03-SparkSQL入门
0 Shark
Spark 的一个组件,用于大规模数据分析的 SQL 查询引擎。Shark 提供了一种基于 SQL 的交互式查询方式,可以让用户轻松地对大规模数据集进行查询和分析。Shark 基于 Hive 项目,使用 Hive 的元数据存储和查询语法,并基于Hive进行了性能优化和扩展。
0.1 设计
灵感来自 Google 的 Dremel 系统:
- 将数据存储在列式存储引擎
- 使用分布式计算引擎进行查询
Shark 采用类似架构并使用 Spark 作为计算引擎,使 Shark 具有很高查询性能和可扩展性。
0.2 缺陷
Shark 在 Spark 1.0 发布之后被正式弃用,Shark 的性能和可扩展性相对于 Spark SQL 来说存在一些局限性。以下是一些导致 Shark 被淘汰因素:
① 数据模型
Shark 基于 Hive 数据模型,使用 Hive 的元数据存储和查询语法,导致查询语句执行效率较低。
② 计算模型
Shark 采用类似 Dremel 的列式存储引擎,虽能提高查询效率,但也导致更高内存开销和更复杂代码实现。
③ 性能和可扩展性
Shark性能和可扩展性相对Spark SQL存在一些局限性,如不支持流计算、新的数据源。
因此,Spark社区放弃 Shark,转而对 Spark SQL 更深入研究,以提高查询性能和可扩展性,并支持更多数据源和计算模型。因此,Spark SQL 取代 Shark 成为 Spark 生态系统的 SQL 查询引擎。
1 概述
Spark SQL,结构化数据处理的Spark模块。
- Spark SQL官网
- 误区:Spark SQL就是一个SQL处理框架,不仅是处理 SQL

自 Spark 1.0 版本(2014 年 4 月)以来成为核心发布的一部分。
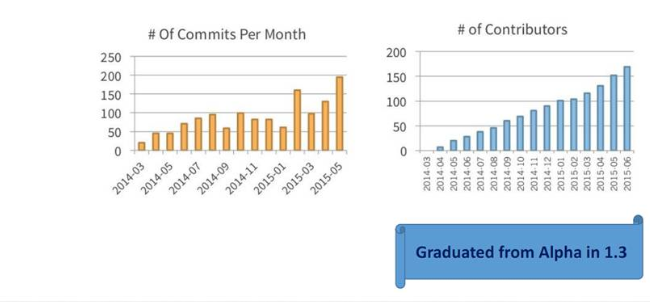
与基本的Spark RDD API不同,Spark SQL提供的接口为Spark提供了有关数据和正在执行的计算的更多信息。在内部,Spark SQL使用这些额外的信息执行额外的优化。与Spark SQL交互的几种方法包括SQL和Dataset API。在计算结果时,无论使用哪种API /语言表达计算,都使用相同的执行引擎。这种统一意味着开发人员可以根据提供最自然的方式表达给定转换的API轻松切换。
2 用途
执行SQL查询。 Spark SQL也可用于从Hive读取数据。当从另一种编程语言中运行SQL时,结果将作为Dataset/DataFrame返回。还可使用命令行或通过JDBC/ODBC与SQL接口交互。
3 特性
3.1 集成性
Spark SQL可让你在Spark程序用SQL或熟悉的DataFrame API查询结构化数据。可在Java、Scala、Python和R中使用。它可使SQL查询与Spark程序无缝混合。
3.2 统一数据访问
DataFrames和SQL提供了一种通用方式访问各种数据源如Hive、Avro、Parquet、ORC、JSON和JDBC。甚至可在这些数据源之间联接数据。
spark.read.format("json").load(path)
spark.read.format("text").load(path)
spark.read.format("parquet").load(path)
spark.read.format("json").option("...","...").load(path)
3.3 兼容Hive
Spark SQL支持HiveQL语法以及Hive SerDes和UDF,使你可以访问现有的Hive仓库并在其上运行SQL或HiveQL查询。
如果你想把Hive的作业迁移到Spark SQL,这样的话,迁移成本就会低很多
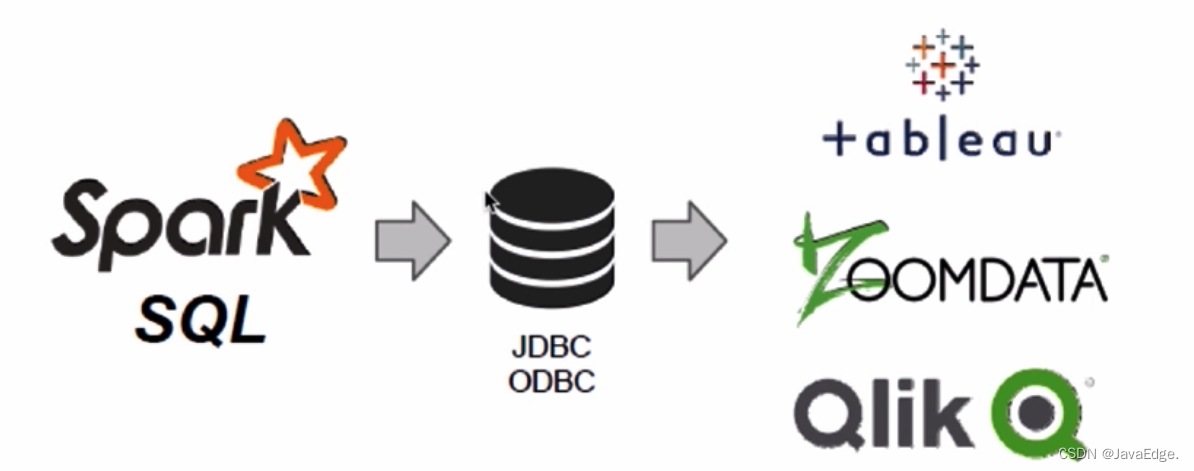
3.4 标准的数据连接
Spark SQL提供了服务器模式,可为BI提供行业标准的JDBC和ODBC连接功能。通过该功能,可通过JDBC或ODBC连接到Spark SQL并进行数据查询和操作。
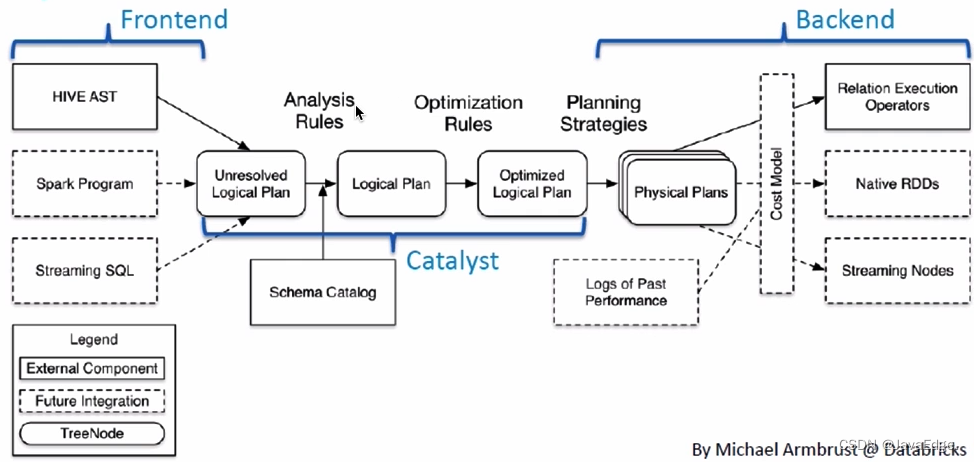
4 架构
