修改数据: UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [ WHERE 条件 ];
例: UPDATE emp SET name = 'Jack' WHERE id = 1;
删除数据: DELETE FROM 表名 [ WHERE 条件 ];
DQL(数据查询语言)
语法:
SELECT
字段列表
FROM
表名字段
WHERE
条件列表
GROUP BY
分组字段列表
HAVING
分组后的条件列表
ORDER BY
排序字段列表
LIMIT
分页参数
基础查询
查询多个字段: SELECT 字段1, 字段2, 字段3, ... FROM 表名; SELECT * FROM 表名;
设置别名: SELECT 字段1 [ AS 别名1 ], 字段2 [ AS 别名2 ], 字段3 [ AS 别名3 ], ... FROM 表名; SELECT 字段1 [ 别名1 ], 字段2 [ 别名2 ], 字段3 [ 别名3 ], ... FROM 表名;
去除重复记录: SELECT DISTINCT 字段列表 FROM 表名;
转义: SELECT * FROM 表名 WHERE name LIKE '/_张三' ESCAPE '/'
/ 之后的_不作为通配符
条件查询
语法: SELECT 字段列表 FROM 表名 WHERE 条件列表;
条件:
比较运算符
功能
>
大于
>=
大于等于
<
小于
<=
小于等于
=
等于
<> 或 !=
不等于
BETWEEN ... AND ...
在某个范围内(含最小、最大值)
IN(...)
在in之后的列表中的值,多选一
LIKE 占位符
模糊匹配(_匹配单个字符,%匹配任意个字符)
IS NULL
是NULL
逻辑运算符
功能
AND 或 &&
并且(多个条件同时成立)
OR 或 ||
或者(多个条件任意一个成立)
NOT 或 !
非,不是
例子:
-- 年龄等于30
select * from employee where age = 30;
-- 年龄小于30
select * from employee where age < 30;
-- 小于等于
select * from employee where age <= 30;
-- 没有身份证
select * from employee where idcard is null or idcard = '';
-- 有身份证
select * from employee where idcard;
select * from employee where idcard is not null;
-- 不等于
select * from employee where age != 30;
-- 年龄在20到30之间
select * from employee where age between 20 and 30;
select * from employee where age >= 20 and age <= 30;
-- 下面语句不报错,但查不到任何信息
select * from employee where age between 30 and 20;
-- 性别为女且年龄小于30
select * from employee where age < 30 and gender = '女';
-- 年龄等于25或30或35
select * from employee where age = 25 or age = 30 or age = 35;
select * from employee where age in (25, 30, 35);
-- 姓名为两个字
select * from employee where name like '__';
-- 身份证最后为X
select * from employee where idcard like '%X';
聚合查询(聚合函数)
常见聚合函数:
函数
功能
count
统计数量
max
最大值
min
最小值
avg
平均值
sum
求和
语法: SELECT 聚合函数(字段列表) FROM 表名;
例: SELECT count(id) from employee where workaddress = "广东省";
分组查询
语法: SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后的过滤条件 ];
-- 根据性别分组,统计男性和女性数量(只显示分组数量,不显示哪个是男哪个是女)
select count(*) from employee group by gender;
-- 根据性别分组,统计男性和女性数量
select gender, count(*) from employee group by gender;
-- 根据性别分组,统计男性和女性的平均年龄
select gender, avg(age) from employee group by gender;
-- 年龄小于45,并根据工作地址分组
select workaddress, count(*) from employee where age < 45 group by workaddress;
-- 年龄小于45,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress, count(*) address_count from employee where age < 45 group by workaddress having address_count >= 3;
注意事项
执行顺序:where > 聚合函数 > having
分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义
排序查询
语法: SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
ASC: 升序(默认)
DESC: 降序
例子:
-- 根据年龄升序排序
SELECT * FROM employee ORDER BY age ASC;
SELECT * FROM employee ORDER BY age;
-- 两字段排序,根据年龄升序排序,入职时间降序排序(如果年龄相同那么就按这个)
SELECT * FROM employee ORDER BY age ASC, entrydate DESC;
注意事项
如果是多字段排序,当第一个字段值相同时,才会根据第二个字段进行排序
分页查询
语法: SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;
例子:
-- 查询第一页数据,展示10条
SELECT * FROM employee LIMIT 0, 10;
-- 查询第二页
SELECT * FROM employee LIMIT 10, 10;
注意事项
起始索引从0开始,起始索引 = (查询页码 - 1) * 每页显示记录数
分页查询是数据库的方言,不同数据库有不同实现,MySQL是LIMIT
如果查询的是第一页数据,起始索引可以省略,直接简写 LIMIT 10
DQL执行顺序
