Apache DolphinScheduler数仓任务管理规范
前言: 大数据领域对多种任务都有调度需求,以离线数仓的任务应用最多,许多团队在调研开源产品后,选择Apache DolphinScheduler(以下简称DS)作为调度场景的技术选型。得益于DS优秀的特性,在对数仓任务做运维和管理的时候,往往比较随意,或将所有任务节点写到一个工作流里,或将每个逻辑节点单独定义一个工作流, 缺少与数仓建模对应的任务管理规范;
这造成了数据管理困难和异常容错繁琐等痛点,本文基于数仓建模标准的方法论,构建一套用于DS管理数仓任务的规范,避免以上痛点。
海豚调度数仓任务现状分析
本文缘起社区负责人的痛点定位;在使用DS做数仓任务管理时,数据建模分层落地到调度上缺少规范,社区用户用起来比较乱,基于这个原因,写了这篇文章。
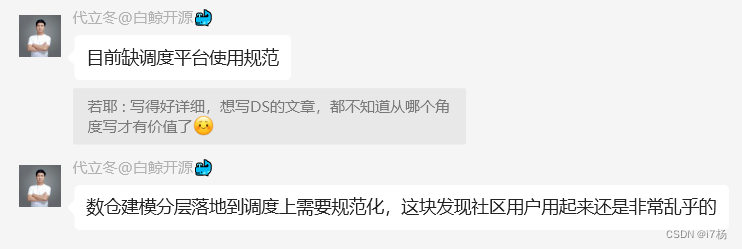
在使用调度能力的时候,一些常见的场景如下:
一个任务流构建数仓所有的逻辑节点
