AI大模型企业应用实战(19)-RAG应用框架和解析器
1 开源解析和拆分文档
第三方工具去对文件解析拆分,将文件内容给提取出来,并将我们的文档内容去拆分成一个小的chunk。常见的PDF word mark down, JSON、HTML。都可以有很好的一些模块去把这些文件去进行一个东西去提取。
1.1 优势
- 支持丰富的文档类型
- 每种文档多样化选择
- 与开源框架无缝集成
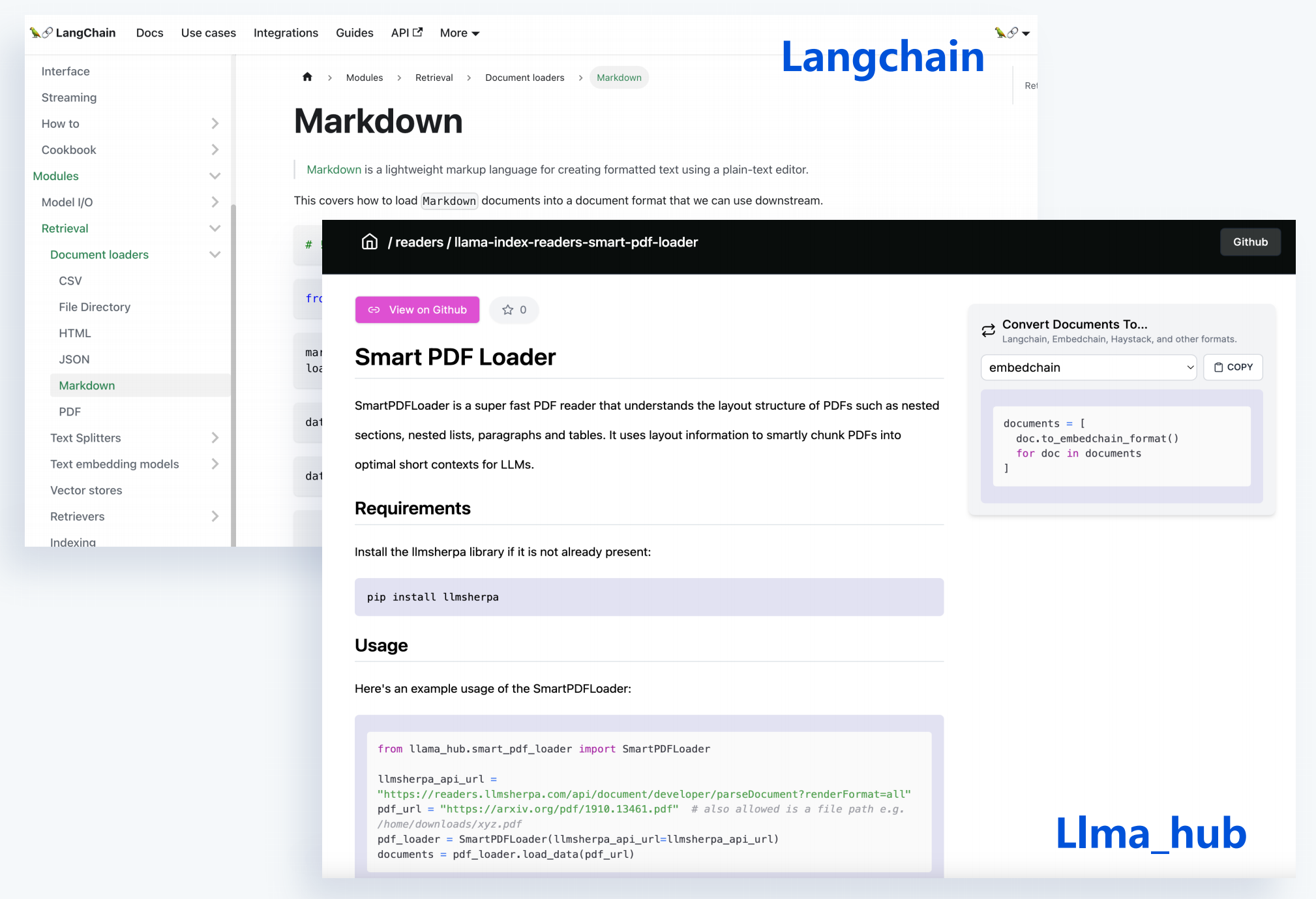
但有时效果非常差,来内容跟原始的文件内容差别大。
2 PDF格式多样性
复杂多变的文档格式,提高解析效果十分困难。
3 复杂文档格式解析问题
文档内容质量将很大程度影响最终效果,文档处理过程涉及问题:
3.1 内容不完整
对文档的内容进行提取的时候,可能会发现提取出来的文档它的内容是会被截断的。跨页形式,提取出来它的上下页其实两部分内容就会被截断,导致文档内部分内容丢失,我们去解析图片或者是说双栏复杂的这种格式。它会有一部分内容的丢失。
3.2 内容错误
同一页PDF文件可能存在文本、表格、图片等混合。
PDF解析过程中,同一页它不同段落其实会也会有不同标准的一些格式。按通用格式去提取解析就遇到同页不同段落格式不标准情况。
3.3 文档格式
像常见PDF md文件,需要去支持把这些各类型的文档格式的文件都给提取。
3,4 边界场景
代码块还有单元格这些,都是我们去去解析一个复杂文档格式中会遇到一些问题。
