client-go实战之九:手写一个kubernetes的controller
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 本文是《client-go实战》系列的第九篇,前面咱们已经了解了client-go的基本功能,现在要来一次经典的综合实战了,接下来咱们会手写一个kubernetes的controller,其功能是:监听某种资源的变化,一旦资源发生变化(例如增加或者删除),apiserver就会有广播发出,controller使用client-go可以订阅这个广播,然后在收到广播后进行各种业务操作,
- 本次实战代码量略大,但如果随本文一步步先设计再开发,并不会觉得有太多,总的来说由以下内容构成
- 代码整体架构一览
- 对着架构细说流程
- 全局重点的小结
- 编码实战
代码整体架构一览
- 首先,再次明确本次实战的目标:开发出类似kubernetes的controller那样的功能,实时监听pod资源的变化,针对每个变化做出响应
- 今天的实战源自client-go的官方demo,其主要架构如下
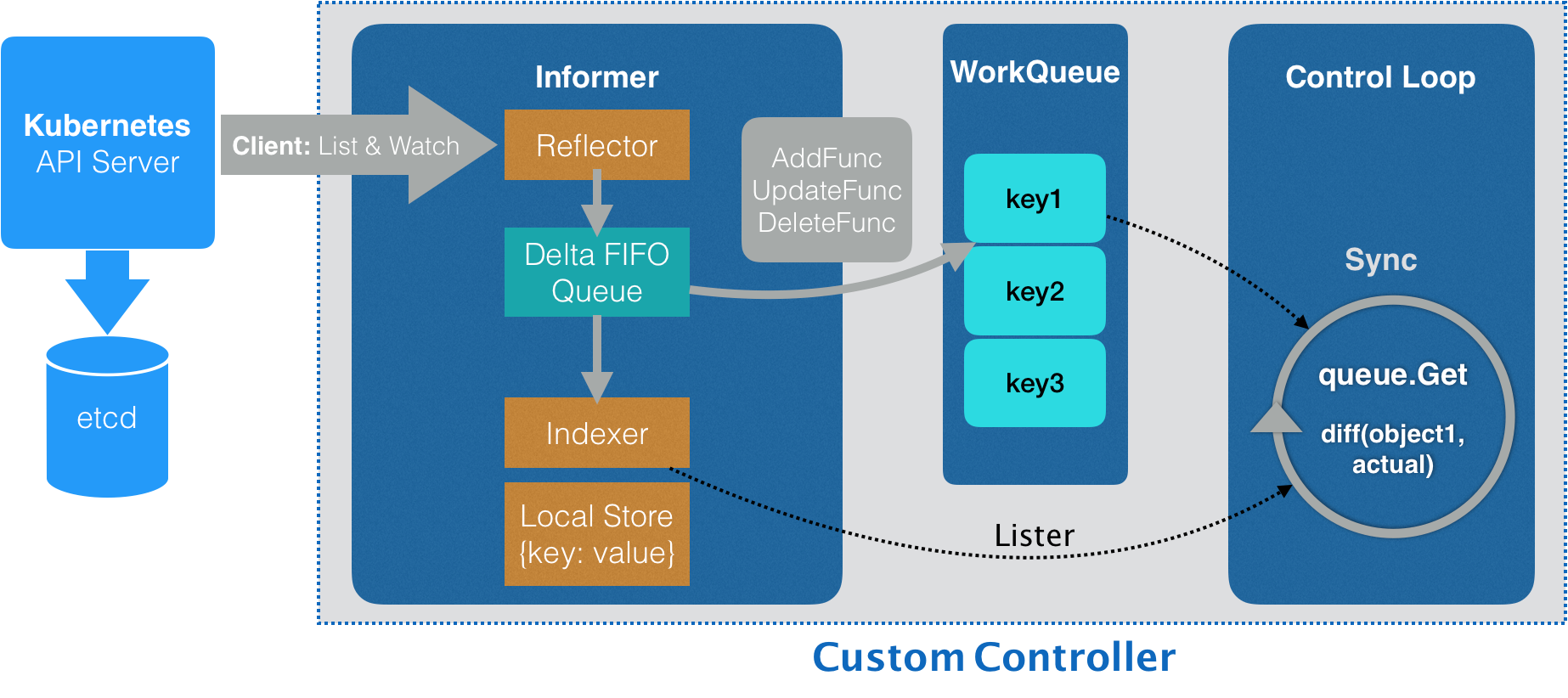
- 可能您会觉得上图有些复杂,没关系,接下来咱们细说此图,为后面的编码打好理论基础
对着架构细说流程
- 首先将上述架构图中涉及的内容进行分类,共有三部分
- 最左侧的Kubernetes API Server+etcd是第一部分,它们都是kubernetes的内部组件
- 第二部分是整个informer,informer是client-go库的核心模块
- 第三部分是WorkQueue和Conrol Loop,它们都是controller的业务逻辑代码
- 上面三部分合作,就能做到监听资源变化并做出响应
- 另外,informer内部很复杂也很精巧,后面会有专门的文章去细说,本篇只会提到与controller有关系的informer细节,其余的能不提就不提(不然内容太多,这篇文章写不完了)
- 分类完毕后,再来聊流程
- controller会通过client-go的list&watch机制与API Server建立长连接(http2的stream),只要pod资源发生变化,API Server就会通过长连接推送到controller
- API Server推的数据到达Reflector,它将数据写入Delta FIFO Queue
- Delta FIFO Queue是个先入先出的队列,除了pod信息还保存了操作类型(增加、修改、删除),informer内部不断从这个队列获取数据,再执行AddFunc、UpdateFunc、DeleteFunc等方法
- 完整的pod数据被存放在Local Store中,外部通过Indexer随时可以获取到
- controller中准备一个或多个工作队列,在执行AddFunc、UpdateFunc、DeleteFunc等方法时,可以将定制化的数据放入工作队列中
- controller中启动一个或多个协程,持续从工作队列中取数据,执行业务逻辑,执行过程中如果需要pod的详细数据,可以通过indexder获取
