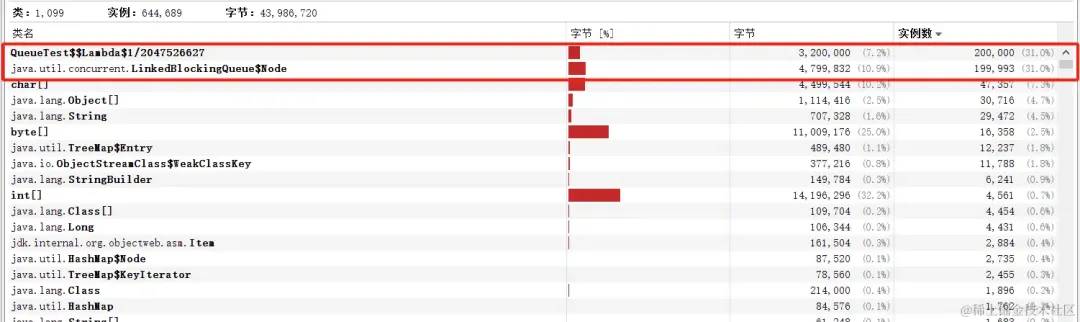
如果是使用ArrayBlockingQueue的话,只有lambda实例这一个开销,所以只会使用320w个字节,约3.05MB内存,比起LinkedBlockingQueue少了一倍不止
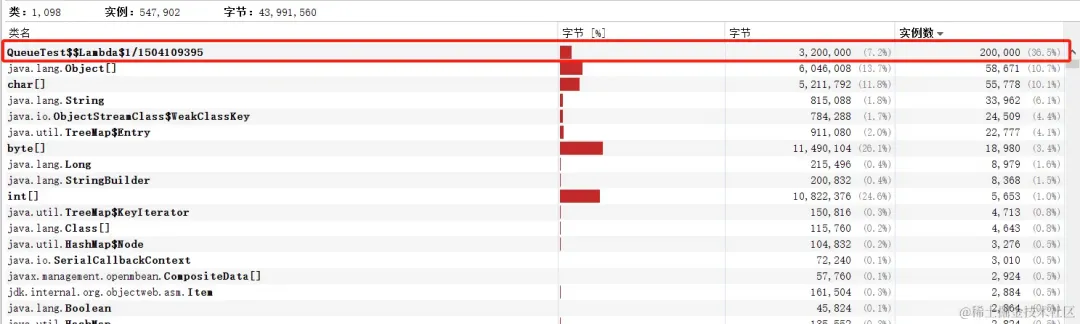
submit提交
根据上面源码分析得知,如果是用了submit方法之后,会多出两类对象,一个是FutureTask,一个是RunnableAdapter。
FutureTask的成员变量如下:
/** The underlying callable; nulled out after running */
private Callable<V> callable;
/** The result to return or exception to throw from get() */
private Object outcome; // non-volatile, protected by state reads/writes
/** The thread running the callable; CASed during run() */
private volatile Thread runner;
/** Treiber stack of waiting threads */
private volatile WaitNode waiters;
一个FutureTask对象占用的字节数是12+4+4+4+4=28个字节,还需要4个字节做填充,所以一共是32个字节。
RunnableTask的成员变量如下:
final Runnable task;
final T result;
一个RunnableTask对象占用的字节数是12+4+4=20个字节,同样需要4个字节做填充,所以一共是24个字节。
所以在使用submit且阻塞队列是LinkedBlockingQueue时一个任务占用96个字节
如果submit 20w个任务,会占用1920w个字节,约18.31MB内存
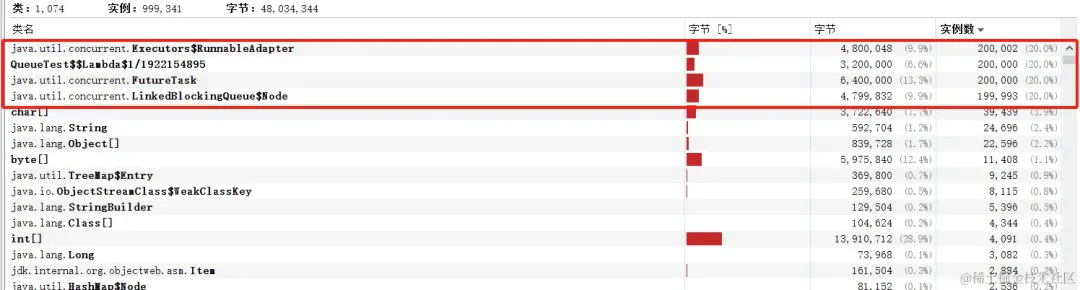
如果使用的是ArrayBlockingQueue会省去Node的占用的内存。
lambda中没有使用上下文中的其他变量
public static void main(String[] args) {
ThreadPoolExecutor threadPoolExecutor =
new ThreadPoolExecutor(8, 8, 15, TimeUnit.MINUTES, new LinkedBlockingQueue<>(), new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 0; i < (int) 2e5; i++) {
// int finalI = i;
threadPoolExecutor.submit(() -> {
// 乱写...