4 PDF内容提取流程
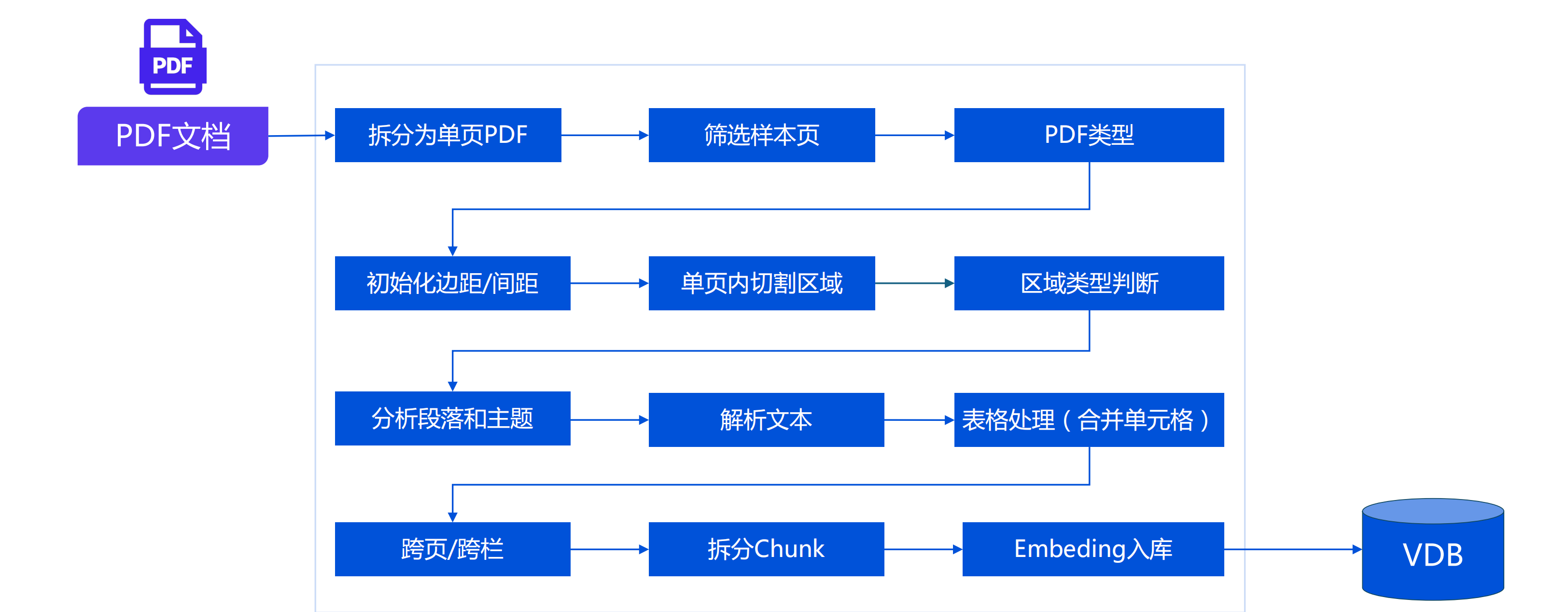
5 为啥解析文档后需要做知识片段拆分?
5.1 Token限制
- 绝大部分开源限制 <= 512 Tokens
- bge_base、e5_large、m3e_base、text2vector_large_chinese、multilingnal-e5-base..
5.2 效果影响
- 召回效果:有限向量维度下表达较多的文档信息易产生失真
- 回答效果:召回内容中包含与问题无关信息对LLM增加干扰
5.3 成本控制
- LLM费用:按照Token计费
- 网络费用:按照流量计费
6 Chunk拆分对最终效果的影响
Chunk太长
信息压缩失真
Chunk太短
表达缺失上下文;匹配分数容易变高
Chunk跨主题
内容关系脱节
原文连续内容(含表格)被截断
单个Chunk信息表达不完整,或含义相反
干扰信息
如空白、HTML、XML等格式,同等长度下减少有效信息、增加干扰信息
主题和关系丢失
缺失了主题和知识点之间的关系
7 改进知识的拆分方案

关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
- LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
本文由博客一文多发平台 OpenWrite 发布!