FROM -> join -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
DCL
管理用户
查询用户:
USER mysql;
SELECT * FROM user;
创建用户: CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';
修改用户密码: ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码';
删除用户: DROP USER '用户名'@'主机名';
例子:
-- 创建用户test,只能在当前主机localhost访问
create user 'test'@'localhost' identified by '123456';
-- 创建用户test,能在任意主机访问
create user 'test'@'%' identified by '123456';
create user 'test' identified by '123456';
-- 修改密码
alter user 'test'@'localhost' identified with mysql_native_password by '1234';
-- 删除用户
drop user 'test'@'localhost';
CASE WHEN [ val1 ] THEN [ res1 ] ... ELSE [ default ] END
如果val1为true,返回res1,... 否则返回default默认值
CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] ... ELSE [ default ] END
如果expr的值等于val1,返回res1,... 否则返回default默认值
例子:
select
name,
(case when age > 30 then '中年' else '青年' end)
from employee;
select
name,
(case workaddress when '北京市' then '一线城市' when '上海市' then '一线城市' else '二线城市' end) as '工作地址'
from employee;
约束
概念:约束是用来作用于表中字段上的规则,用于限制存储在表中的数据。
目的:保证数据库中的数据的正确、有效性和完整性
分类:
约束
描述
关键字
非空约束
限制该字段的数据不能为null
NOT NULL
唯一约束
保证该字段的所有数据都是唯一、不重复的
UNIQUE
主键约束
主键是一行数据的唯一标识,要求非空且唯一
PRIMARY KEY
默认约束
保存数据时,如果未指定该字段的值,则采用默认值
DEFAULT
检查约束(8.0.1版本后)
保证字段值满足某一个条件
CHECK
外键约束
用来让两张图的数据之间建立连接,保证数据的一致性和完整性
FOREIGN KEY
约束是作用于表中字段上的,可以再创建表/修改表的时候添加约束。
常用约束
约束条件
关键字
主键
PRIMARY KEY
自动增长
AUTO_INCREMENT
不为空
NOT NULL
唯一
UNIQUE
逻辑条件
CHECK
默认值
DEFAULT
例子:
create table user(
id int primary key auto_increment,
name varchar(10) not null unique,
age int check(age > 0 and age < 120),
status char(1) default '1',
gender char(1)
);
合并查询(笛卡尔积,会展示所有组合结果): select * from employee, dept;
笛卡尔积:两个集合A集合和B集合的所有组合情况(在多表查询时,需要消除无效的笛卡尔积)
消除无效笛卡尔积: select * from employee, dept where employee.dept = dept.id;
内连接查询
内连接查询的是两张表交集的部分
隐式内连接: SELECT 字段列表 FROM 表1, 表2 WHERE 条件 ...;
显式内连接: SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ...;
显式性能比隐式高
inner join显式内连接是hashtable连接比较 ,O(Log N)
where隐式内连接是取笛卡尔积过滤,O(N**2)
例子:
-- 查询员工姓名,及关联的部门的名称
-- 隐式
select e.name, d.name from employee as e, dept as d where e.dept = d.id;
-- 显式
select e.name, d.name from employee as e inner join dept as d on e.dept = d.id;
外连接查询
左外连接:
查询左表所有数据,以及两张表交集部分数据 SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ...;
相当于查询表1的所有数据,包含表1和表2交集部分数据
右外连接:
查询右表所有数据,以及两张表交集部分数据 SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ...;
例子:
-- 左
select e.*, d.name from employee as e left outer join dept as d on e.dept = d.id;
select d.name, e.* from dept d left outer join emp e on e.dept = d.id; -- 这条语句与下面的语句效果一样
-- 右
select d.name, e.* from employee as e right outer join dept as d on e.dept = d.id;
左连接可以查询到没有dept的employee,右连接可以查询到没有employee的dept
自连接查询
当前表与自身的连接查询,自连接必须使用表别名
语法: SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ...;
自连接查询,可以是内连接查询,也可以是外连接查询
例子:
-- 查询员工及其所属领导的名字
select a.name, b.name from employee a, employee b where a.manager = b.id;
-- 没有领导的也查询出来
select a.name, b.name from employee a left join employee b on a.manager = b.id;
连接查询编写规范
当使用join时,又有需要限制条件如:xxx字段=1。规则:join连接表,where处理条件
例子:
①表A左连接表B ②限制表A的id为2 ③限制表B的id为3
select A.id,B.id
from A
left join B on A.id=B.aid and B.id=3
where A.id=2
SELECT 字段列表 FROM 表A ...
