nlp入门(三)基于贝叶斯算法的拼写错误检测器
源码请到:自然语言处理练习: 学习自然语言处理时候写的一些代码 (gitee.com)
数据来源:norvig.com/big.txt
贝叶斯原理可看这里:机器学习算法学习笔记 - 过客匆匆,沉沉浮浮 - 博客园 (cnblogs.com)
一、数据预处理
将输入的数据全部变为小写方便后续处理
def words(text): return re.findall('[a-z]+', text.lower())
二、根据语料库统计不同单词出现的词频
单词字典每个单词词频默认为1,因为如果单词字典默认值为为0,那么出现了语料库中没有的单词,就会默认概率为0,导致新的单词无法被识别
def train(features): model = collections.defaultdict(lambda: 1) # 如果默认为0则出现语料库中没有的新词会不识别,所以默认为1 for f in features: model[f] += 1 return model
三、打开语料库与构建字母表
NWORDS = train(words(open('data/big.txt').read())) alphabet = 'abcdefghijklmnopqrstuvwxyz'
四、返回编辑距离为1的单词
单词a经过n次修改可以得到新的单词b,那我们叫b为a的编辑距离为1的单词,下面函数就返回编辑距离为1的单词
# 返回编辑距离为1的单词 def editsl(word): n = len(word) return set([word[0:i] + word[i + 1:] for i in range(n)] + # 字母打多了一个 [word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(n - 1)] + # 字母打反了一个 [word[0:i] + c + word[i + 1:] for i in range(n) for c in alphabet] + # 字母打错了一个 [word[0:i] + c + word[i:] for i in range(n + 1) for c in alphabet]) # 字母打少了一个
五、返回编辑距离为2的单词
# 考虑编辑距离为2的单词 def known_edits2(word): return set(e2 for e1 in editsl(word) for e2 in editsl(e1) if e2 in NWORDS)
六、判断单词是否在语料库中
def known(words): return set(w for w in words if w in NWORDS)
七、纠正拼写错误的单词
优先考虑原单词a是否在语料库中,如果存在就返回原单词,不存在就考虑编辑距离为1的单词,返回使用频率最高的那个如果编辑距离为1的单词也不在语料库中,那么就考虑编辑距离为2的单词,同样,如果编辑距离为2的单词都不在语料库中,那么这可能是一个新的单词,直接返回单词本身
def correct(word): candidates = known([word]) or known(editsl(word)) or known_edits2(word) or [word] return max(candidates, key=lambda w: NWORDS[w])
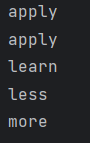
八、测试结果
print(correct('appl')) print(correct('appla')) print(correct('learw')) print(correct('tess')) print(correct('morw'))