JavaCV人脸识别三部曲之三:识别和预览
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
《JavaCV人脸识别三部曲》链接
本篇概览
-
作为《JavaCV人脸识别三部曲》的终篇,今天咱们要开发一个实用的功能:有人出现在摄像头中时,应用程序在预览窗口标注出此人的身份,效果如下图所示:

-
简单来说,本篇要做的事情如下:
- 理解重点概念:confidence
- 理解重点概念:threshold
- 编码
- 验证
- 今天编写的代码,主要功能如下图所示:

理解重点概念:confidence
-
confidence和threshold是OpenCV的人脸识别中非常重要的两个概念,咱们先把这两个概念搞清楚,再去编码就非常容易了
-
假设,咱们用下面六张照片训练出包含两个类别的模型:

-
用一张新的照片去训练好的模型中做识别,如下图,识别结果有两部分内容:label和confidence

-
先说lable,这个好理解,与训练时的lable一致(回顾上一篇的代码,lable如下图红框所示),前面图中lable等于2,表示被判定为郭富城:
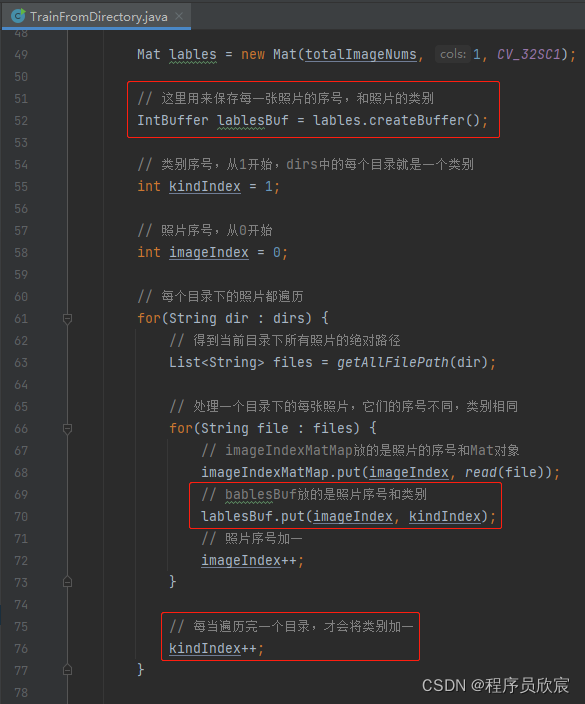
-
按照上面的说法,lable等于2就能确定照片中的人像是郭富城吗?
-
当然不能!!!此时confidence字段就非常重要了,先看JavaCV源码中对confidence的解释,如下图红框所示,我的理解是:与lable值相关联的置信度,或者说这张脸是郭富城的可能性:
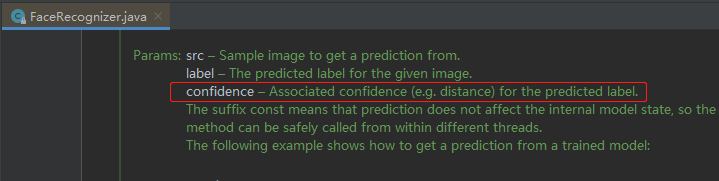
-
如果理解为可能性,那么问题来了,这是个double型的值,这个值越大,表示可能性越大还是越小?
-
上图并没有明说,但是那一句e.g. distance,让我想起了机器学习中的K-means,此时我脑海中的画面如下:

-若真如上图所示,那么显然confidence越小,是郭富城的可能性就越大了,接下来再去找一些权威的说法: -
OpenCV的官方论坛有个帖子的说法如下图:代码中的confidence变量属于命名不当,其含义不是可信度,而是与模型中的类别的距离:
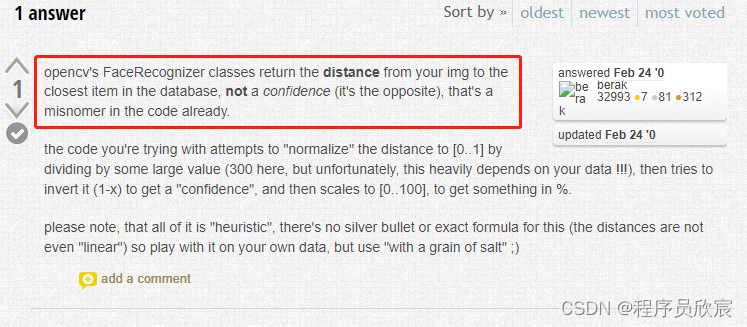
-
再看第二个解释,如下图红框,说得很清楚了,值越小,与模型中类别的相似度越高,0表示完全匹配:
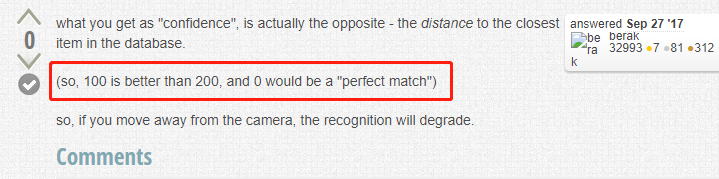
-
再看一个Stack Overflow的解释:

-
至此,相信您对confidence已经足够理解了,lable等于2,confidence=30.01,意思是:被识别照片与郭富城最相似,距离为30.01,距离越小,是郭富城的可能性越大
理解重点概念:threshold
- 在聊threshold之前,咱们先看一个场景,还是刘德华郭富城的模型,这次咱们拿喜洋洋的照片给模型识别,识别结果如下:

- 显然,模型不会告诉你照片里是谁,只会告诉你:和郭富城的距离是3000.01
- 看到这里,聪明的您可能会这么想:那我就写一段代码吧,识别结果的confidence如果太大(例如超过100),就判定用于识别的人不属于训练模型的任何一个类别
- 上述功能,OpenCV已经帮咱们想到了,那就是:threshold,翻译过来即门限,如果咱们设置了threshold等于100,那么,一旦距离超过100,OpenCV的lable返回值就是-1
- 理解了confidence和threshold,接下来可以写人脸识别的代码了,感谢咱们的充分准备,接下来是丝般顺滑的编码过程...
源码下载
- 《JavaCV人脸识别三部曲》的完整源码可在GitHub下载到,地址和链接信息如下表所示(https://github.com/zq2599/blog_demos):
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | [email protected]:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
- 这个git项目中有多个文件夹,本篇的源码在javacv-tutorials文件夹下,如下图红框所示:
- javacv-tutorials里面有多个子工程,《JavaCV人脸识别三部曲》系列的代码在simple-grab-push工程下:

