C++11 标准库 线程库<thread>梳理
<thread>
this_thread命名空间
在C++11中不仅添加了线程类,还添加了一个关于线程的命名空间std::this_thread,在这个命名空间中提供了四个公共的成员函数,通过这些成员函数就可以对当前线程进行相关的操作了。
头文件

1. get_id()
函数原型
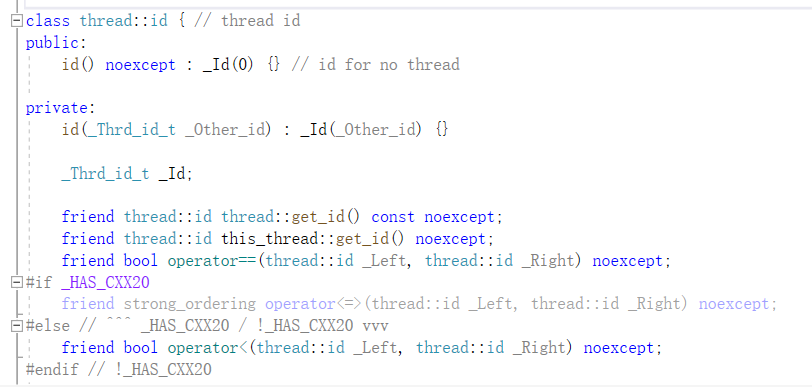
thread::id get_id() noexcept;
get_id可以获取主调线程的id,即在主线程中获取到的是主线程id,在子线程中获取到的是子线程id.
注:在VS中,线程id被封装了一层,是一个结构体.
2. sleep_for()
命名空间this_thread中提供了一个休眠函数sleep_for(),调用这个函数的线程会马上从运行态变成阻塞态并在这种状态下休眠一定的时长,因为阻塞态的线程已经让出了CPU资源,代码也不会被执行,所以线程休眠过程中对CPU来说没有任何负担。程序休眠完成之后,会从阻塞态重新变成就绪态,就绪态的线程需要再次争抢CPU时间片,抢到之后才会变成运行态,这时候程序才会继续向下运行。
这个函数是函数原型如下,参数需要指定一个休眠时长,是一个时间段:
template <class Rep, class Period>
void sleep_for (const chrono::duration<Rep,Period>& rel_time);
示例:
#include<thread>
#include<chrono>
int main() {
std::chrono::steady_clock::time_point start = std::chrono::steady_clock::now();
std::this_thread::sleep_for(std::chrono::seconds());
std::chrono::steady_clock::time_point end = std::chrono::steady_clock::now();
std::chrono::nanoseconds ret = end - start;
std::cout<<"计时器计时时长:"<<ret.count()<<"纳秒"<<ret.count()/ 1000000000<<"秒" << "\n";
}
3. sleep_until()
名空间this_thread中提供了另一个休眠函数sleep_until(),功能和sleep_for几乎类似,区别是sleep_until的参数是时间点.即休眠到某个时间点.
VS中sleep_for调用了sleep_until实现.