- 差不多了,我有种胸有成竹的感觉,迫不及待想写代码,但还是忍忍吧,先规划再动手
编码规划
- 所谓规划就是把步骤捋清楚,先写啥再写啥,如下图所示

- 捋顺了,开始写代码吧
编码之一:定义Controller数据结构(controller.go)
- 为了便于管理《client-go实战》系列的源码,本篇实战的源码依然存放在《client-go实战之七:准备一个工程管理后续实战的代码》中新增的golang工程中
- 先定义数据结构,新增controller.go文件,里面新增一个struct
type Controller struct {
indexer cache.Indexer
queue workqueue.RateLimitingInterface
informer cache.Controller
}
- 从上述代码可见Controller结构体有三个成员,indexer是informer内负责存取完整资源信息的对象,queue是用于业务逻辑的工作队列
编码之二:编写业务逻辑代码(controller.go)
- 业务逻辑代码共有四部分
- 把资源变化信息存入工作队列,这里可能按实际需求定制(例如有的数据不关注就丢弃了)
- 从工作队列中取出数据
- 取出数据后的处理逻辑,这边是纯粹的业务需求了,各人的实现都不一样
- 异常处理
- 步骤1,存入工作队列的操作,留待初始化informer的时候再做,
- 步骤4,异常处理稍后也有单独段落细说
- 这里只聚焦步骤2和3:怎么取,取出后怎么用
- 先写步骤2的代码:从工作队列中取取数据,用名为processNextItem的方法来实现(对每一行代码进行中文注释着实不易,支持的话请点个赞)
func (c *Controller) processNextItem() bool {
// 阻塞等待,直到队列中有数据可以被取出,
// 另外有可能是多协程并发获取数据,此key会被放入processing中,表示正在被处理
key, quit := c.queue.Get()
// 如果最外层调用了队列的Shutdown,这里的quit就会返回true,
// 调用processNextItem的地方发现processNextItem返回false,就不会再次调用processNextItem了
if quit {
return false
}
// 表示该key已经被处理完成(从processing中移除)
defer c.queue.Done(key)
// 调用业务方法,实现具体的业务需求
err := c.syncToStdout(key.(string))
// Handle the error if something went wrong during the execution of the business logic
// 判断业务逻辑处理是否出现异常,如果出现就重新放入队列,以此实现重试,如果已经重试过5次,就放弃
c.handleErr(err, key)