// int p = finalI;
LockSupport.park();
});
}
LockSupport.park();
}
如果在lambda中没有使用到上下文的其他变量时,是不会重复创建lambda实例的,只会创建一个
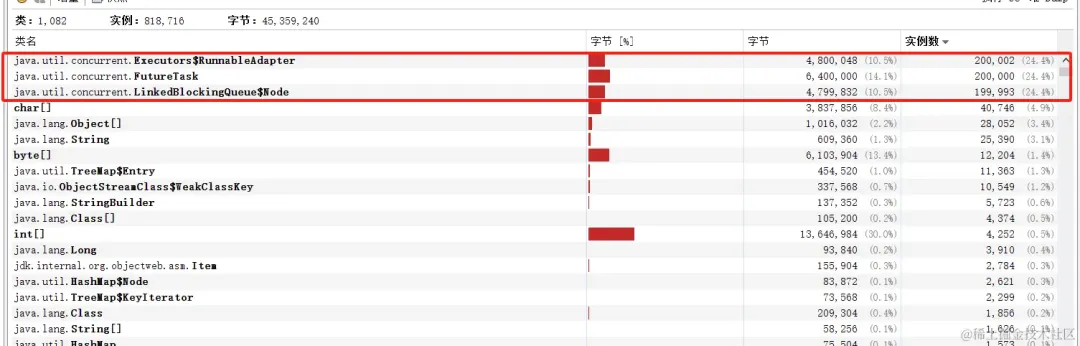
只会创建一个lambda实例
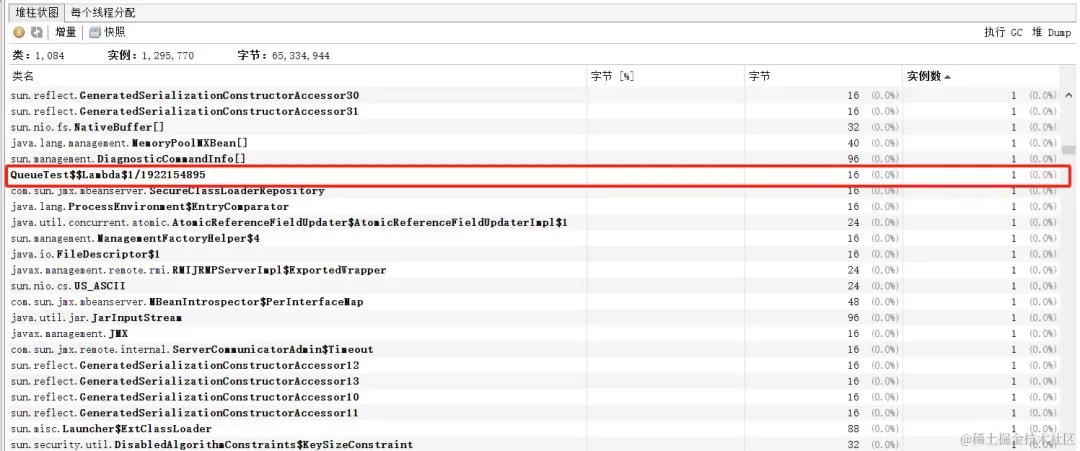
如果配合上ArrayBlockingQueue以及execute,提交20w个任务的空间复杂度可以降至O(1)
因为20w个任务的实例都是同一个
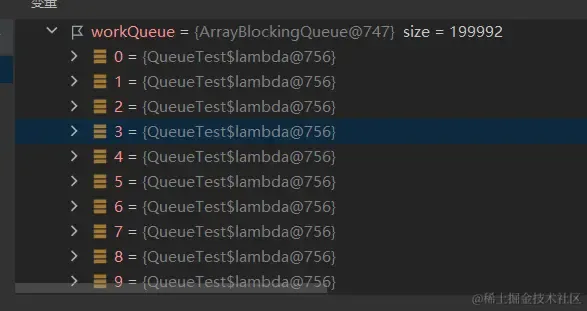
小结
如果是lambda中没有上下文变量,使用的队列是ArrayBlockingQueue,提交方式是execute,那么空间复杂度可以达到O(1);如果lambda中有上下文变量,每次提交任务都会创建一个新的lambda实例;
如果使用的队列是LinkedBlockingQueue,那么还要算上LinkedBlockingQueue的Node实例的开销;如果提交的方式是submit,那么还要算上FutureTask和RunnableAdapter的开销。
当然这里只是浅层地讨论了一下创建一个空任务所占用的内存大小,如果是更加复杂的任务,任务内的内存开销需要算上。
线程池中线程异常后,销毁还是复用
先说结论,需要分两种情况:
-
使用
execute()提交任务:当任务通过execute()提交到线程池并在执行过程中抛出异常时,如果这个异常没有在任务内被捕获,那么该异常会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这种线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。 -
使用
submit()提交任务:对于通过submit()提交的任务,如果在任务执行中发生异常,这个异常不会直接打印出来。相反,异常会被封装在由submit()返回的Future对象中。当调用Future.get()方法时,可以捕获到一个ExecutionException。在这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。
简单来说:使用execute()时,未捕获异常导致线程终止,线程池创建新线程替代;使用submit()时,异常被封装在Future中,线程继续复用。
这种设计允许submit()提供更灵活的错误处理机制,因为它允许调用者决定如何处理异常,而execute()则适用于那些不需要关注执行结果的场景。
execute()提交
查看execute方法的执行逻辑

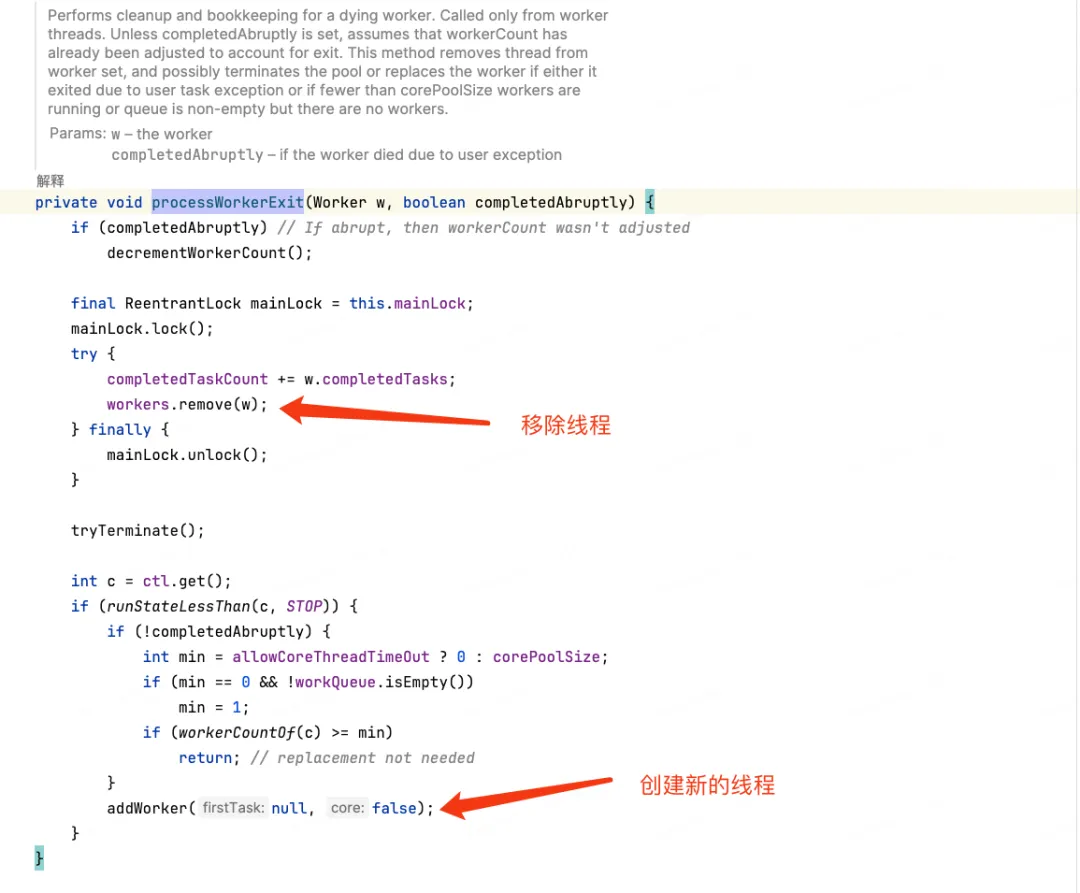
可以发现,如果抛出异常,execute()提交的方式会移除抛出异常的线程,创建新的线程。