UNION [ALL]
SELECT 字段列表 FROM 表B ...
注意事项
union去重并排序,union all直接返回合并的结果,不去重也不排序;
union all比union性能好;
联合查询比使用or效率高,不会使索引失效
子查询
SQL语句中嵌套SELECT语句,称谓嵌套查询,又称子查询。 SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2); 子查询外部的语句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一个
根据子查询结果可以分为:
标量子查询(子查询结果为单个值)
列子查询(子查询结果为一列)
行子查询(子查询结果为一行)
表子查询(子查询结果为多行多列)
根据子查询位置可分为:
WHERE 之后
FROM 之后
SELECT 之后
标量子查询
子查询返回的结果是单个值(数字、字符串、日期等)。
常用操作符:- < > > >= < <=
例子:
-- 查询销售部所有员工
select id from dept where name = '销售部';
-- 根据销售部部门ID,查询员工信息
select * from employee where dept = 4;
-- 合并(子查询)
select * from employee where dept = (select id from dept where name = '销售部');
-- 查询xxx入职之后的员工信息
select * from employee where entrydate > (select entrydate from employee where name = 'xxx');
列子查询
返回的结果是一列(可以是多行)。
常用操作符:
操作符
描述
IN
在指定的集合范围内,多选一
NOT IN
不在指定的集合范围内
ANY
子查询返回列表中,有任意一个满足即可
SOME
与ANY等同,使用SOME的地方都可以使用ANY
ALL
子查询返回列表的所有值都必须满足
例子:
-- 查询销售部和市场部的所有员工信息
select * from employee where dept in (select id from dept where name = '销售部' or name = '市场部');
-- 查询比财务部所有人工资都高的员工信息
select * from employee where salary > all(select salary from employee where dept = (select id from dept where name = '财务部'));
-- 查询比研发部任意一人工资高的员工信息
select * from employee where salary > any (select salary from employee where dept = (select id from dept where name = '研发部'));
行子查询
返回的结果是一行(可以是多列)。
常用操作符:=, <, >, IN, NOT IN
例子:
-- 查询与xxx的薪资及直属领导相同的员工信息
select * from employee where (salary, manager) = (12500, 1);
select * from employee where (salary, manager) = (select salary, manager from employee where name = 'xxx');
-- 查询与xxx1,xxx2的职位和薪资相同的员工
select * from employee where (job, salary) in (select job, salary from employee where name = 'xxx1' or name = 'xxx2');
-- 查询入职日期是2006-01-01之后的员工,及其部门信息
