Redis的五大数据类型的数据结构
概述
Redis底层有六种数据类型包括:简单动态字符串、双向链表、压缩列表、哈希表、跳表和整数数组。这六种数据结构五大数据类型关系如下:
- String:简单动态字符串
- List:双向链表、压缩列表
- Hash:压缩列表、哈希表
- Sorted Set:压缩列表、跳表
- Set:哈希表、整数数组

数据类型和底层数据结构对应关系
每种数据结构特性不一样,操作时间也不一样。

数据结构的时间复杂度
二、数据结构
从上述图中可以知道,Redis的底层数据结构由简单动态字符串、双向链表、压缩列表、哈希表、跳表、整数数组组成,其中哈希表和整数数组基本上大家都很熟悉了,下面重点介绍一下其余的几种数据结构。
1、简单动态字符串(SDS)
结构:alloc,len,buf
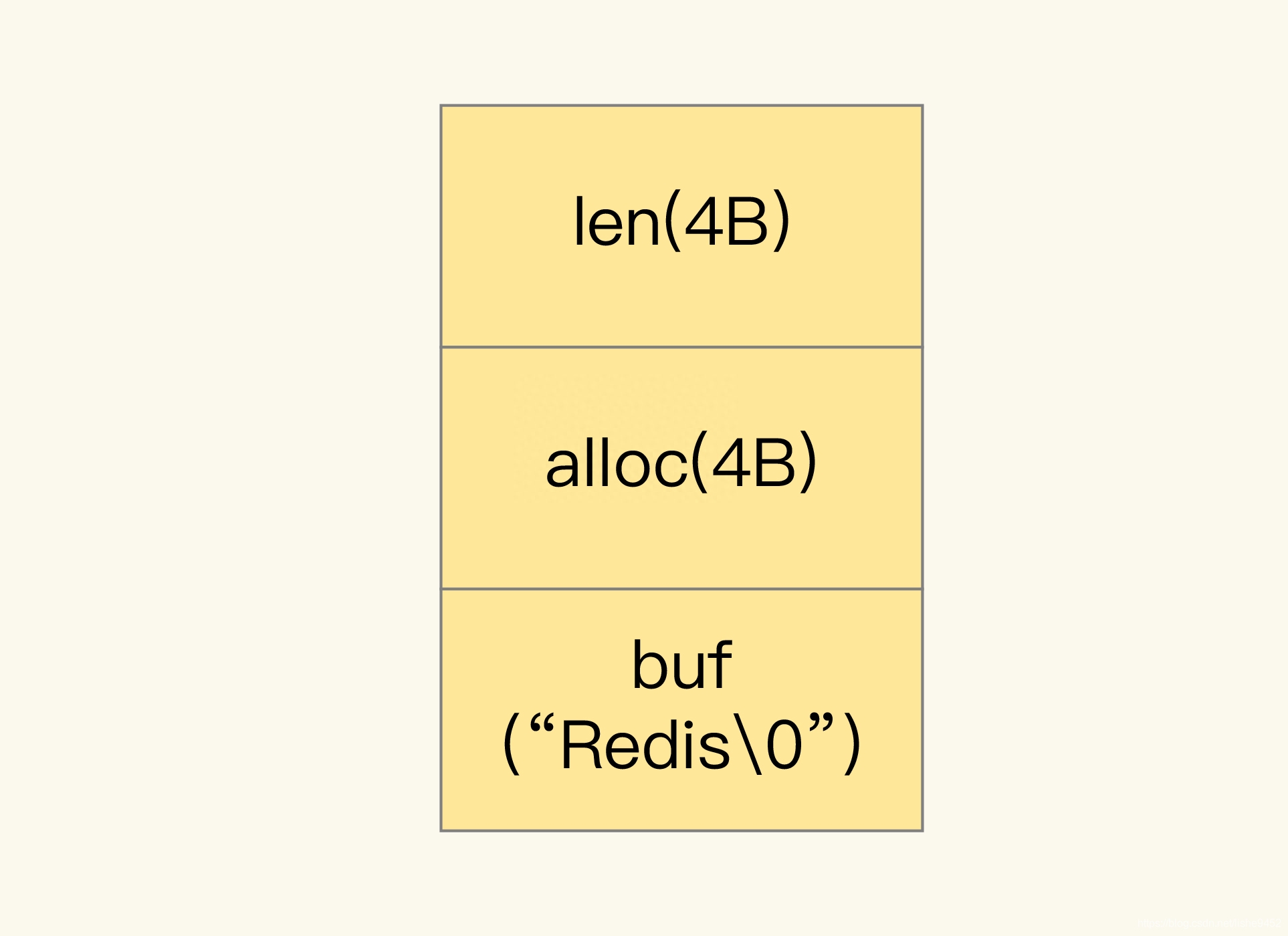
简单动态字符串结构
buf:字节数组,保存实际数据。为了表示字节数组的结束,Redis 会自动在数组最后加一个“\0”,这就会额外占用 1 个字节的开销。
len:占 4 个字节,表示 buf 的已用长度。
alloc:也占个 4 字节,表示 buf 的实际分配长度,一般大于 len。
那么SDS与C字符串有什么区别呢?区别主要有如下两点:
(1)获取字符串长度时间复杂度为O(1)
(2)在修改字符串时,会先检查长度是否够长,不够会进行扩展,避免缓冲区溢出
2、链表
Redis使用的是双向无环链表,并且具有以下几个特点:
(1)双端:链表具有前置节点和后置节点的引用,获取这两个节点时间复杂度都为O(1)。
(2)无环:表头节点的 prev 指针和表尾节点的 next 指针都指向 NULL,对链表的访问都是以 NULL 结束。
(3)带链表长度计数器:通过 len 属性获取链表长度的时间复杂度为 O(1)。
(4)多态:链表节点使用 void* 指针来保存节点值,可以保存各种不同类型的值。
3、压缩列表
压缩列表(ziplist)是Redis为了节省内存而开发的,是由一系列特殊编码的连续内存块组成的顺序型数据结构,一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值。压缩列表并不是对数据利用某种算法进行压缩,而是将数据按照一定规则编码在一块连续的内存区域,目的是节省内存。
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束;
我们要查找定位第一个元素和最后一个元素,可以通过表头三个字段的长度直接定位,复杂度是 O(1)。而查找其他元素时,就没有这么高效了,只能逐个查找,此时的复杂度就是 O(N) 了。