submit()提交

可以发现,submit也是调用了execute方法,但是在调用之前,包装了一层 RunnableFuture,那一定是在RunnableFuture的实现 FutureTask中有特殊处理了,我们查看源码可以发现。
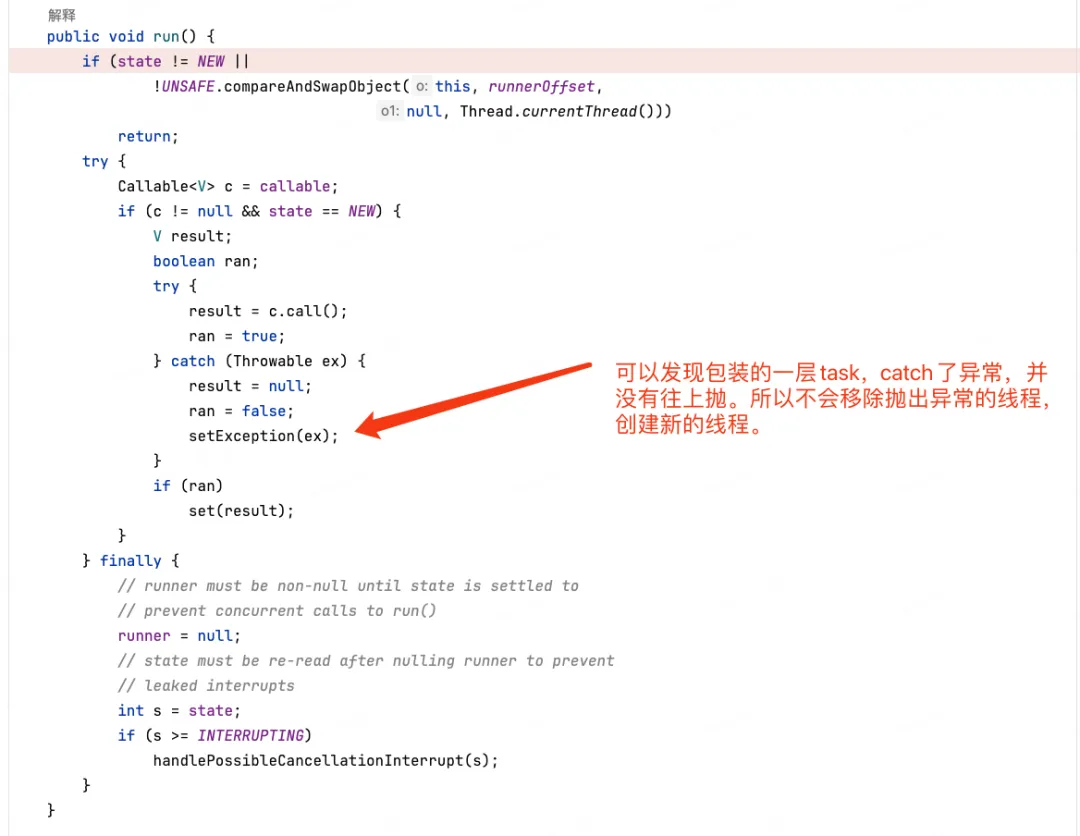

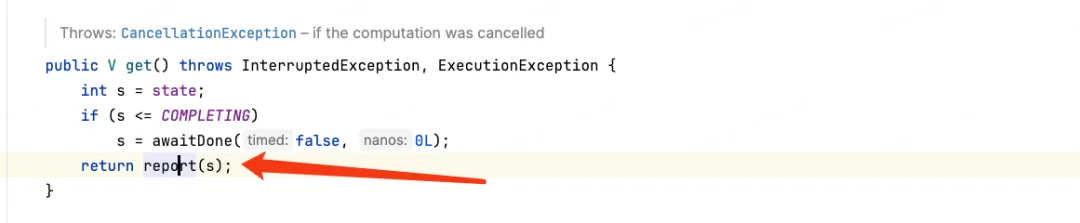

也就是说,通过java.util.concurrent.FutureTask#get(),就可以获取对应的异常信息。
线程池是如何保活和回收的
线程池的作用就是提高线程的利用率,需要线程时,可以直接从线程池中获取线程直接使用,而不用创建线程,那线程池中的线程,在没有任务执行时,是如何保活的呢?
在runWorker方法里,线程会循环getTask()获取阻塞队列中的任务。
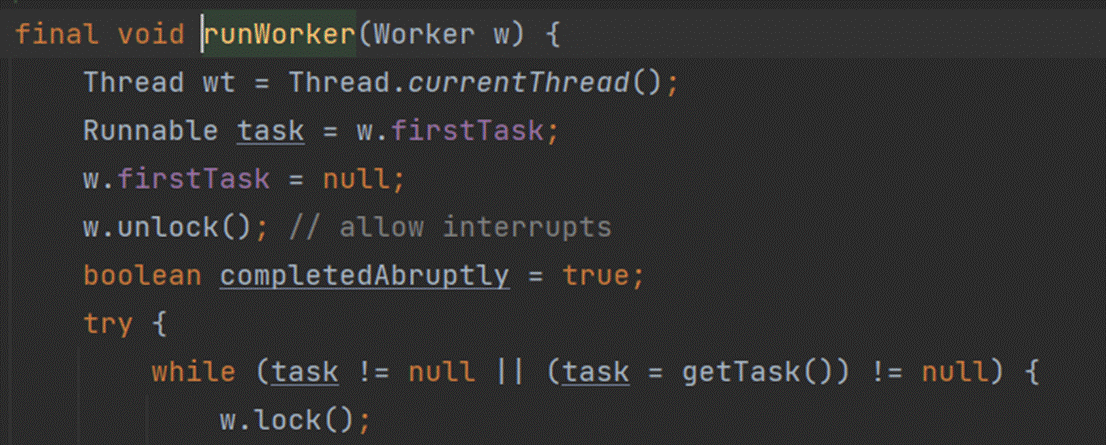
不断地的从阻塞队列中获取任务,主要调用的是workQueue.poll()方法或take(), 这两个方法都会阻塞式的从队列中获取元素,区别是poll()方法可以设置一个超时时间, take()不能设置超时时间,所以这也间接的使得线程池中的线程阻塞等待从而达到保活的效果。
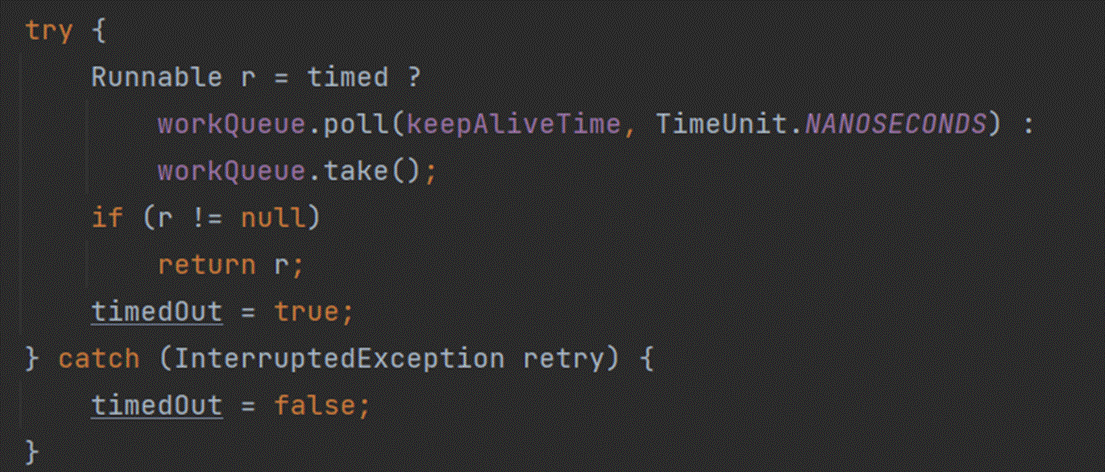
当然并不是线程池中的所有线程都需要一直保活,比如只有核心线程需要保活,非核心线程就不需要保活,那非核心线程是怎么回收的呢?