// 调用processNextItem的地方发现processNextItem返回true,就会再次调用processNextItem
return true
}
- 接下来写业务处理的代码,就是上面调用的syncToStdout方法,常规套路是检查spec和status的差距,然后让status和spec保持一致,(例如spec中指定副本数为2,而status中记录了真实的副本数是1,所以业务处理就是增加一个副本数),这里仅仅是为了展示业务处理代码在哪些,所以就简(fu)化(yan)一些了,只打印pod的名称
func (c *Controller) syncToStdout(key string) error {
// 根据key从本地存储中获取完整的pod信息
// 由于有长连接与apiserver保持同步,因此本地的pod信息与kubernetes集群内保持一致
obj, exists, err := c.indexer.GetByKey(key)
if err != nil {
klog.Errorf("Fetching object with key %s from store failed with %v", key, err)
return err
}
if !exists {
fmt.Printf("Pod %s does not exist anymore\n", key)
} else {
// 这里就是真正的业务逻辑代码了,一般会比较spce和status的差异,然后做出处理使得status与spce保持一致,
// 此处为了代码简单仅仅打印一行日志
fmt.Printf("Sync/Add/Update for Pod %s\n", obj.(*v1.Pod).GetName())
}
return nil
}
编码之三:编写错误处理代码(controller.go)
- 回顾前面的processNextItem方法内容,在调用syncToStdout执行完业务逻辑后就立即调用handleErr方法了,此方法的作用是检查syncToStdout的返回值是否有错误,然后做针对性处理
func (c *Controller) handleErr(err error, key interface{}) {
// 没有错误时的处理逻辑
if err == nil {
// 确认这个key已经被成功处理,在队列中彻底清理掉
// 假设之前在处理该key的时候曾报错导致重新进入队列等待重试,那么也会因为这个Forget方法而不再被重试
c.queue.Forget(key)
return
}
// 代码走到这里表示前面执行业务逻辑的时候发生了错误,
// 检查已经重试的次数,如果不操作5次就继续重试,这里可以根据实际需求定制
if c.queue.NumRequeues(key) < 5 {
klog.Infof("Error syncing pod %v: %v", key, err)
c.queue.AddRateLimited(key)
return
}
// 如果重试超过了5次就彻底放弃了,也像执行成功那样调用Forget做彻底清理(否则就没完没了了)