编码:人脸识别服务
- 开始正式编码,今天咱们不会新建工程,而是继续使用《JavaCV的摄像头实战之一:基础》中创建的simple-grab-push工程
- 先定义一个Bean类PredictRlt.java,用来保存识别结果(lable和confidence字段):
package com.bolingcavalry.grabpush.extend;
import lombok.Data;
@Data
public class PredictRlt {
private int lable;
private double confidence;
}
- 然后把人脸识别有关的服务集中在RecognizeService.java中,方便主程序使用,代码如下,有几处要注意的地方稍后提到:
package com.bolingcavalry.grabpush.extend;
import com.bolingcavalry.grabpush.Constants;
import org.bytedeco.opencv.global.opencv_imgcodecs;
import org.bytedeco.opencv.opencv_core.Mat;
import org.bytedeco.opencv.opencv_core.Size;
import org.bytedeco.opencv.opencv_face.FaceRecognizer;
import org.bytedeco.opencv.opencv_face.FisherFaceRecognizer;
import static org.bytedeco.opencv.global.opencv_imgcodecs.IMREAD_GRAYSCALE;
import static org.bytedeco.opencv.global.opencv_imgproc.resize;
/**
* @author willzhao
* @version 1.0
* @description 把人脸识别的服务集中在这里
* @date 2021/12/12 21:32
*/
public class RecognizeService {
private FaceRecognizer faceRecognizer;
// 推理结果的标签
private int[] plabel;
// 推理结果的置信度
private double[] pconfidence;
// 推理结果
private PredictRlt predictRlt;
// 用于推理的图片尺寸,要和训练时的尺寸保持一致
private Size size= new Size(Constants.RESIZE_WIDTH, Constants.RESIZE_HEIGHT);
public RecognizeService(String modelPath) {
plabel = new int[1];
pconfidence = new double[1];
predictRlt = new PredictRlt();
// 识别类的实例化,与训练时相同
faceRecognizer = FisherFaceRecognizer.create();
// 加载的是训练时生成的模型
faceRecognizer.read(modelPath);
// 设置门限,这个可以根据您自身的情况不断调整
faceRecognizer.setThreshold(Constants.MAX_CONFIDENCE);
}
/**
* 将Mat实例给模型去推理
* @param mat
* @return
*/
public PredictRlt predict(Mat mat) {
// 调整到和训练一致的尺寸
resize(mat, mat, size);
boolean isFinish = false;
try {
// 推理(这一行可能抛出RuntimeException异常,因此要补货,否则会导致程序退出)
faceRecognizer.predict(mat, plabel, pconfidence);
isFinish = true;
} catch (RuntimeException runtimeException) {
runtimeException.printStackTrace();
}
// 如果发生过异常,就提前返回
if (!isFinish) {
return null;
}
// 将推理结果写入返回对象中
predictRlt.setLable(plabel[0]);
predictRlt.setConfidence(pconfidence[0]);
return predictRlt;
}
}
- 上述代码有以下几处需要注意:
- 构造方法中,通过faceRecognizer.setThreshold设置门限,我在实际使用中发现50比较合适,您可以根据自己的情况不断调整
- predict方法中,用于识别的图片要用resize方法调整大小,尺寸要和训练时的尺寸一致
- 实测发现,在一张照片中出现多个人脸时,faceRecognizer.predict可能抛出RuntimeException异常,因此这里要捕获异常,避免程序崩溃退出
编码:检测和识别
- 检测有关的接口DetectService.java,如下,和《JavaCV人脸识别三部曲之一:视频中的人脸保存为图片》中的完全一致:
package com.bolingcavalry.grabpush.extend;
import com.bolingcavalry.grabpush.Constants;
import org.bytedeco.javacv.Frame;
import org.bytedeco.javacv.OpenCVFrameConverter;
import org.bytedeco.opencv.opencv_core.*;
import org.bytedeco.opencv.opencv_objdetect.CascadeClassifier;
import static org.bytedeco.opencv.global.opencv_core.CV_8UC1;
import static org.bytedeco.opencv.global.opencv_imgcodecs.imwrite;
import static org.bytedeco.opencv.global.opencv_imgproc.*;
/**
* @author willzhao
* @version 1.0
* @description 检测工具的通用接口
* @date 2021/12/5 10:57
*/
public interface DetectService {
/**
* 根据传入的MAT构造相同尺寸的MAT,存放灰度图片用于以后的检测
* @param src 原始图片的MAT对象
* @return 相同尺寸的灰度图片的MAT对象
*/
static Mat buildGrayImage(Mat src) {
return new Mat(src.rows(), src.cols(), CV_8UC1);
}
/**
* 初始化操作,例如模型下载
* @throws Exception
*/
void init() throws Exception;
/**
* 得到原始帧,做识别,添加框选
* @param frame
* @return
*/
Frame convert(Frame frame);
/**
* 释放资源
*/
void releaseOutputResource();
}
- 然后就是DetectService的实现类DetectAndRecognizeService .java,功能是用摄像头的一帧图片检测人脸,再拿检测到的人脸给RecognizeService做识别,完整代码如下,有几处要注意的地方稍后提到:
package com.bolingcavalry.grabpush.extend;
import lombok.extern.slf4j.Slf4j;
import org.bytedeco.javacpp.Loader;
import org.bytedeco.javacv.Frame;
import org.bytedeco.javacv.OpenCVFrameConverter;
import org.bytedeco.opencv.opencv_core.*;
import org.bytedeco.opencv.opencv_objdetect.CascadeClassifier;
import java.io.File;
import java.net.URL;
import java.util.Map;
import static org.bytedeco.opencv.global.opencv_imgproc.*;
/**
* @author willzhao
* @version 1.0
* @description 音频相关的服务
* @date 2021/12/3 8:09
*/
@Slf4j
public class DetectAndRecognizeService implements DetectService {
/**
* 每一帧原始图片的对象
*/
private Mat grabbedImage = null;
/**
* 原始图片对应的灰度图片对象
*/
private Mat grayImage = null;