函数原型:
template <class Clock, class Duration>
void sleep_until (const chrono::time_point<Clock,Duration>& abs_time);
#include<thread>
#include<chrono>
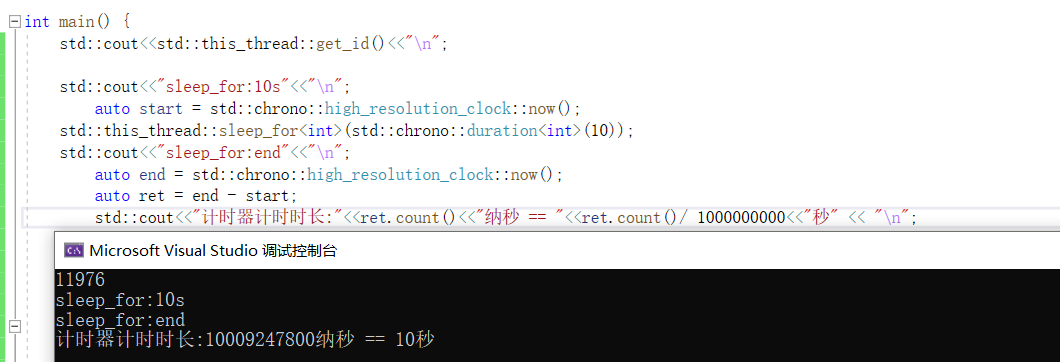
int main() {
std::cout<<std::this_thread::get_id()<<"\n";
std::cout<<"sleep_until 10 seconds after the currend time, start:"<<"\n";
std::chrono::steady_clock::time_point start = std::chrono::steady_clock::now();
std::this_thread::sleep_until(std::chrono::system_clock::now()+std::chrono::seconds(10));
std::chrono::steady_clock::time_point end = std::chrono::steady_clock::now();
std::cout<<"sleep_for:end"<<"\n";
std::chrono::nanoseconds ret = end - start;
std::cout << "计时器计时时长:" << ret.count() << "纳秒 ~=" << ret.count() / 1000000000 << "秒" << "\n";
}

4. yield()
描述:在线程中调用这个函数之后,处于运行态的线程会主动让出自己已经抢到的CPU时间片,最终变为就绪态.线程调用了yield()之后会主动放弃CPU使用权,但是这个变为就绪态的线程会马上参与到下一轮CPU的抢夺战中,不排除它能继续抢到CPU时间片的情况
注意:只是"暂停"继续执行,而不是结束线程运行从头开始
函数原型:
void yield() noexcept;
例程:
#include<iostream>
#include<thread>
#include<chrono>
#include<cstdlib>
#pragma warning(disable:4996)
void func1() {
do {
std::cout << std::this_thread::get_id() << "\n";
} while (true);
}
void func2() {
do {
std::this_thread::yield();
std::cout << std::this_thread::get_id() << "\n";
} while (true);
}
int main() {
std::thread t1(func1);
std::thread t2(func2);
t1.join();
t2.join();
return 0;
}

可以发现,线程主动让出时间片后,其他线程竞争力概率提高.(与操作系统调度方式有关,概率问题)
使用场景:
-
避免一个线程长时间占用CPU资源,从而导致多线程处理性能下降
在极端情况下,如果当前线程占用CPU资源不释放就会导致其他线程中的任务无法被处理,或者该线程每次都能抢到CPU时间片,导致其他线程中的任务没有机会被执行,此时可以使用yield缓解.
-
没有满足继续执行的某种条件时,应主动放弃使用权.
thread类
构造函数:
thread() noexcept; //空线程对象
thread( thread&& other ) noexcept; //移动构造
template< class Function, class... Args >
explicit thread( Function&& f, Args&&... args ); //常规构造
thread( const thread& ) = delete; //禁止拷贝
-
线程传非静态成员函数时,语法为
//法一: 定义的对象; 线程对象(&类::成员函数,对象/&对象,参数...);因为成员函数比较特殊,不能像普通函数那样函数名可以自动转换成指针,必须要取地址&函数名才可以.
拿到成员函数的地址需要使用到指针和地址相关的操作。在C++中,获取成员函数的地址并调用它是一种相对复杂的过程,因为涉及到了类的实例(对象)和方法的绑定问题。
例程:
class A { public: static void fun1(){} void fun2(){std::cout<<"func2()"<<"\n"; } }; int main() { A a; std::thread t1(&A::fun2,a); std::thread t2(&A::fun2,&a); //传地址更优 t1.join(); t2.join(); return 0;}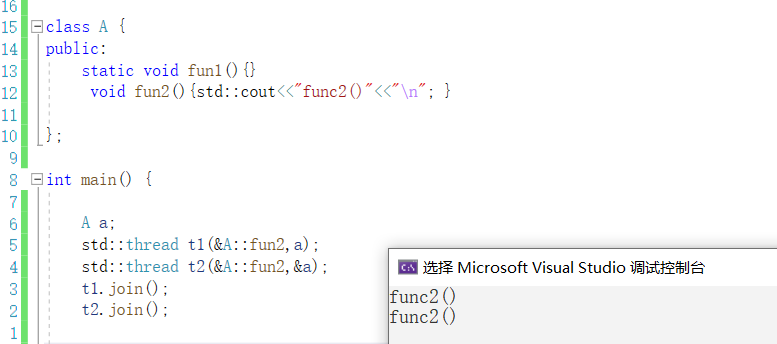
//法二: 线程对象(std::bind(&类::成员函数,对象/&对象,参数...),参数...);
-
静态成员函数语法
线程对象(&类::成员函数,参数...); //静态方法&可加可不加静态成员函数简单,只需要对函数取地址即可
类方法
1. get_id()
函数原型:
std::thread::id get_id() const noexcept;
thread中的类方法get_id()和this_thread::get_id();功能类似,用于返回thread对象的id.this_thread中的功能是返回主调线程的id.
