形象谈JVM-第三章-即时编译器优化技术
即时编译器优化技术一览:


相信许多同学看完这个表格,脑子里面嗡嗡的,这些名字也是晦涩难懂,要实现这些优化的技术确实有比较大的难度,但是咱们只是学习,去理解这些技术,其实并不难,下面咱们直接开讲。
首先需要明确一点的,作者是为了讲解方便,使用java的语法来表示优化技术所发挥出来的作用,实际上编译优化并不是建立在java代码之上的,而是建立在代码的中间表示或者是机器码之上的。
优化前:

优化后:
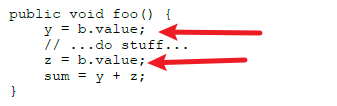
相信很容易看到优化后的不一样,将get()直接优化成了.value,这个叫做方法内联。
它的主要目的有两个:
一是去除方法调用的成本(如查找方法版本、建立栈帧等);
二是为其他优化建立良好的基础。方法内联膨胀之后可以便于在更大范围上进行后续的优化手段,可以获取更好的优化效果。
因此各种编译器一般都会把内联优化放在优化序列最靠前的位置。
优化前:

优化后:
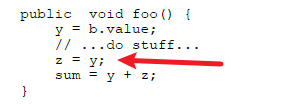
这个叫冗余访问消除,假设代码中间注释掉的“…do stuff…”所代表的操作不会改变b.value的值,那么就可以把“z=b.value”替换为“z=y”,因为上一句“y=b.value”已经保证了变量y与b.value是一致的,这样就可以不再去访问对象b的局部变量了。
优化前:

优化后:
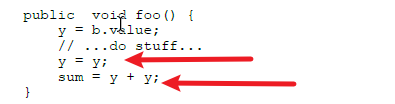
这个叫复写传播,因为这段程序的逻辑之中没有必要使用一个额外的变量z,它与变量y是完全相等的,因此我们可以使用y来代替z。
优化前:

优化后:

这个叫无用代码消除,无用代码可能是永远不会被执行的代码,也可能是完全没有意义的代码。
经过四次优化之后,前后的代码所达到的效果是一致的,但是后者比前者省略了许多语句,体现在字节码和机器码指令上的差距会更大,执行效率的差距也会更高。
接下来我们重点讲解一下四项有代表性的优化技术:
一、方法内联
内联被业内戏称为优化之母,因为除了消除方法调用的成本之外,它更重要的意义是为其他优化手段建立良好的基础,我们可以回头看看前面的案例,如果没有最开始的方法内联,后续多数其他优化都无法有效进行。
方法内联的优化行为理解起来是没有任何困难的,不过就是把目标方法的代码原封不动地“复制”到发起调用的方法之中,避免发生真实的方法调用而已。但实际上Java虚拟机中的内联过程却远没有想象中容易,甚至如果不是即时编译器做了一些特殊的努力,按照经典编译原理的优化理论,大多数的Java方法都无法进行内联。
对于一个虚方法,编译器静态地去做内联的时候很难确定应该使用哪个方法版本,以之前例子所示的b.get()直接内联为b.value为例,如果不依赖上下文,是无法确定b的实际类型是什么的。
假如有ParentB和SubB是两个具有继承关系的父子类型,并且子类重写了父类的get()方法,那么b.get()是执行父类的get()方法还是子类的get()方法,这应该是根据实际类型动态分派的,而实际类型必须在实际运行到这一行代码时才能确定,编译器很难在编译时得出绝对准确的结论。
于是,Java虚拟机引入了类型继承关系分析技术,这是整个应用程序范围内的类型分析技术(Class HierarchyAnalysis,CHA),用于确定在目前已加载的类中,某个接口是否有多于一种的实现、某个类是否存在子类、某个子类是否覆盖了父类的某个虚方法等信息。如果是非虚方法,直接进行内联就可以了;
如果遇到虚方法,则会向CHA查询此方法在当前程序状态下是否真的有多个目标版本可供选择,如果只有一个版本,直接进行内联。
不过由于Java程序是动态连接的,说不准什么时候就会加载到新的类型从而改变CHA结论,因此这种内联属于激进预测性优化,必须预留好“逃生门”,即当假设条件不成立时的“退路”。假如在程序的后续执行过程中,虚拟机一直没有加载到会令这个方法的接收者的继承关系发生变化的类,那这个内联优化的代码就可以一直使用下去。如果加载了导致继承关系发生变化的新类,那么就必须抛弃已经编译的代码,退回到解释状态进行执行,或者重新进行编译。
若CHA查询出该方法确实有多个版本的目标方法,那即时编译器还将进行最后一次努力,使用内联缓存的方式来缩减方法调用的开销。这种状态下方法调用是真正发生了的,但是比起直接查虚方法表还是要快一些。
内联缓存是一个建立在目标方法正常入口之前的缓存,它的工作原理大致为:在未发生方法调用之前,内联缓存状态为空,当第一次调用发生后,缓存记录下方法接收者的版本信息,并且每次进行方法调用时都比较接收者的版本。如果以后进
来的每次调用的方法接收者版本都是一样的,那么这时它就是一种单态内联缓存。通过该缓存来调用,比用不内联的非虚方法调用,仅多了一次类型判断的开销而已。(这一点和sychronized锁优化的偏向锁思路相似)
但如果真的出现方法接收者不一致的情况,就说明程序用到了虚方法的多态特性,这时候会退化成超多态内联缓存,其开销相当于真正查找虚方法表来进行方法分派。
二、逃逸分析
逃逸分析的基本原理是:分析对象动态作用域,当一个对象在方法里面被定义后,它可能被外部方法所引用,例如作为调用参数传递到其他方法中,这种称为方法逃逸;
甚至还有可能被外部线程访问到,譬如赋值给可以在其他线程中访问的实例变量,这种称为线程逃逸;
从不逃逸、方法逃逸到线程逃逸,称为对象由低到高的不同逃逸程度。
如果能证明一个对象不会逃逸到方法或线程之外(换句话说是别的方法或线程无法通过任何途径访问到这个对象),或者逃逸程度比较低(只逃逸出方法而不会逃逸出线程),则可能为这个对象实例采取不同程度的优化,
如:
栈上分配:在Java虚拟机中,Java堆上分配创建对象的内存空间几乎是Java程序员都知道的常识,Java堆中的对象对于各个线程都是共享和可见的,只要持有这个对象的引用,就可以访问到堆中存储的对象数据。
虚拟机的垃圾收集子系统会回收堆中不再使用的对象,但回收动作无论是标记筛选出可回收对象,还是回收和整理内存,都需要耗费大量资源。如果确定一个对象不会逃逸出线程之外,那让这个对象在栈上分配内存将会是一个很不错的主意,对象所占用的内存空间就可以随栈帧出栈而销毁。
在一般应用中,完全不会逃逸的局部对象和不会逃逸出线程的对象所占的比例是很大的,如果能使用栈上分配,那大量的对象就会随着方法的结束而自动销毁了,垃圾收集子系统的压力将会下降很多。
栈上分配可以支持方法逃逸,但不能支持线程逃逸。
标量替换:若一个数据已经无法再分解成更小的数据来表示了,Java虚拟机中的原始数据类型(int、long等数值类型及reference类型等)都不能再进一步分解了,那么这些数据就可以被称为标量。
相对的,如果一个数据可以继续分解,那它就被称为聚合量,Java中的对象就是典型的聚合量。如果把一个Java对象拆散,根据程序访问的情况,将其用到的成员变量恢复为原始类型来访问,这个过程就称为标量替换。
假如逃逸分析能够证明一个对象不会被方法外部访问,并且这个对象可以被拆散,那么程序真正执行的时候将可能不去创建这个对象,而改为直接创建它的若干个被这个方法使用的成员变量来代替。
同步消除:线程同步本身是一个相对耗时的过程,如果逃逸分析能够确定一个变量不会逃逸出线程,无法被其他线程访问,那么这个变量的读写肯定就不会有竞争,对这个变量实施的同步措施也就可以安全地消除掉。
三、公共子表达式消除
如果一个表达式E之前已经被计算过了,并且从先前的计算到现在E中所有变量的值都没有发生变化,那么E的这次出现就称为公共子表达式。对于这种表达式,没有必要花时间再对它重新进行计算,只需要直接用前面计算过的表达式结果代替E。
如果这种优化仅限于程序基本块内,便可称为局部公共子表达式消除,如果这种优化的范围涵盖了多个基本块,那就称为全局公共子表达式消除。

