JAVA基础之八-方法变量作用域和编译器
本文主要讨论方法中变量作用域。不涉及类属性变量、静态变量、线程变量共享等。
虽然知道某类变量的作用域非常重要,但是没有太多需要说的,因为许多东西是显而易见,不言自明。
在大部分情况下,或者在老一点版本中,java语法看起来都比较正常,或者说相对古典。
但是随着JAVA版本的迭代,已经愈发向JAVASCRIPT靠近了-随意。 也许JCP想把JAVA编程后端的JS。
但要只知道,用为JS过于随意邋遢,才会有TypeScript。
一、前言
闲话少说。
在经典场景中,每个变量/属性的作用域都是相对稳定/固定的,例如:
1.方法可以引用实例变量,类静态变量
2.方法内部定义的变量,其它方法,外部类无法看到
这些规则都很容易理解和遵守。
但是随着JAVA的语法变迁,其中一个方面,函数/方法中变量作用域也变得更加灵活(随意)。
大部分程序员,其实很少在一个方法内部定义类,反而是一些开源的组件用得多,不太明白这些意图。
如果还要让方法和方法内部类共享变量,那么就会让代码看起来古怪,且非常类似于JS的经典问题:闭包。
来看一下以下一段代码:
@Override @Nullable public <T> T query(final String sql, final ResultSetExtractor<T> rse) throws DataAccessException { Assert.notNull(sql, "SQL must not be null"); Assert.notNull(rse, "ResultSetExtractor must not be null"); if (logger.isDebugEnabled()) { logger.debug("Executing SQL query [" + sql + "]"); } // Callback to execute the query. class QueryStatementCallback implements StatementCallback<T>, SqlProvider { @Override @Nullable public T doInStatement(Statement stmt) throws SQLException { ResultSet rs = null; try { rs = stmt.executeQuery(sql); return rse.extractData(rs); } finally { JdbcUtils.closeResultSet(rs); } } @Override public String getSql() { return sql; } } return execute(new QueryStatementCallback(), true); }
这是Spring 6.2.0-SNAPSHOT 中 spring-jdbc的 org.springframework.jdbc.core.JdbcTemplate#query(String, ResultSetExtractor<T>) 方法的代码。
在这段代码中,spring直接定义一个内部类 QueryStatementCallback 。
妙的是QueryStatementCallback 直接利用了query中定义的参数rse。
这种使用方式和js的对方法变量的使用(闭包)如出一辙。至少外表上是一样的。
到现在为止,我们知道这样一个事实:至少J17中可以这么写(其它没有研究)。
接下来,纯粹是出于技术人好奇,有几点:
1.这个对性能有什么影响
2.如何实现的?
3.如果性能没有好处,为什么要那么搞?
二、模仿例子
为了便于了解这个问题,创建了一个类似的例子,方便一些。
package study.base.varscope; @FunctionalInterface public interface ISum { long sum(); } /** * 测试方法内的变量作用域,类似于js的闭包 */ public class TestVarScope { public void test() { //创建一个有1000个元素的数组,每个元素都是介于1~999之间的随机数 int[] arr = new int[1000]; Random random = new Random(); for (int i = 0; i < 1000; i++) { arr[i] = random.nextInt(1,1000); } class SumClass implements ISum { @Override public long sum() { //累加 arr long total = 0; for (int i : arr) { total += i; } return total; } } SumClass sc=new SumClass(); long total=sc.sum(); System.out.println(total); } public static void main(String[] args) { TestVarScope testVarScope = new TestVarScope(); testVarScope.test(); } }
没有编译错误,可以执行。
所以奥妙一定在于编译器上,只要看看编译后的东西就明白了。
class文件
可以看到含$是方法内部类.
