x86平台SIMD编程入门(4):整型指令
1、算术指令
| 算术类型 | 函数示例 |
|---|---|
| 加 | _mm_add_epi32、_mm256_sub_epi16 |
| 减 | _mm_sub_epi32、_mm256_sub_epi16 |
| 乘 | _mm_mul_epi32、_mm_mullo_epi32 |
| 除 | 无 |
| 水平加/减 | _mm_hadd_epi16、_mm256_hsub_epi32 |
| 饱和加/减 | _mm_adds_epi8、_mm256_subs_epi16 |
| 最大/最小值 | _mm_max_epu8、_mm256_min_epi32 |
| 绝对值 | _mm_abs_epi16、_mm256_abs_epi32 |
| 平均值 | _mm_avg_epu16、_mm256_avg_epu8 |
没有整数除法的SIMD指令。如果要将所有通道都除以一个编译时常数,可以使用一个小技巧:编写一个函数,将相同类型的标量除以该常数,然后使用Compiler Explorer编译成汇编指令,最后移植成相应SIMD指令。例如,要把uint16_t类型的整数除以11,则上述技巧的操作过程如下:
// STEP1: 写一个计算除法的普通函数
#include <cstdint>
uint16_t div11(uint16_t a)
{
return a / 11;
}
// STEP2: 将上面的代码复制到Compiler Explorer中,生成对应的汇编代码如下
div11(unsigned short):
push rbp
mov rbp, rsp
mov eax, edi
mov WORD PTR [rbp-4], ax
movzx eax, WORD PTR [rbp-4]
movzx eax, ax
imul eax, eax, 47663
shr eax, 16
shr ax, 3
pop rbp
ret
// STEP3: 参考上述汇编代码中的计算方式,编写对应的SIMD指令
__m128i div_by_11_epu16(__m128i x)
{
x = _mm_mulhi_epu16(x, _mm_set1_epi16((short)47663));
return _mm_srli_epi16(x, 3);
}
整数指令中有一类比较“奇怪”指令,是_mm_sad_epu8(SSE2)和_mm256_sad_epu8(AVX2),它们的运算逻辑相当于以下代码:
array<uint64_t, 4> avx2_sad_epu8(array<uint8_t, 32> a, array<uint8_t, 32> b)
{
array<uint64_t, 4> result;
for (int i = 0; i < 4; i++)
{
uint16_t totalAbsDiff = 0;
for (int j = 0; j < 8; j++)
{
const uint8_t va = a[i * 8 + j];
const uint8_t vb = b[i * 8 + j];
const int absDiff = abs((int)va - (int)vb);
totalAbsDiff += (uint16_t)absDiff;
}
result[i] = totalAbsDiff;
}
return result;
}
它们可能最初是为了视频编码器设计的,用于估算压缩误差。不过这些指令也可以用来做与视频编码无关的事,例如用它们来计算所有字节的总和就非常快速,只要把_mm_sad_epu8第二个参数设为全零向量,然后使用_mm_add_epi64累加结果即可。
2、比较指令
| 运算符 | 函数示例 |
|---|---|
| 等于 | _mm_cmpeq_epi8、_mm256_cmpeq_epi64 |
| 大于 | _mm_cmpgt_epi8、_mm256_cmpgt_epi64 |
| 小于 | _mm_cmplt_epi8、_mm_cmplt_epi16、_mm_cmplt_epi32 |
整数比较指令只有全通道的版本。与浮点数比较指令类似,整数比较结果也会被设置成全0或者全1。全1的有符号整数等于-1,若要统计比较结果为真的数量,一个技巧是使用下面代码所示的整数减法。使用这个技巧时要注意累加器的整数溢出问题,解决这个问题的一种方法是嵌套循环,内循环保证累加器不会溢出,外循环把内循环的累加结果投射到更宽的整数类型上。
const __m128i cmp = _mm_cmpgt_epi32(val, threshold);
acc = _mm_sub_epi32(acc, cmp); // acc是保存计数的累加器
没有小于等于或大于等于的整数比较指令。如果要比较a <= b这样情况,可以使用min(a, b) == a这样的方法来实现。
没有无符号整数的比较指令。如果有需要,可以参考下面的方法手动实现:
__m128i cmpgt_epu16(__m128i a, __m128i b)
{
const __m128i highBit = _mm_set1_epi16((short)0x8000);
a = _mm_xor_si128(a, highBit);
b = _mm_xor_si128(b, highBit);
return _mm_cmpgt_epi16(a, b);
}