底层是这样的,当一个线程处理完当前任务后,就会开始去阻塞队列中获取任务,只不过,在调用poll或take方法之前, 会判断当前线程池中有多少个线程,如果多余核心线程数(也就是wc > corePlloSize),那么timed为true,此时当前线程就会调用poll()并设置超时时间来获取阻塞队列中的任务,这样一旦时间到了还没有获取到任务,那么poll方法获取到的r就是null,返回给上一级,runWorker()里的getTask方法就获取到null了,此时while循环就会退出。那么就会调用processWorkerExit()方法,remove当前线程
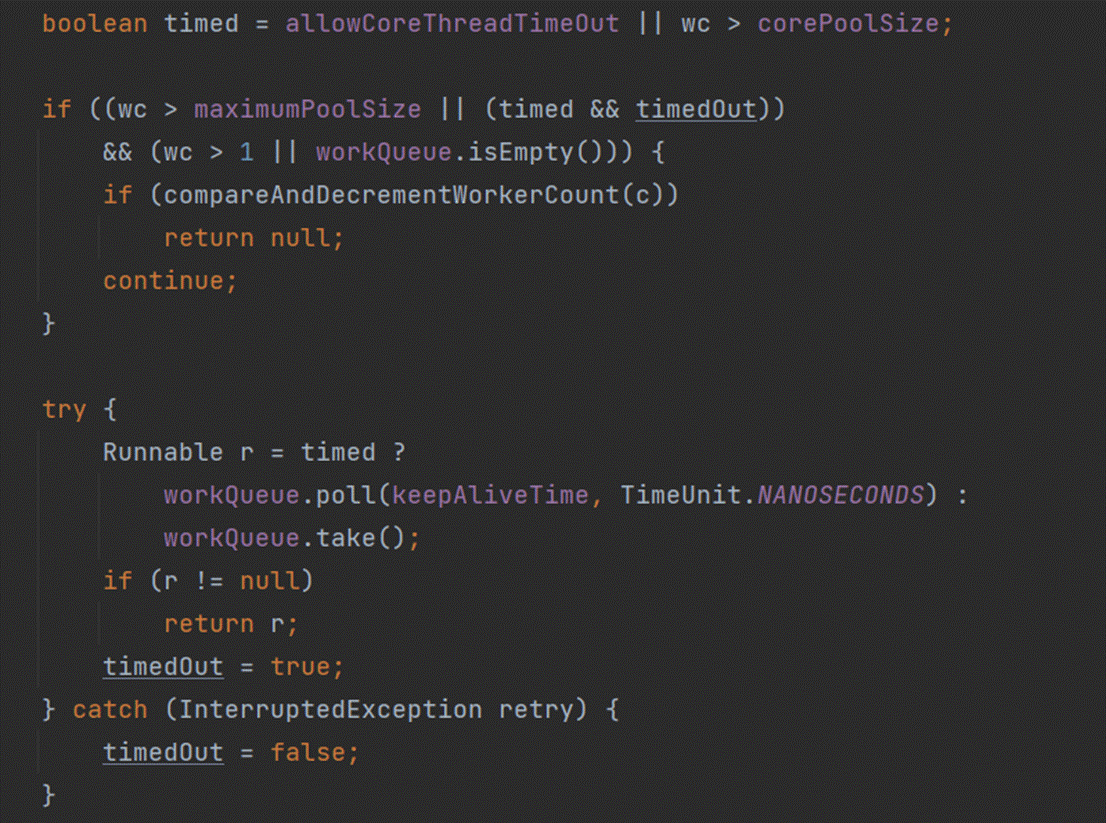
这里其实可以看到timed还有一个参数,allowCoreThreadTimeOut,这个主要是用来控制核心线程是否可以回收,默认是false,上面是讨论默认值false的情况,即核心线程不会超时。如果为true,工作线程可以全部销毁
实际上,虽然有核心线程数,但线程并没有区分是核心还是非核心,并不是先创建的就是核心,超过核心线程数后创建的就是非核心,最终保留哪些线程,完全随机。
线程池的关闭
shutdown方法会将线程池的状态设置为SHUTDOWN,线程池进入这个状态后,就拒绝再接受任务,然后会将剩余的任务全部执行完