2. join()
功能:
join()字面意思是连接一个线程,主动地等待线程的终止(线程阻塞)。在某个线程中通过子线程对象调用join()函数,调用这个函数的线程被阻塞,但是子线程对象中的任务函数会继续执行,当任务执行完毕之后join()会清理当前子线程中的相关资源然后返回,同时,调用该函数的线程解除阻塞继续向下执行。
函数原型:
void join();
为什么需要join:
- 多线程中,未分离的子线程在结束后会等待将处理结果返回给主线程,如果此时主线程结束,则进程所有资源都会回收,与此同时子线程还在处理数据返回,之后子线程修必然要处理数据,就会发生越界.
- 同理,线程处理任务过程中,如果主线程结束,资源回收,子线程之后也是非法访问.
join需要注意的几点.
-
空线程不需要join,因为空线程对象没有任务,并没有创建真实线程(C++线程对象是用于管理系统线程调用)
join了会报错

-
注意,函数体为空的线程是需要调用join方法,因为真实线程被创建了.
-
move后的线程对象也不需要调用join方法,因为资源被转移到别的线程对象了.
3. detach()
描述:
detach()函数的作用是进行线程分离,分离主线程和创建出的子线程。在线程分离之后,主线程退出也会一并销毁创建出的所有子线程,在主线程退出之前,它可以脱离主线程继续独立的运行,任务执行完毕之后,这个子线程会自动释放自己占用的系统资源。
线程分离函数detach()不会阻塞线程,子线程和主线程分离之后,在主线程中就不能再对这个子线程做任何控制了
函数原型:
void detach();
注意:
-
detach就算分离,使用的资源依旧属于进程,主线程结束,资源被回收后,detach的子线程如果未执行完毕,之后的行为将是未定义的.在win10中子线程在主线程结束后同步结束.
主线程结束后,主进程也随着同步退出,资源回收.detach仅仅能起到提前回收的作用.
测试例程:
void func2() {
do {
std::cout << std::this_thread::get_id() << "\n";
_sleep(100);
} while (true);
}
int main() {
std::thread t2(func2);
t2.detach();
_sleep(1000);
return 0;}
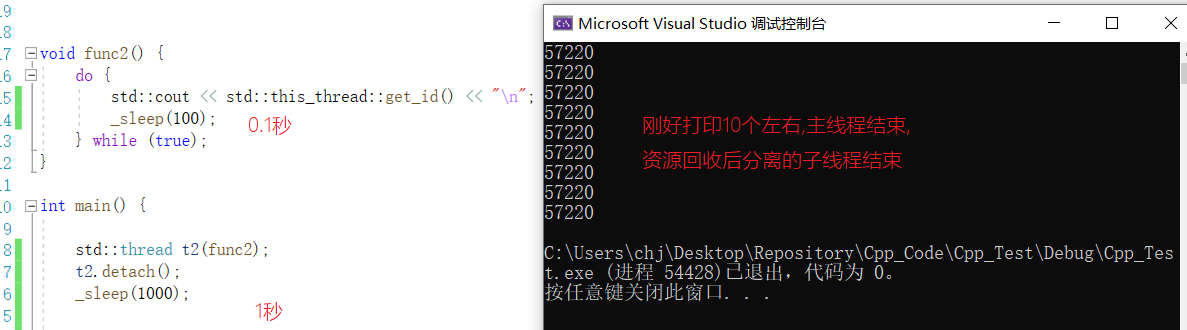
- detach后无法再通过线程对象查看子线程id

很少会分离线程,分离后线程控制更加麻烦,需要处理的更多
4. joinable()
函数原型:
bool joinable() const noexcept;
joinable()函数用于判断主线程和子线程是否处理关联(连接)状态,一般情况下,二者之间的关系处于关联状态,该函数返回一个布尔类型:
返回值为true:主线程和子线程之间有关联(连接)关系
返回值为false:主线程和子线程之间没有关联(连接)关系
一般情况下,只有线程有任务时,joinable返回真;其他情况,如空线程对象,分离的线程对象以及join之后的线程对象则返回假.