/**
* 分类器
*/
private CascadeClassifier classifier;
/**
* 转换器
*/
private OpenCVFrameConverter.ToMat converter = new OpenCVFrameConverter.ToMat();
/**
* 检测模型文件的下载地址
*/
private String detectModelFileUrl;
/**
* 处理每一帧的服务
*/
private RecognizeService recognizeService;
/**
* 为了显示的时候更加友好,给每个分类对应一个名称
*/
private Map<Integer, String> kindNameMap;
/**
* 构造方法
* @param detectModelFileUrl
* @param recognizeModelFilePath
* @param kindNameMap
*/
public DetectAndRecognizeService(String detectModelFileUrl, String recognizeModelFilePath, Map<Integer, String> kindNameMap) {
this.detectModelFileUrl = detectModelFileUrl;
this.recognizeService = new RecognizeService(recognizeModelFilePath);
this.kindNameMap = kindNameMap;
}
/**
* 音频采样对象的初始化
* @throws Exception
*/
@Override
public void init() throws Exception {
// 下载模型文件
URL url = new URL(detectModelFileUrl);
File file = Loader.cacheResource(url);
// 模型文件下载后的完整地址
String classifierName = file.getAbsolutePath();
// 根据模型文件实例化分类器
classifier = new CascadeClassifier(classifierName);
if (classifier == null) {
log.error("Error loading classifier file [{}]", classifierName);
System.exit(1);
}
}
@Override
public Frame convert(Frame frame) {
// 由帧转为Mat
grabbedImage = converter.convert(frame);
// 灰度Mat,用于检测
if (null==grayImage) {
grayImage = DetectService.buildGrayImage(grabbedImage);
}
// 进行人脸识别,根据结果做处理得到预览窗口显示的帧
return detectAndRecoginze(classifier, converter, frame, grabbedImage, grayImage, recognizeService, kindNameMap);
}
/**
* 程序结束前,释放人脸识别的资源
*/
@Override
public void releaseOutputResource() {
if (null!=grabbedImage) {
grabbedImage.release();
}
if (null!=grayImage) {
grayImage.release();
}
if (null==classifier) {
classifier.close();
}
}
/**
* 检测图片,将检测结果用矩形标注在原始图片上
* @param classifier 分类器
* @param converter Frame和mat的转换器
* @param rawFrame 原始视频帧
* @param grabbedImage 原始视频帧对应的mat
* @param grayImage 存放灰度图片的mat
* @param kindNameMap 每个分类编号对应的名称
* @return 标注了识别结果的视频帧
*/
static Frame detectAndRecoginze(CascadeClassifier classifier,
OpenCVFrameConverter.ToMat converter,
Frame rawFrame,
Mat grabbedImage,
Mat grayImage,
RecognizeService recognizeService,
Map<Integer, String> kindNameMap) {
// 当前图片转为灰度图片
cvtColor(grabbedImage, grayImage, CV_BGR2GRAY);
// 存放检测结果的容器
RectVector objects = new RectVector();
// 开始检测
classifier.detectMultiScale(grayImage, objects);
// 检测结果总数
long total = objects.size();
// 如果没有检测到结果,就用原始帧返回
if (total<1) {
return rawFrame;
}
PredictRlt predictRlt;
int pos_x;
int pos_y;
int lable;
double confidence;
String content;
// 如果有检测结果,就根据结果的数据构造矩形框,画在原图上
for (long i = 0; i < total; i++) {
Rect r = objects.get(i);
// 核心代码,把检测到的人脸拿去识别
predictRlt = recognizeService.predict(new Mat(grayImage, r));
// 如果返回为空,表示出现过异常,就执行下一个
if (null==predictRlt) {
System.out.println("return null");
continue;
}
// 分类的编号(训练时只有1和2,这里只有有三个值,1和2与训练的分类一致,还有个-1表示没有匹配上)
lable = predictRlt.getLable();
// 与模型中的分类的距离,值越小表示相似度越高
confidence = predictRlt.getConfidence();
// 得到分类编号后,从map中取得名字,用来显示
if (kindNameMap.containsKey(predictRlt.getLable())) {
content = String.format("%s, confidence : %.4f", kindNameMap.get(lable), confidence);
} else {
// 取不到名字的时候,就显示unknown
content = "unknown(" + predictRlt.getLable() + ")";
System.out.println(content);
}
int x = r.x(), y = r.y(), w = r.width(), h = r.height();
rectangle(grabbedImage, new Point(x, y), new Point(x + w, y + h), Scalar.RED, 1, CV_AA, 0);
pos_x = Math.max(r.tl().x()-10, 0);
pos_y = Math.max(r.tl().y()-10, 0);
putText(grabbedImage, content, new Point(pos_x, pos_y), FONT_HERSHEY_PLAIN, 1.5, new Scalar(0,255,0,2.0));
}
// 释放检测结果资源
objects.close();
// 将标注过的图片转为帧,返回
return converter.convert(grabbedImage);
}
}
- 上述代码有几处要注意:
- 重点关注detectAndRecoginze方法,这里面先调用classifier.detectMultiScale检测出当前照片所有的人脸,然后把每一张人脸交个recognizeService进行识别,
- 识别结果的lable是个int型的,看起来不够友好,因此从kindNameMap中根据lable找出对应的名称来
- 最终给每个头像添加矩形框,还在左上角添加识别结果,以及confidence的值
- 处理完毕后转为Frame对象返回,这样的帧显示在预览页面,效果就是视频中每个人被框选出来,并带有身份
- 现在核心代码已经写完,需要再写一些代码来使用DetectAndRecognizeService
编码:运行框架
- 《JavaCV的摄像头实战之一:基础》创建的simple-grab-push工程中已经准备好了父类AbstractCameraApplication,所以本篇继续使用该工程,创建子类实现那些抽象方法即可
- 编码前先回顾父类的基础结构,如下图,粗体是父类定义的各个方法,红色块都是需要子类来实现抽象方法,所以接下来,咱们以本地窗口预览为目标实现这三个红色方法即可:

- 新建文件PreviewCameraWithIdentify.java,这是AbstractCameraApplication的子类,其代码很简单,接下来按上图顺序依次说明
- 先定义CanvasFrame类型的成员变量previewCanvas,这是展示视频帧的本地窗口:
protected CanvasFrame previewCanvas
- 把前面创建的DetectService作为成员变量,后面检测的时候会用到:
/**
* 检测工具接口
*/
private DetectService detectService;
- PreviewCameraWithIdentify的构造方法,接受DetectService的实例:
/**
* 不同的检测工具,可以通过构造方法传入
* @param detectService
*/
public PreviewCameraWithIdentify(DetectService detectService) {
this.detectService = detectService;
}
- 然后是初始化操作,可见是previewCanvas的实例化和参数设置,还有检测、识别的初始化操作:
@Override
protected void initOutput() throws Exception {
previewCanvas = new CanvasFrame("摄像头预览和身份识别", CanvasFrame.getDefaultGamma() / grabber.getGamma());
previewCanvas.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
previewCanvas.setAlwaysOnTop(true);
// 检测服务的初始化操作
detectService.init();
}
- 接下来是output方法,定义了拿到每一帧视频数据后做什么事情,这里调用了detectService.convert检测人脸并保存图片,然后在本地窗口显示:
@Override
protected void output(Frame frame) {
// 原始帧先交给检测服务处理,这个处理包括物体检测,再将检测结果标注在原始图片上,
// 然后转换为帧返回
Frame detectedFrame = detectService.convert(frame);
// 预览窗口上显示的帧是标注了检测结果的帧
previewCanvas.showImage(detectedFrame);
}
- 最后是处理视频的循环结束后,程序退出前要做的事情,先关闭本地窗口,再释放检测服务的资源:
@Override
protected void releaseOutputResource() {
if (null!= previewCanvas) {
previewCanvas.dispose();
}
// 检测工具也要释放资源
detectService.releaseOutputResource();
}
- 由于检测有些耗时,所以两帧之间的间隔时间要低于普通预览:
@Override
protected int getInterval() {
return super.getInterval()/8;
}
- 至此,功能已开发完成,再写上main方法,代码如下,有几处要注意的地方稍后说明:
public static void main(String[] args) {
String modelFileUrl = "https://raw.github.com/opencv/opencv/master/data/haarcascades/haarcascade_frontalface_alt.xml";
String recognizeModelFilePath = "E:\\temp\\202112\\18\\001\\faceRecognizer.xml";
// 这里分类编号的身份的对应关系,和之前训练时候的设定要保持一致
Map<Integer, String> kindNameMap = new HashMap();
kindNameMap.put(1, "Man");
kindNameMap.put(2, "Woman");
// 检测服务
DetectService detectService = new DetectAndRecognizeService(modelFileUrl,recognizeModelFilePath, kindNameMap);
// 开始检测
new PreviewCameraWithIdentify(detectService).action(1000);
}
- 上述main方法中,有以下几处需要注意:
- kindNameMap是个HashMap,里面放这每个分类编号对应的名称,我训练的模型中包含了两位群众演员的头像,给他们分别起名Man和Woman
- modelFileUrl是人脸检测时用到的模型地址
- recognizeModelFilePath是人脸识别时用到的模型地址,这个模型是《JavaCV人脸识别三部曲之二:训练》一文中训练的模型
- 至此,人脸识别的代码已经写完,运行main方法,请几位群众演员来到摄像头前面,验证效果吧
验证
-
程序运行起来后,请名为Man的群众演员A站在摄像头前面,如下图,识别成功:

-
接下来,请名为Woman的群众演员B过来,和群众演员A同框,如下图,同时识别成功,不过偶尔会识别错误,提示成unknown(-1):

-
再请一个没有参与训练的小群众演员过来,与A同框,此刻的识别也是准确的,小演员被标注为unknown(-1):

-
去看程序的控制台,发现FaceRecognizer.predict方法会抛出异常,幸好程序捕获了异常,不会把整个进程中断退出:

-
至此,整个《JavaCV人脸识别三部曲》全部完成,如果您是位java程序员,正在寻找人脸识别相关的方案,希望本系列能给您一些参考
-
另外《JavaCV人脸识别三部曲》是《JavaCV的摄像头实战》系列的分支,作为主干的《JavaCV的摄像头实战》依然在持续更新中,欣宸原创会继续与您一路相伴,学习、实战、提升