四、数组边界检查消除
Java语言是一门动态安全的语言,对数组的读写访问也不像C、C++那样实质上就是裸指针操作。
如果有一个数组foo[],在Java语言中访问数组元素foo[i]的时候系统将会自动进行上下界的范围检查,即i必须满足“i>=0 && i<foo.length”的访问条件,否则将抛出一个运行时异常:java.lang.ArrayIndexOutOfBoundsException。
这对软件开发者来说是一件很友好的事情,即使程序员没有专门编写防御代码,也能够避免大多数的溢出攻击。但是对于虚拟机的执行子系统来说,每次数组元素的读写都带有一次隐含的条件判定操作,对于拥有大量数组访问的程序代码,这必定是一种性能负担。
无论如何,为了安全,数组边界检查肯定是要做的,但数组边界检查是不是必须在运行期间一次不漏地进行则是可以“商量”的事情。例如下面这个简单的情况:数组下标是一个常量,如foo[3],只要在编译期根据数据流分析来确定foo.length的值,并判断下标“3”没有越界,执行的时候就无须判断了。
更加常见的情况是,数组访问发生在循环之中,并且使用循环变量来进行数组的访问。如果编译器只要通过数据流分析就可以判定循环变量的取值范围永远在区间[0,foo.length)之内,那么在循环中就可以把整个数组的上下界检查消除掉,这可以节省很多次的条件判断操作。
参考资料:
深入理解虚拟机-第3版-周志明著
为什么写文章 ?(若有错误,希望得到你的指正,若有问题,都可评论,我将会积极回复)
在作者刚入行时,会遇到很多无法理解的问题,便经常向前辈请教问题,或是于网络之中苦苦寻找答案,经常被一些晦涩难懂的表达折磨的死去活来,现作者是一名拥有多年经验的IT从业者,希望能够将自己的知识以一种形象的方式输出,先从虚拟机开始分享,之后会写更多的专栏,最新的分享将会先在公众号发布,谢谢读者的关注

热门相关:洪荒二郎传 买妻种田:山野夫君,强势宠! 后福 不科学御兽 今天也没变成玩偶呢