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//检查是否可以关闭线程
checkShutdownAccess();
//设置线程池状态
advanceRunState(SHUTDOWN);
//尝试中断worker
interruptIdleWorkers();
//预留方法,留给子类实现
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
private void interruptIdleWorkers() {
interruptIdleWorkers(false);
}
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有的worker
for (Worker w : workers) {
Thread t = w.thread;
//先尝试调用w.tryLock(),如果获取到锁,就说明worker是空闲的,就可以直接中断它
//注意的是,worker自己本身实现了AQS同步框架,然后实现的类似锁的功能
//它实现的锁是不可重入的,所以如果worker在执行任务的时候,会先进行加锁,这里tryLock()就会返回false
if (!t.isInterrupted() && w.tryLock()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
shutdownNow做的比较绝,它先将线程池状态设置为STOP,然后拒绝所有提交的任务。最后中断左右正在运行中的worker,然后清空任务队列。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
//检测权限
advanceRunState(STOP);
//中断所有的worker
interruptWorkers();
//清空任务队列
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
private void interruptWorkers() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//遍历所有worker,然后调用中断方法
for (Worker w : workers)
w.interruptIfStarted();
} finally {
mainLock.unlock();
}
}
池化带来的问题
- 线程污染:如果线程池中的线程被用于执行不同类型的任务,而这些任务之间存在状态共享或依赖关系,可能会导致线程状态被污染,进而影响任务的正确执行。
- 内存泄漏:如果池化资源(如对象池中的对象)没有被正确地回收或重置,可能会导致内存泄漏。
当然,解决方法就是确保每次使用池化资源后,资源状态被正确重置,避免污染;正确回收,避免泄露。并且通过监控池化资源的使用情况,及时调优配置,以适应不同的负载和需求。
线程池大小怎么设置?