movemask指令只有8位整数的版本。如果想要在通用寄存器中获得32位整数的比较结果,一种变通的方法是先把__m128i重解释转换成__m128然后使用_mm_movemask_ps(对于64位结果则是先转换成__m128d然后使用_mm_movemask_pd)。
3、移位指令
3.1、寄存器移位
| 函数示例 | 说明 |
|---|---|
_mm_slli_si128 |
对__m128i寄存器整体进行左移 |
_mm_srli_si128 |
对__m128i寄存器整体进行右移 |
_mm256_slli_si256 |
对__m256i寄存器中的高低两个128位数据分别进行左移(如果要对256位数据整体移位,可以参考这个stackoverflow链接) |
_mm256_srli_si256 |
对__m256i寄存器中的高低两个128位数据分别进行右移 |
_mm_alignr_pi8 |
将两个__m64输入向量首尾拼接后右移 |
_mm_alignr_epi8 |
将两个__m128i输入向量首尾拼接后右移 |
_mm256_alignr_epi8 |
将两个__m256i输入向量中的高低128位分别首尾拼接后右移 |
上表中的最小移位步长都是1字节。
3.2、通道移位
下表所列的函数是对每个通道都做等长的移位操作。例如_mm_srli_epi16(x, 4)会把通道中的0x8015转换为0x0801。
| 函数示例 | 说明 |
|---|---|
_mm_slli_epi16、_mm_slli_epi32、_mm_slli_epi64 |
对__m128i寄存器的每个通道都做等长的左移 |
_mm_srli_epi16、_mm_srli_epi32、_mm_srli_epi64 |
对__m128i寄存器的每个通道都做等长的右移 |
_mm256_slli_epi16、_mm256_slli_epi32、_mm256_slli_epi64 |
对__m256i寄存器的每个通道都做等长的左移 |
_mm256_srli_epi16、_mm256_srli_epi32、_mm256_srli_epi64 |
对__m256i寄存器的每个通道都做等长的右移 |
还有一类移位函数会保留符号位,它们是_mm_srai_epi16、_mm_srai_epi32、_mm256_srai_epi16、_mm256_srai_epi32。这类函数可能是为了弥补整数除法指令的缺失,例如_mm_srai_epi16(x, 4)会把通道中的0x8015转换为0xF801,它相当于为有符号的int16_t整数做了除法x / 16。
AVX2引入了一系列指令来为每个通道分别指定不同的移位长度,它们是_mm_sllv_epi32、_mm_sllv_epi64、_mm_srlv_epi32、_mm_srlv_epi64以及对应的_mm256前缀版本。
4、打包与解包指令
| 函数示例 | 说明 |
|---|---|
_mm_unpacklo_epi32 |
输入两个向量[a, b, c, d]和[e, f, g, h],返回[a, e, b, f]。 |
_mm_unpackhi_epi32 |
输入两个向量[a, b, c, d]和[e, f, g, h],返回[c, g, d, h] |
_mm_packs_epi16 |
输入两个有符号整数向量,使用饱和运算将每个通道打包为位宽减半的类型 |
_mm_packus_epi16 |
输入两个无符号整数向量,使用饱和运算将每个通道打包为位宽减半的类型 |
unpacklo/unpackhi指令的一种用法是:如果第二个输入向量为全0,就可以把无符号整数转换到更宽的类型,例如8位无符号整数变为16位无符号整数。不过,也有指令可以直接实现无符号整数向更宽类型的转换,例如_mm_cvtepu16_epi32、_mm256_cvtepu8_epi32等。
5、洗牌指令
| 函数示例 | 说明 | 示意图 |
|---|---|---|
_mm_shuffle_epi32 |
右图中,控制常数是0x0D(二进制 00 00 11 01)。输出向量的4个通道分别来自输入向量的0b01、0b11、0b00、0b00号通道。 |  |
_mm_shufflelo_epi16 |
对低4个通道进行洗牌,高4个通道直接复制。右图中的控制常数是0x0D。 |  |
_mm_shufflehi_epi16 |
对高4个通道进行洗牌,低4个通道直接复制。右图中的控制常数是0x0D。 |  |
_mm_insert_epi16 |
插入一个整数。与浮点数插入指令不同的是,插入的整数来自通用寄存器。 |  |
_mm_blend_epi16 |
混合两个寄存器的通道。右图中的控制常数是0xB8(二进制 10111000)。 |  |
_mm_broadcastb_epi8_mm_broadcastw_epi16_mm_broadcastd_epi32_mm_broadcastq_epi64 |
把最低的通道广播到其它通道,右图是_mm_broadcastd_epi32。 |
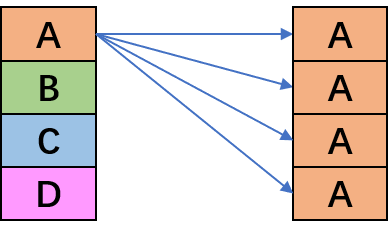 |
_mm_blendv_epi8 |
与blend指令不同的是,混合位掩码不直接编码到指令中,而是使用另一个寄存器。 | |
_mm256_permutevar8x32_epi32 |
接收一个包含源数据的整数寄存器和一个包含源索引的整数寄存器,根据索引值选择通道。 | |
_mm_shuffle_epi8 |
与其它类型的shuffle指令不同,这是唯一一条运行时按变量洗牌的指令。 |