再看看 TestVarScope$1SumClass.class的内容
先看反编译内容
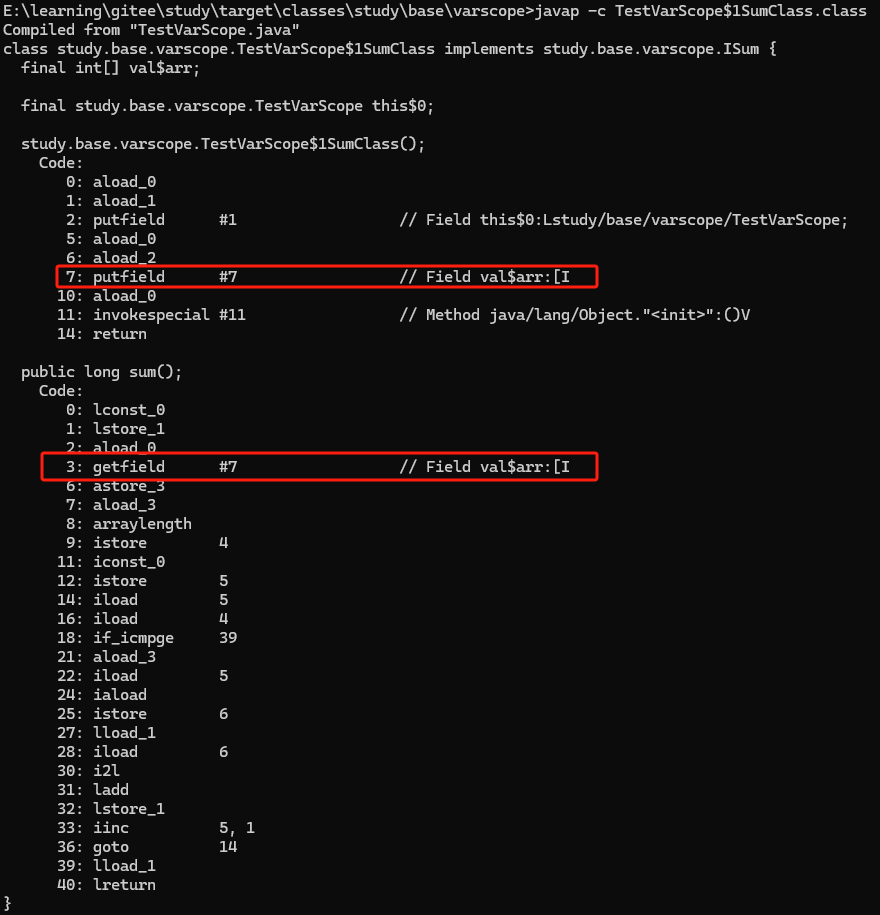
再看私有成员

结合以上两张图,可以比较肯定地推测出如下:
内部类SumClass被改写了:
a.SumClass新增了一个私有final的数组 val$arr,用于存储上级对象的属性(数组)
b.SumClass有一个带两个参数的构造函数,前后分别是上级类的实例,需要接受的数组
c.sum()方法,访问val$arr,以便进行汇总
再用三方工具(jadx)可以查看出:
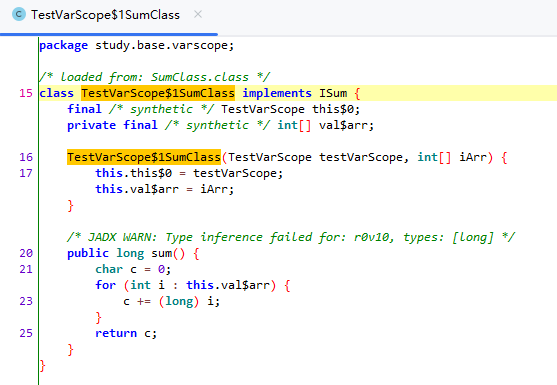
和预想的一致。
注:如果用idea(2024.2.1)的默认反编译工具,会得到错误的结果,所以用那个来看源码有点危险,倒是eclipse的做得不错。
以下是eclipse的class File viewer:
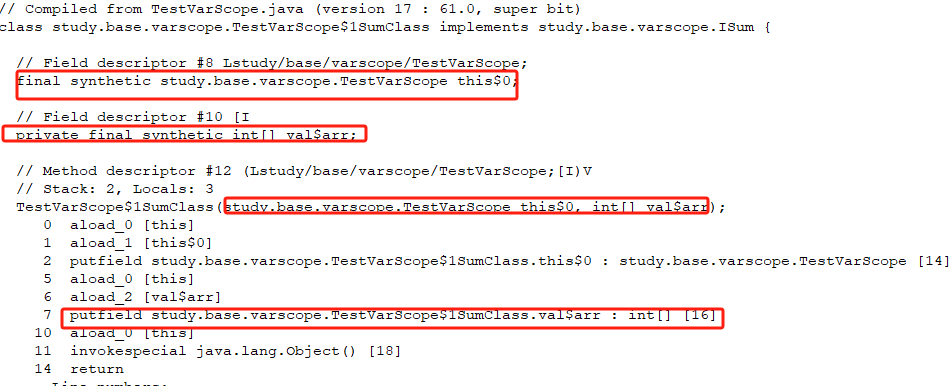
针对前一章节的问题,可以如下作答:
1.这个对性能有什么影响
基本没有什么影响。
2.如何实现的?
如上,通过编译器改写内部类和上级类方法来完成,一切功劳在于编译器.
3.如果性能没有好处,为什么要那么搞?
方便,或者偷懒而已。
三、小结
java的语言越来越随意,通过编译器的功能(或者所谓的语法糖),可以实现类似js那样随意的效果。
就本文所阐述的问题,本质上并不是说内部类可以访问上级的属性,而是一种错觉,在语法上让我们以为可以访问。
就我个人而言,并不喜欢这些隐藏了实现的编码方式,大概因为开始编程的时候,学习的都是古典语法。
现在的一些新的东西,虽然某些情况下会工程上的某些好处,但是反作用也是明显的:复杂化编译器;有可能培养不是很
好的编码习惯。
关于方法变量的作用域问题,目前暂时没有其它可以说的。