Apache DolphinScheduler里有任务血缘的概念,这个概念和数据血缘有许多类似的地方;在构建调度任务的时候,用户容易将任务血缘和数据血缘混淆,希望在构建数仓生命周期的时候,通过任务血缘呈现出数据血缘的关系,这导致丢失了数据建模规范的分层管理。
类似例子如下:
单个工作流:

包含所有计算逻辑:

优点:这样做的好处是可以在一个工作流里直观的复现数据建模;
缺点:对于数据管理困难,只能人为的观察定位数据情况;
任务运行异常后,容错困难,要排查所有逻辑节点,并将计算逻辑回滚,这是特别繁琐的过程;
每个逻辑节点构建一个任务流
除了将整个数仓的逻辑包装到一个工作流,还有另外一种方式:将每个逻辑节点包装成一个工作流;这种能很好的将计算逻辑解耦,任务运行异常的时候逻辑回归也清晰简单;但是依旧没有做到合理的数仓建模分层管理,且操作繁琐,面对超大量任务时,创建工作流将成为一种负担。
类似例子如下:
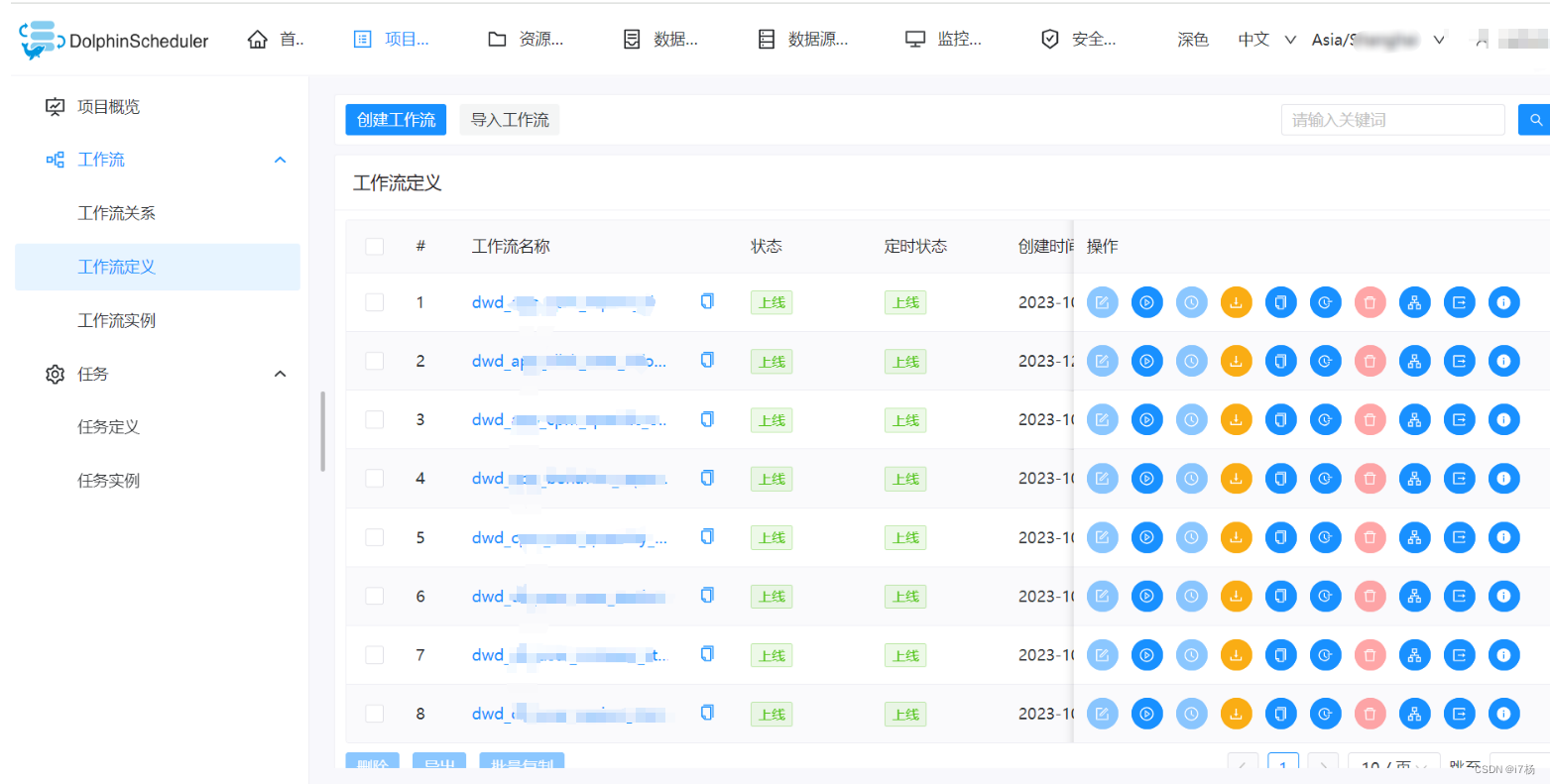