select e.*, d.* from (select * from employee where entrydate > '2006-01-01') as e left join dept as d on e.dept = d.id;
-- 1. 查询张三账户余额
select * from account where name = '张三';
-- 2. 将张三账户余额-1000
update account set money = money - 1000 where name = '张三';
-- 此语句出错后张三钱减少但是李四钱没有增加
模拟sql语句错误
-- 3. 将李四账户余额+1000
update account set money = money + 1000 where name = '李四';
-- 查看事务提交方式
SELECT @@AUTOCOMMIT;
-- 设置事务提交方式,1为自动提交,0为手动提交,该设置只对当前会话有效
SET @@AUTOCOMMIT = 0;
-- 提交事务
COMMIT;
-- 回滚事务
ROLLBACK;
-- 设置手动提交后上面代码改为:
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
update account set money = money + 1000 where name = '李四';
commit;
操作方式二:
开启事务: START TRANSACTION 或 BEGIN TRANSACTION;
提交事务: COMMIT;
回滚事务: ROLLBACK;
操作实例:
start transaction;
select * from account where name = '张三';
update account set money = money - 1000 where name = '张三';
update account set money = money + 1000 where name = '李四';
commit;
show profile 能在做SQL优化时帮我们了解时间都耗费在哪里。通过 have_profiling 参数,能看到当前 MySQL 是否支持 profile 操作:
SELECT @@have_profiling;
profiling 默认关闭,可以通过set语句在session/global级别开启 profiling: SET profiling = 1;
查看所有语句的耗时: show profiles;
查看指定query_id的SQL语句各个阶段的耗时: show profile for query query_id;
查看指定query_id的SQL语句CPU的使用情况 show profile cpu for query query_id;
创建索引: CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...);
如果不加 CREATE 后面不加索引类型参数,则创建的是常规索引
查看索引: SHOW INDEX FROM table_name;
删除索引: DROP INDEX index_name ON table_name;
案例:
-- name字段为姓名字段,该字段的值可能会重复,为该字段创建索引
create index idx_user_name on tb_user(name);
-- phone手机号字段的值非空,且唯一,为该字段创建唯一索引
create unique index idx_user_phone on tb_user (phone);
-- 为profession, age, status创建联合索引
create index idx_user_pro_age_stat on tb_user(profession, age, status);
-- 为email建立合适的索引来提升查询效率
create index idx_user_email on tb_user(email);