c.queue.Forget(key)
// 向外部报告错误,走通用的错误处理流程
runtime.HandleError(err)
klog.Infof("Dropping pod %q out of the queue: %v", key, err)
}
- 好了,和业务有关的代码已经完成,接下来就是搭建controller框架,把基本功能串起来
编码之四:编写Controller主流程(controller.go)
- 编写一个完整的Controller,最基本的是构造方法,Controller的构造方法也很简单,保存三个重要的成员变量即可
func NewController(queue workqueue.RateLimitingInterface, indexer cache.Indexer, informer cache.Controller) *Controller {
return &Controller{
informer: informer,
indexer: indexer,
queue: queue,
}
}
- 先定义个名为runWorker的简单方法,里面是个无限循环,只要消费消息的processNextItem方法返回true,就无限循环下去
func (c *Controller) runWorker() {
for c.processNextItem() {
}
}
- 然后是Controller主流程代码,简介清晰,启动informer,开始接受apiserver推送,写入工作队列,然后开启无限循环从工作队列取数据并处理
func (c *Controller) Run(workers int, stopCh chan struct{}) {
defer runtime.HandleCrash()
// 只要工作队列的ShutDown方法被调用,processNextItem方法就会返回false,runWorker的无限循环就会结束
defer c.queue.ShutDown()
klog.Info("Starting Pod controller")
// informer的Run方法执行后,就开始接受apiserver推送的资源变更事件,并更新本地存储
go c.informer.Run(stopCh)
// 等待本地存储和apiserver完成同步
if !cache.WaitForCacheSync(stopCh, c.informer.HasSynced) {
runtime.HandleError(fmt.Errorf("Timed out waiting for caches to sync"))
return
}
// 启动worker,并发从工作队列取数据,然后执行业务逻辑
for i := 0; i < workers; i++ {
go wait.Until(c.runWorker, time.Second, stopCh)
}
<-stopCh
klog.Info("Stopping Pod controller")
}