优点:优秀的异常容错,任务出现异常计算的时候,前后任务逻辑就能异常回滚重跑;
缺点:任务流创建繁琐,且没有做好数仓规范的数据分层管理。
数仓任务管理调度****需求分析
从数仓的视角,任务调度核心需求是:任务类型、依赖关系、定时调度、任务优先级,以及数仓分层管理,层级依赖(调度系统的视角,还有高可用、告警、资源管理、用户安全、易用性、可扩展等能力)。
任务类型、依赖关系、定时调度、任务优先级是系统提供的能力,数仓分层管理和层级依赖是调度能力之上的任务管理规范。这里参考数据建模规范构建与之对应的任务管理规范。
数据建模架构如下:
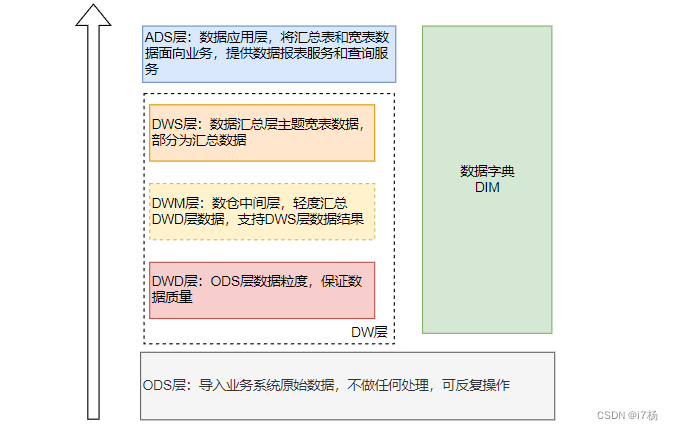
数据建模到数仓开发过程中需要关注4点:
-
逻辑开发:数据需求的实现;
-
数据管理:各层级数据划分;
-
开发依赖:数据层级依赖实现;
-
异常容错:异常任务定位和数据复原重跑。
构建在调度系统之上的数仓任务编排规范,需要满足以上要求。
数仓开发任务管理规范
