【matplotlib 实战】--南丁格尔玫瑰图
南丁格尔玫瑰图是一种用极坐标下的柱状图或堆叠柱状图来展示数据的图表。
虽然南丁格尔玫瑰图外观类似饼图,但是表示数据的方式不同,它是以半径来表示数值的,
而饼图是以扇形的弧度来表达数据的。
所以,南丁格尔玫瑰图在视觉上会夸大数据的比例,因为半径和面积之间是平方关系。
因此,当需要对比非常相近的数值时,适当的夸大有助于区分数据,但在追求数据准确性时,玫瑰图可能不是最佳选择。
据说,南丁格尔玫瑰图由统计学家和医学改革家佛罗伦萨‧南丁格尔在克里米亚战争期间创造,
用于反映军医院的季节性死亡率,从而推动医院条件的改善。
1. 主要元素
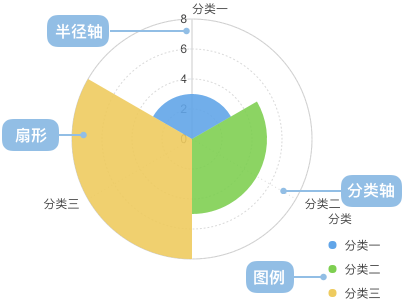
南丁格尔玫瑰图的主要元素包括:
- 扇形:每个扇形代表一个类别或分组,其面积大小表示该类别或分组的数值大小。
- 半径轴:扇形的半径表示数据的大小,半径越长表示数值越大。
- 图例:图例是饼图的一部分,用于解释每个饼片所代表的含义,帮助观察者理解图表。
- 标签:可在每个扇形上方或内部添加标签,标注该类别或分组的名称或数值,帮助人们更好地理解数据。
2. 适用的场景
南丁格尔玫瑰图适用的场景包括:
- 数据分布比较:比较不同类别或分组之间的数据分布情况,例如比较不同产品的销售量或不同地区的人口分布。
- 百分比展示:展示各类别或分组所占的百分比大小,特别适用于展示相对比例的数据。
- 强调特定数据:通过扇形的面积和颜色等元素使其更加显眼和易于被注意到。
- 增强视觉吸引力:南丁格尔玫瑰图具有独特的视觉效果,可以吸引观众的注意力,适用于需要突出表达的场合。
3. 不适用的场景
南丁格尔玫瑰图不适用的场景包括:
- 连续数据分布:南丁格尔玫瑰图适用于展示离散的数据分布情况,不适用于展示连续数据的分布情况,例如时间序列数据。
- 多变量比较:如果需要比较多个变量之间的关系,南丁格尔玫瑰图可能不够直观和有效。
- 大量数据展示:如果数据量过大,可能会导致扇形过小,难以辨认和理解。
- 数据精确度要求高:南丁格尔玫瑰图的可视化效果更多地强调数据分布的趋势和相对大小,不适合展示具有高精确度要求的数据。
4. 分析实战
本次使用 王者荣耀KPL 2023年春季赛的数据,分析各个战队的排名和胜率。
4.1. 数据来源
数据来自王者荣耀官方网站,整理好的数据下载地址:
https://databook.top/wzry/2023-spring
本次分析使用其中 各个战队的相关数据:league-2023春季赛.csv
fp = "d:/share/data/league-2023春季赛.csv"
df = pd.read_csv(fp)
df

4.2. 数据清理
原始数据中,字段比较多,提取前10名的战队,用南丁格尔玫瑰图分析其胜率情况。
key = "胜率"
data = df.sort_values("排名")
data = data.reset_index()
#提取前10名,只保留 战队 和 胜率 2个字段
data = data.loc[:9, ["战队", key]]
#胜率字段转换为 float 类型
data[key] = data[key].str.replace("%", "")
data[key] = data[key].astype("float")
data

4.3. 分析结果可视化
matplotlib 中没有提供专门绘制南丁格尔玫瑰图的接口,我们可以用极坐标系下的柱状图来模拟。
with plt.style.context("seaborn-v0_8"):
fig = plt.figure()
ax = fig.add_axes([0.1, 0.1, 1, 1], polar=True)
ax.set_theta_offset(np.pi/2)
ax.set_theta_direction(-1)
ax.set_rlabel_position(0)
n = len(data)
# 每个数据的角度
angle = np.linspace(0, 2 * np.pi, n, endpoint=False)
# 绘制用到的数据
radius = np.array(data[key].tolist())
ax.yaxis.set_major_locator(plt.NullLocator())
# x轴刻度显示战队名称
ax.set_xticks(angle, data["战队"])
# 中间空出一个孔
ax.set_ylim(-10, max(data[key]))
ax.bar(angle, radius, color=plt.cm.tab10.colors, width=0.62)

从分析结果可以看出,第一名重庆狼队的胜率明显高出其他的战队,而其他战队的胜率差别不大。
说明目前 王者荣耀KPL联盟中,各个战队的实力比较接近,比赛会非常精彩。