任务执行完,待返回的线程也属于关联状态.
使用场景:
批量创建线程,如果线程后续没有分配任务,在join时程序后报错.因此可以在join前判断是否关联,关联才join,这样程序就不会奔溃.
std::thread t1;
if (t1.joinable() == true)
{
t1.join();
}
总结:
- 在创建的子线程对象的时候,如果没有指定任务函数,那么子线程不会启动,主线程和这个子线程也不会进行连接
- 在创建的子线程对象的时候,如果指定了任务函数,子线程启动并执行任务,主线程和这个子线程自动连接成功
- 子线程调用了detach()函数之后,父子线程分离,同时二者的连接断开,调用joinable()返回false
- 在子线程调用了join()函数,子线程中的任务函数继续执行,直到任务处理完毕,这时join()会清理(回收当前子线程的相关资源,所以这个子线程和主线程的连接也就断开了,因此,调用join()之后再调用joinable()会返回false。
5. operator=
线程对象不允许拷贝,只能转移
函数原型
// move (1)
thread& operator= (thread&& other) noexcept;
// copy [deleted] (2)
thread& operator= (const other&) = delete;
6. hardware_concurrency(static)
thread线程类还提供了一个静态方法hardware_concurrency,用于获取当前计算机的CPU核心数,根据这个结果在程序中创建出数量相等的线程,每个线程独自占有一个CPU核心,这些线程就不用分时复用CPU时间片,此时程序的并发效率是最高的。
线程数对应CPU的逻辑核心数,现代个人计算机一般只有一个物理CPU.然后CPU内有多个核心(真多核并行).这些核心能过模拟出多个核心(并发),叫做虚拟核心,计算机中的线程数一般都是虚拟核心数
在操作系统看来,核心数一般就是指虚拟核心数.
以一块8核16线程CPU为例:
一块CPU内有8个核心,每个核心都能模拟出2个虚拟核心,每个核心对应一个线程,即8核16线程.
CPU的核心数和线程数傻傻分不清,一文科普,清晰明了_cpu核心数和线程数-CSDN博客
函数原型:
static unsigned hardware_concurrency() noexcept;
多线程的两种计算场景
1. IO密集型程序
IO密集型程序主要特点是频繁的输入/输出操作,如读写文件、网络通信等。这些操作通常需要花费大量时间等待外部设备完成数据传输,导致CPU空闲。因此,IO密集型程序通常在等待IO操作完成时,会释放CPU资源给其他进程使用。
例如,一个大型文件服务器或数据库系统就是典型的IO密集型程序。在处理大量请求时,它们需要频繁地读写磁盘,使得CPU常常处于空闲状态。
2. CPU密集型程序
相对地,CPU密集型程序主要是进行大量的数学计算、逻辑运算等需要消耗大量CPU资源的任务。这些任务通常不涉及大量的IO操作,而是专注于利用CPU进行高速处理。
例如,科学计算、大数据分析、机器学习等领域的应用就属于CPU密集型程序。它们需要大量的数学计算和逻辑运算,对CPU资源的需求极高。
实现与优化
对于IO密集型程序,关键在于减少不必要的CPU使用,通过多线程、异步IO等技术来提高效率。由于IO操作通常成为性能瓶颈,因此应优先处理这些操作以降低延迟。
而对于CPU密集型程序,优化的重点在于最大化CPU利用率。这可以通过并行计算、多线程等技术实现。通过将任务分解为多个子任务并分配给多个核心同时处理,可以显著提高程序的运行速度。
引用参考 :
https://subingwen.cn/tags/C-11/
https://zh.cppreference.com/w/cpp
https://legacy.cplusplus.com/