压缩表的查找过程
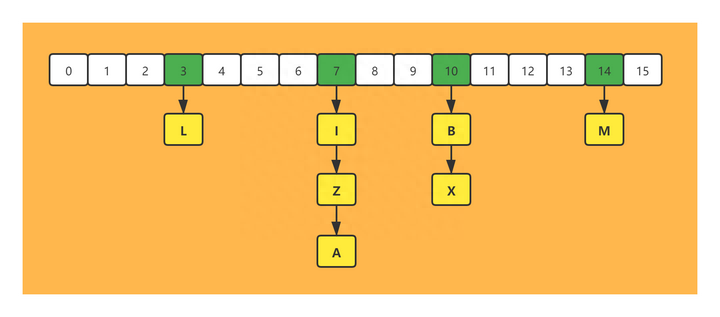
4、跳表
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,时间复杂度为O(logN),比起链表,跳表的查询效率大大提高到了 O(logn)。

跳表查找过程
三、Redis数据类型的基本数据结构
1、String(字符串)
1.1 String的内部结构
redis没有直接使用C语言中的字符串表示,而是自己构建了一个字符串,名为 “简单动态字符串” (simple dynamic string , SDS)。其中,C语言中的字符串只是作为字符串面量(通常在无须对字符串值进行修改的地方使用)。
String在结构上的实现类似于Java中的ArrayList(默认构造一个大小为10的初始数组),这是冗余分配内存的思想,也称为预分配;这种思想可以减少扩容带来的性能消耗。

String的内部结构
1.2 String使用的数据编码
存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码;
1.3 使用场景
(1) 简单字符缓存
(2) 分布式锁
(3)计数功能——》计数服务
2、List(列表)
2.1 List的内部结构
Redis的列表相当于Java语言中的LinkedList,它是一个双向链表数据结构(但是这个结构设计比较巧妙,后面会介绍),支持前后顺序遍历。链表结构插入和删除操作快,时间复杂度O(1),查询慢,时间复杂度O(n)。

List的内部结构
2.2 List使用的数据编码
字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码。
2.3 使用场景
(1)利用List实现栈、队列
(2)redis做消息队列(不推荐使用redis做消息队列)
(3)列表缓存
3、Hash(字典)
3.1 Hash的内部结构
Redis的hash(字典)相当于Java语言中的HashMap,它是根据散列值分布的无序字典,内部的元素是通过键值对的方式存储。
hash(字典)的实现与Java中的HashMap(JDK1.7)的结构也是一致的,它的数据结构也是数组+链表组成的二维结构,节点元素散列在数组上,如果发生hash碰撞则使用链表串联在数组节点上。
Hash的内部结构
3.2 Hash使用的数据编码
hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对。
3.3 使用场景
(1) 存储对象
4、Set(集合)
4.1 Set的内部结构
Redis的set(集合)相当于Java语言里的HashSet,它内部的键值对是无序的、唯一的。它的内部实现了一个所有value为null的特殊字典。
集合中的最后一个元素被移除之后,数据结构被自动删除,内存被回收。

Set的内部结构
4.2 Set使用的数据编码
保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码。
4.3 使用场景
(1)标签,社交,查询有共同兴趣爱好的人,智能推荐
(2)抽奖
(3)朋友圈点赞
5、Zset(有序集合)
5.1 Zset的内部结构
zset(有序集合)是Redis中最常问的数据结构。它类似于Java语言中的SortedSet和HashMap的结合体,它一方面通过set来保证内部value值的唯一性,另一方面通过value的score(权重)来进行排序。这个排序的功能是通过Skip List(跳跃列表)来实现的。zset(有序集合)的最后一个元素value被移除后,数据结构被自动删除,内存被回收。

Zset的内部结构
5.2 Zset使用的数据编码
zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
5.3 使用场景
(1)排名场景