- 现在一个完整的Controller已经完成了,接下来编写调用Controller的代码,将其所需的三个对象传入,再调用它的Run方法
编码之五:编写调用Controller的代码(controller_demo.go)
- 为了能让整个工程的main方法调用Controller,这里新增controller_demo.go方法,里面新增名为ControllerDemo的数据结构,创建Controller对象以及为其准备成员变量的操作都在ControllerDemo.DoAction方法中
package action
import (
v1 "k8s.io/api/core/v1"
"k8s.io/apimachinery/pkg/fields"
"k8s.io/client-go/kubernetes"
"k8s.io/client-go/tools/cache"
"k8s.io/client-go/util/workqueue"
)
type ControllerDemo struct{}
func (controllerDemo ControllerDemo) DoAction(clientset *kubernetes.Clientset) error {
// 创建ListWatch对象,指定要监控的资源类型是pod,namespace是default
podListWatcher := cache.NewListWatchFromClient(clientset.CoreV1().RESTClient(), "pods", v1.NamespaceDefault, fields.Everything())
// 创建工作队列
queue := workqueue.NewRateLimitingQueue(workqueue.DefaultControllerRateLimiter())
// 创建informer,并将返回的存储对象保存在变量indexer中
indexer, informer := cache.NewIndexerInformer(podListWatcher, &v1.Pod{}, 0, cache.ResourceEventHandlerFuncs{
// 响应新增资源事件的方法,可以按照业务需求来定制,
// 这里的做法比较常见:写入工作队列
AddFunc: func(obj interface{}) {
key, err := cache.MetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
// 响应修改资源事件的方法,可以按照业务需求来定制,
// 这里的做法比较常见:写入工作队列
UpdateFunc: func(old interface{}, new interface{}) {
key, err := cache.MetaNamespaceKeyFunc(new)
if err == nil {
queue.Add(key)
}
},
// 响应修改资源事件的方法,可以按照业务需求来定制,