为了和数据建模规范保持一致,我们按照数据建模的分层理论,设计调度任务的编排规范。
从顶层设计上将工作流定义为3类:
-
数仓分层工作流:ODS、DIM、DW、ADS每层一个工作流;DW层可以根据业务需求,细分出三个DWD、DWM、DWS等好实现业务需求的单独任务流管理;
-
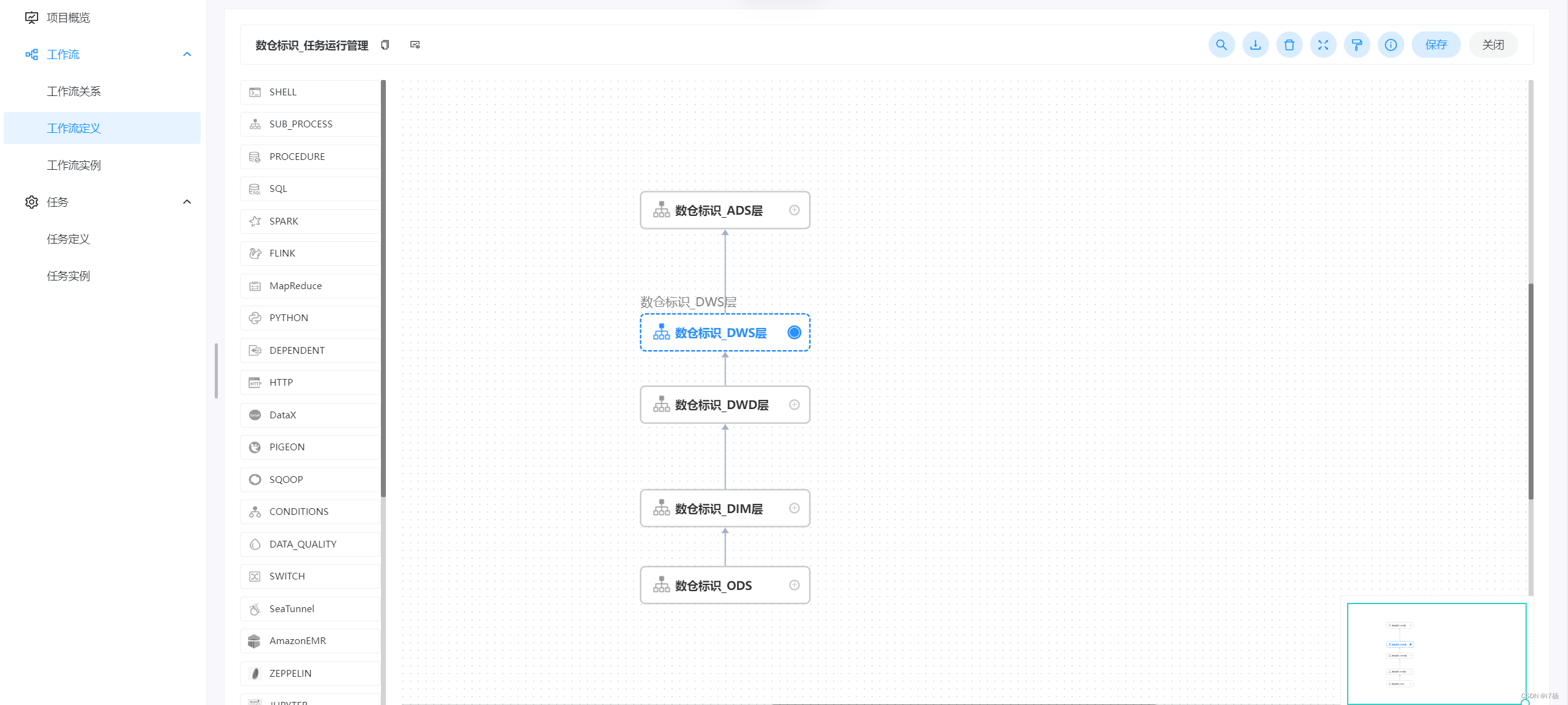
数仓任务Master管理工作流:将数仓分层,按照开发依赖串联到一个工作流中统一管理;
-
异常容错工作流:数仓运行过程中,中途出错或者结果异常,需要数据环境复原,就可以将中间表清理逻辑包装在异常容错工作流,做统一数据清理,然后再从头跑数仓任务。
数仓开发工作流规范如下:
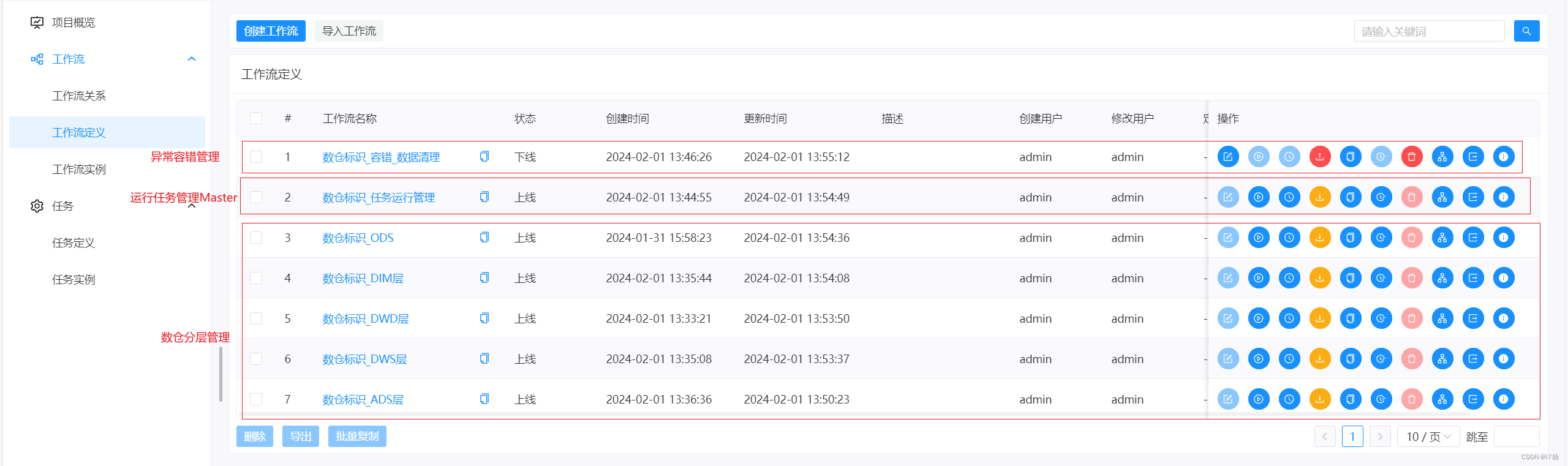
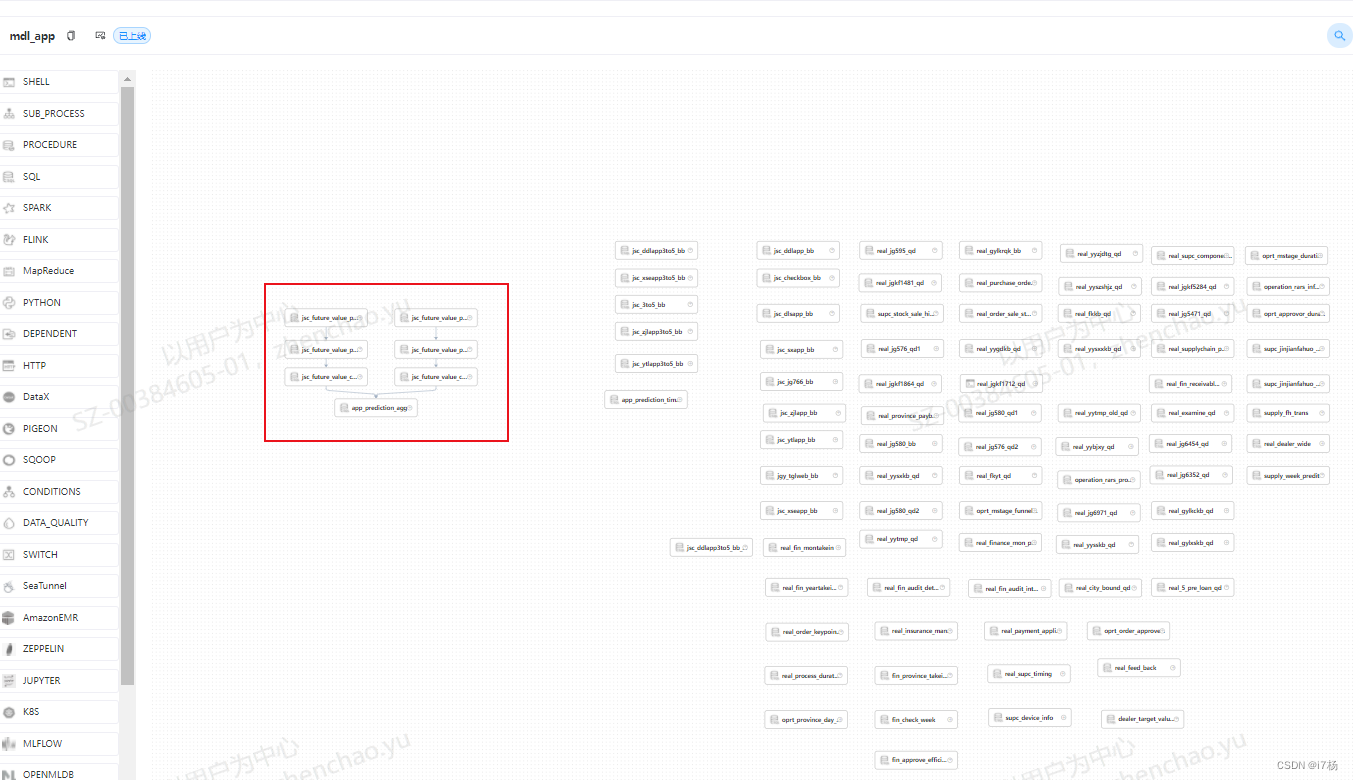
数仓每层工作流只关注每层的逻辑;以ODS层为例,该层提供多个数据应用方数据支持,所以在这个任务工作流里,构建这一层的所有逻辑节点:
运行任务管理Master工作流,节点布局规范如下:
异常容错工作流:
这一个工作流,主要是为了在任务运行异常时,删除中间表计算的新增结果;
依据数据模型的表设计,想将DS的任务血缘当简单数据血缘使用需求的,可以在这一个工作流里将节点关联,数据清理和任务血缘不冲突,还可以顺便检测数据清理情况。
结语
除此之外,数仓还有一些局部概念需要在任务编排上做规范,比如需要将DS项目和数仓映射,一个DS项目管理一个数仓;需要将数据集市和工作流映射,ADS层有多种数据应用场景就拆分成多个工作流等;本文的规范是以数仓标准数据模型构建的,如果有特殊需求,可以在这个任务管理规范基础上做相应调整。
如果这份博客对大家有帮助,希望各位给i7杨一个免费的点赞👍作为鼓励,并评论收藏一下⭐,谢谢大家!!!
制作不易,如果大家有什么疑问或给i7杨的意见,欢迎评论区留言。
本文由 白鲸开源 提供发布支持!
热门相关:影帝偏要住我家 玉堂金闺 北宋大表哥 北宋闲王 王妃不乖:独宠倾城妃