5 spark-submit 启动应用程序
一旦绑定用户应用程序,就能用spark-submit启动。该脚本负责使用 Spark 及其依赖项设置类路径,并支持 Spark 支持的不同集群管理器和部署模式:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
常用选项:
--class:应用程序入口点(如org.apache.spark.examples.SparkPi)--master:集群的主 URLspark://23.195.26.187:7077--deploy-mode: 在工作节点部署你的驱动程序 (cluster) 还是在本地作为外部客户端 (client) (默认:client)--conf:K=V 格式的任意 Spark 配置属性。对于包含空格的值,将“key=value”括在引号中(如图所示)。多个配置应作为单独的参数传递。(如--conf <key>=<value> --conf <key2>=<value2>)application-jar:包含你的应用程序和所有依赖项的捆绑 jar 的路径。该 URL 必须在你的集群内全局可见,如路径hdfs://或file://存在于所有节点上的路径
#!/usr/bin/env bash
# 检查Spark SQL的环境变量
if [[ -z "${SPARK_HOME}" ]]; then
echo "SPARK_HOME is not set!" >&2
exit 1
fi
# 设置Spark SQL的类路径
export SPARK_CLASSPATH="${SPARK_HOME}/jars/*:${SPARK_HOME}/conf"
# 启动Spark SQL的服务
exec "${SPARK_HOME}/bin/spark-submit" \
--class org.apache.spark.sql.hive.thriftserver.HiveThriftServer2 \
--name "Spark SQL Thrift Server" \
--master yarn \
--deploy-mode client \
--conf "spark.sql.hive.thriftServer.singleSession=true" \
--conf "spark.sql.hive.thriftServer.incrementalCollect=true" \
"${SPARK_HOME}/jars/spark-hive-thriftserver.jar" \
"$@"
- 检查Spark SQL的环境变量,如果没有设置则退出脚本。
- 设置Spark SQL的类路径,包含了Spark的jar包和配置文件。
- 使用spark-submit命令启动Spark SQL的服务。
- 指定启动类为HiveThriftServer2,该类负责启动Spark SQL的Thrift Server。
- 指定服务名称为"Spark SQL Thrift Server"。
- 指定Spark运行模式为yarn,提交任务到yarn集群中运行。
- 指定部署模式为client,即客户端模式。
- 设置Spark SQL的配置项,例如singleSession和incrementalCollect。
- 指定启动的jar包为spark-hive-thriftserver.jar。
- 最后传入用户输入的参数。
关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都技术专家兼架构,多家大厂后端一线研发经验,各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
- 中央/分销预订系统性能优化
- 活动&优惠券等营销中台建设
- 交易平台及数据中台等架构和开发设计
- 车联网核心平台-物联网连接平台、大数据平台架构设计及优化
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
本文由博客一文多发平台 OpenWrite 发布!
热门相关:我的学姐会魔法 永恒王权 美女总裁之贴身高手 傲天弃少 全民女神,重生腹黑千金