// 这里的做法比较常见:写入工作队列,注意删除的时候生成key的方法和新增修改不一样
DeleteFunc: func(obj interface{}) {
// IndexerInformer uses a delta queue, therefore for deletes we have to use this
// key function.
key, err := cache.DeletionHandlingMetaNamespaceKeyFunc(obj)
if err == nil {
queue.Add(key)
}
},
}, cache.Indexers{})
// 创建Controller对象,将所需的三个变量对象传入
controller := NewController(queue, indexer, informer)
// Now let's start the controller
stop := make(chan struct{})
defer close(stop)
// 在协程中启动controller
go controller.Run(1, stop)
// Wait forever
select {}
return nil
}
编码之六:main方法中支持(main.go)
- 然后是整个工程的main方法,里面增加一段代码,支持新增的ControllerDemo,如下图黄框所示

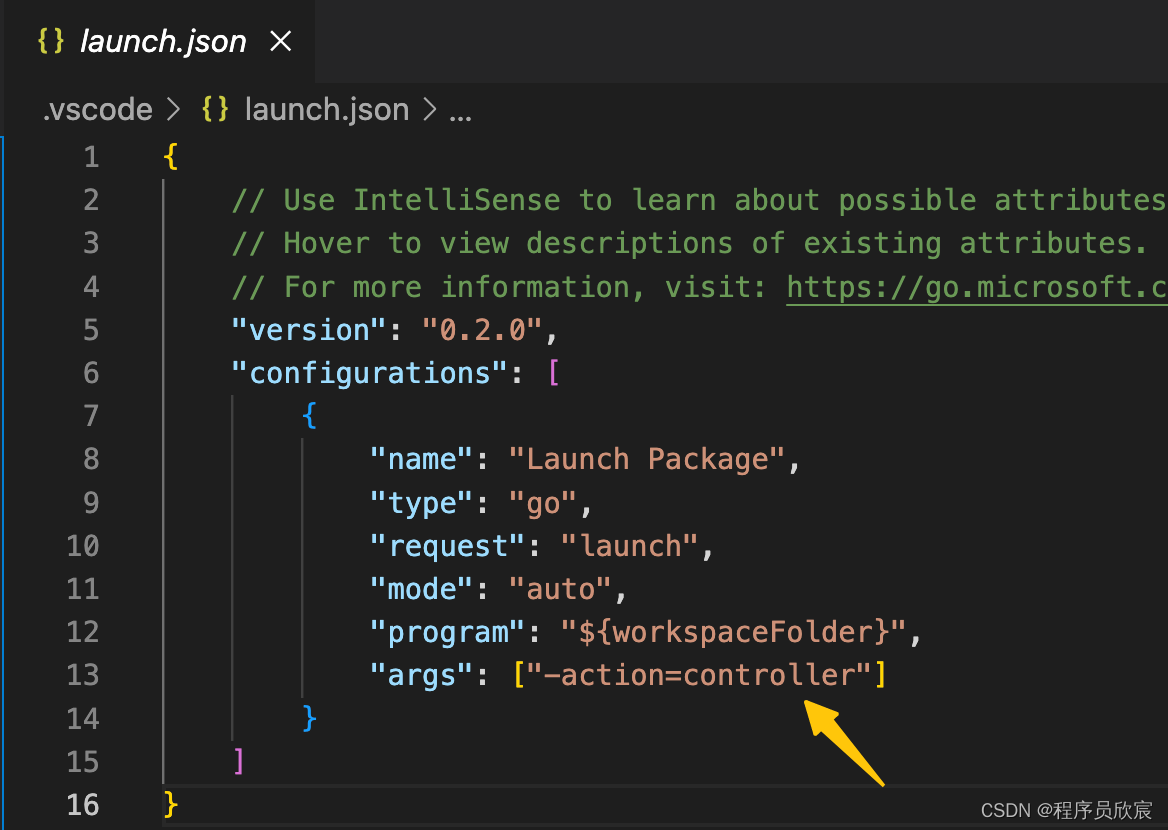
- 最后,如果您使用的是vscode,记得修改launch.json,如下图黄色箭头,这样main方法运行的时候就会执行Controller的代码了
运行和验证
- 现在工程目录执行以下命令,获取必要的包
go get k8s.io/apimachinery/pkg/util/[email protected]
- 确保kubernetes环境正常,.kube/config配置也能正常使用,然后运行main.go
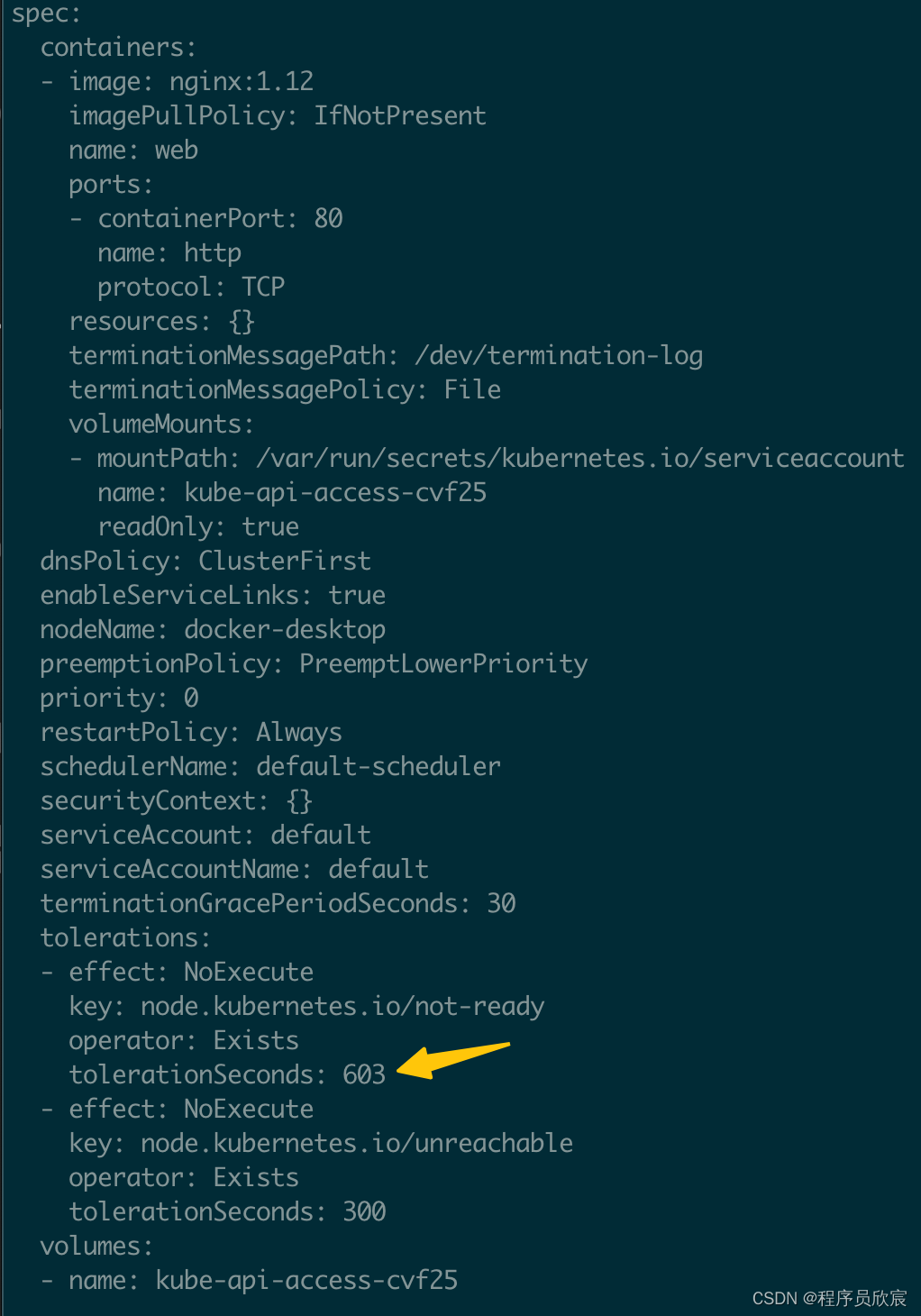
- 使用kubectl edit xxx修改kubernetes环境中的pod,例如我这里改的是下图黄色箭头的值
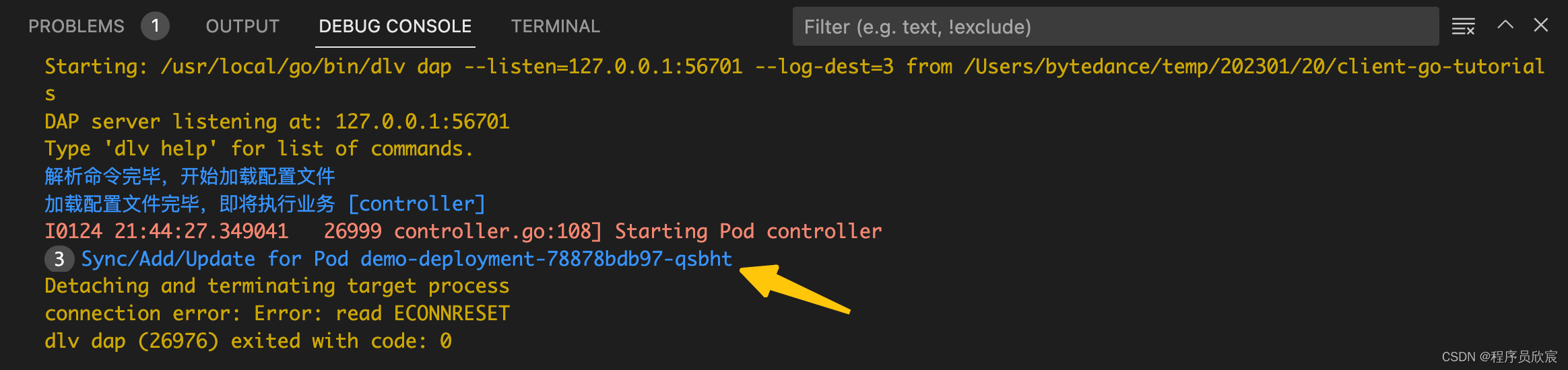
- 修改完毕保存退出后,运行mian.go的控制台立即有内容输出,如下图黄色箭头,是咱们前面的syncToStdout方法的输入,符合预期
- 至此,整个Controller已经开发完成了,相信您已经熟悉了informer和kubernetes的controller的基本套路,加上前面的文章打下的基础,再去做kubernetes二次开发,或者operator开发等都能轻松驾驭了
本篇涉及知识点串讲
- 前几篇的风格,都是抓住一个问题深入研究和实践,但是到了本篇似乎多个知识点同时涌出,并且还要紧密配合完成业务目标,可能年轻的您一下子略有不适应,我这里再次将本次开发中的重点进行总结,经历过一番实战,再来看这些总结,相信您很容易就融会贯通了