首先应该明确线程池大小设置的目的是什么?其实就是为了提高 CPU 的利用率
CPU利用率=CPU有效工作时间/CPU总的运行时间
如果线程池线程数量太小,当有大量请求需要处理,需要创建非核心线程池处理,导致系统响应比较慢,会影响用户体验,甚至会出现任务队列大量堆积任务导致OOM。
如果核心线程池数量太大,会导致其一直阻塞在那里等待任务队列的任务来执行,消耗内存。并且大量线程可能会同时抢占 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了执行效率。
根据线程数设置依据
最大线程数:原则上就是性能最高线程数,因为此时性能已经是最高,再设置比他大的线程数反而性能变低。极端情况下才会使用到最大线程数,正常情况下不应频繁出现超过核心线程数的创建。
核心线程数:基于性能考虑,及其他业务处理的最优效率考虑,估算平时的流量需要的线程数,设置核心线程数
阻塞队列:估算最大流量,设置阻塞队列长度
注意:需要通过压力测试来进行微调,只有经过压测的检验,才能最终保证的配置大小是准确的。
一般情况设置依据
一般用来计算核心线程数
CPU 密集型任务(N+1):
这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,多出来的一个线程是为了防止某些原因导致的线程阻塞(如IO操作,线程sleep,等待锁)而带来的影响。一旦某个线程被阻塞,释放了CPU资源,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
I/O 密集型任务(2N):
系统的大部分时间都在处理 IO 操作,此时线程可能会被阻塞,释放CPU资源,这时就可以将 CPU 交出给其它线程使用。因此在 IO 密集型任务的应用中,可以多配置一些线程,具体的计算方法:最佳线程数 = CPU核心数 * (1/CPU利用率) = CPU核心数 * (1 + (IO耗时/CPU耗时)),一般可设置为2N。
ExecutorService 线程池实例
但是阿里为什么不推荐使用Executors来创建线程池,这是为了让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
FixedThreadPool:
固定线程数的线程池。任何时间点,最多只有 nThreads 个线程处于活动状态执行任务。
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
为什么不建议使用?
使用无界队列 LinkedBlockingQueue(队列容量为 Integer.MAX_VALUE),运行中的线程池不会拒绝任务,即不会调用RejectedExecutionHandler.rejectedExecution()方法。maxThreadPoolSize 是无效参数,故将它的值设置为与 coreThreadPoolSize 一致。当添加任务的速度大于线程池处理任务的速度,可能会在队列堆积大量的请求,消耗很大的内存,甚至导致OOM。
keepAliveTime 也是无效参数,设置为0L,因为此线程池里所有线程都是核心线程,核心线程不会被回收(除非设置了executor.allowCoreThreadTimeOut(true))。
适用场景:适用于处理CPU密集型的任务,确保CPU在长期被工作线程使用的情况下,尽可能的少的分配线程,即适用执行长期的任务。需要注意的是,FixedThreadPool 不会拒绝任务,在任务比较多的时候会导致 OOM。
SingleThreadExecutor
只有一个线程的线程池。
public static ExecutionService newSingleThreadExecutor() {
return new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>());
}
为什么不建议使用?
使用无界队列 LinkedBlockingQueue。线程池只有一个运行的线程,新来的任务放入工作队列,线程处理完任务就循环从队列里获取任务执行。保证顺序的执行各个任务。
适用场景:适用于串行执行任务的场景,一个任务一个任务地执行。在任务比较多的时候也是会导致 OOM。
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>());
}
为什么不建议使用?
core是0,最大线程数是Integer.MAX_VALUE,因此当添加任务的速度大于线程池处理任务的速度,可能会创建大量的线程,极端情况下,这样会导致耗尽 cpu 和内存资源,甚至导致OOM。
使用没有容量的SynchronousQueue作为线程池工作队列,当线程池有空闲线程时,SynchronousQueue.offer(Runnable task)提交的任务会被空闲线程处理,否则会创建新的线程处理任务。
适用场景:用于并发执行大量短期的小任务。CachedThreadPool允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
ScheduledThreadPoolExecutor
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
在给定的延迟后运行任务,或者定期执行任务。
为什么不建议使用?
最大线程数是Integer.MAX_VALUE,因此当添加任务的速度大于线程池处理任务的速度,可能会创建大量的线程,极端情况下,这样会导致耗尽 cpu 和内存资源,甚至导致OOM。
关于作者
来自一线程序员Seven的探索与实践,持续学习迭代中~
本文已收录于我的个人博客:https://www.seven97.top
公众号:seven97,欢迎关注~
本文来自在线网站:seven的菜鸟成长之路,作者:seven,转载请注明原文链接:www.seven97.top