- 先给出数据流视图,结合前面的实战,您应该能一眼看懂

- 接下来开始梳理重点
- 创建一个名为podListWatcher的ListWatch对象,用于对指定资源类型建立监听(本例中监听的资源是pod)
- 创建一个名为queue的工作队列,就是个先进先出的内存对象,没啥特别之处
- 通过podListWatcher创建一个informer,这个informer的功能对podListWatcher监听的事件作相应
- 在创建informer的时候还会返回一个名为indexer的本地缓存,这里面保存了所有pod信息(由于pod的变动全部都会被informer收到,因此indexer中保存了最新的pod信息)
- 在新协程中启动informer,这里面对应两件事情:第一,创建Reflector对象,这个Reflector对象会把podListWatcher监听到的数据放入一个DeltaFIFO队列(注意不是步骤2中的工作队列),第二是循环地取出fifo队列中的数据,再调用AddFunc、UpdateFunc、DeleteFunc等方法
- 步骤5中提到的AddFunc、UpdateFunc、DeleteFunc可以在创建informer的时候,由业务开发者自定义,一般会再次将key放入工作队列中
- 在新协程消费工作队列queue的数据,这里可以根据业务需求写入也任务逻辑代码
- 基于以上详细描述,再来个精简版,介绍重点对象,如果您对详细描述不感兴趣,可以只看精简版,掌握其中关键即可
- podListWatcher:用于监听指定类型资源的变化
- queue:工作队列,从里面取出的key,其资源都有事件发生
- informer:接受监听到的事件,再调用指定的回调方法
- Reflector:informer内部三大对象之一,用于接受事件再写入一个内部fifo队列
- DeltaFIFO:informer内部三大对象之二,先入先出队列,还保存了操作类型
- indexer:informer内部三大对象之三,这里面保存的是指定资源的完整数据,和apiserver侧保持同步
- 接受消息的协程:informer在这个协程中启动,也在这个协程中将数据写入工作队列
- 处理工作队列的协程:负责从工作队列中取出数据处理
- 工作队列queue和informer内部的fifo是不同的队列,是两回事,为了满足业务需求,我们可以在一个controller中创建多个工作队列,也可以不要工作队列(在informer的三个回调方法中完成业务逻辑)
以下是官方参考信息
源码下载
- 上述完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | [email protected]:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本篇的源码在tutorials/client-go-tutorials文件夹下,如下图红框所示:

- 写到这里,client-go基本功的学习已经完成了,接下来咱们还要继续深入研究,让这个优秀的库在手中发挥更大的威力,欣宸原创,敬请期待