-- 删除索引
drop index idx_user_email on tb_user;
#右侧status不会走索引,profession和age会走索引
explain select * from tb_user where profession = "软件工程" and age > 30 and status=0;
#右侧status会走索引,profession和age会走索引
explain select * from tb_user where profession = "软件工程" and age >= 30 and status=0;
索引失效情况
在索引列上进行运算操作,索引将失效。如:explain select * from tb_user where substring(phone, 10, 2) = '15'; 换成 explain select * from tb_user where phone = '17799990015';这是可以的。
这里的运算操作包含:函数、类型转换等
字符串类型字段使用时,不加引号会导致隐式类型转换,索引将失效。如:explain select * from tb_user where phone = 17799990015;,此处phone的值没有加引号
模糊查询中,字符开头的都会导致索引失效,如:%我、_你
① 如果仅仅是尾部模糊匹配,索引不会是失效;explain select * from tb_user where profession like '软件%';
② 如果是头部模糊匹配,索引失效。如:explain select * from tb_user where profession like '%工程';,
③ 前后都有 % 也会失效。
用 or 分割开的条件,如果 or 其中一个条件的列没有索引,那么涉及的索引都不会被用到。
# id有聚集索引,age没有索引。因为用or连接,所以id也不走索引了
explain select * from tb user where id = 10 or age = 23;
如果 MySQL 评估使用索引比全表更慢,则不使用索引。
# 不走索引,走全表扫描。因为该表里大部分数据都大于这个值,走全表扫描更快
explain select * from tb_user where phone >= 17799990000;
SQL 提示
SQL提示就是指定索引
是优化数据库的一个重要手段,简单来说,就是在SQL语句中加入一些人为的提示来达到优化操作的目的。
建议使用索引:use index(idx_user_pro) explain select * from tb_user use index(idx_user_pro) where profession="软件工程";
不使用哪个索引:ignore index(idx_user_pro) explain select * from tb_user ignore index(idx_user_pro) where profession="软件工程";
必须使用哪个索引:force index(idx_user_pro) explain select * from tb_user force index(idx_user_pro) where profession="软件工程";
use 是建议,实际使用哪个索引 MySQL 还会自己权衡运行速度去更改,force就是无论如何都强制使用该索引。
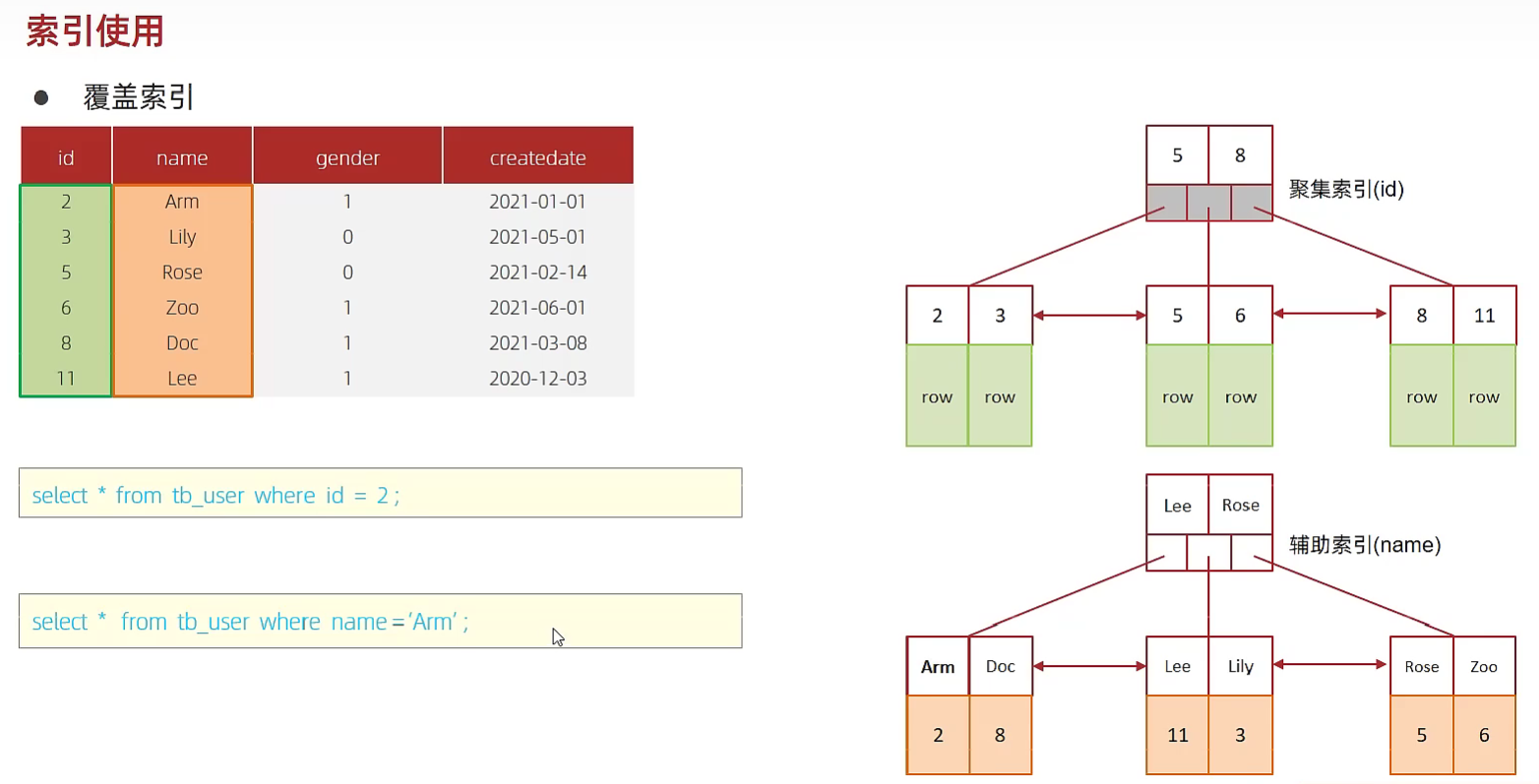
覆盖索引&回表查询
覆盖索引:查询条件使用了索引,并且需要返回的列在该索引中已经全部能找到。
explain 语句中 extra 字段含义: using index condition:查找使用了索引,但是需要回表查询数据 using where; using index;:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询
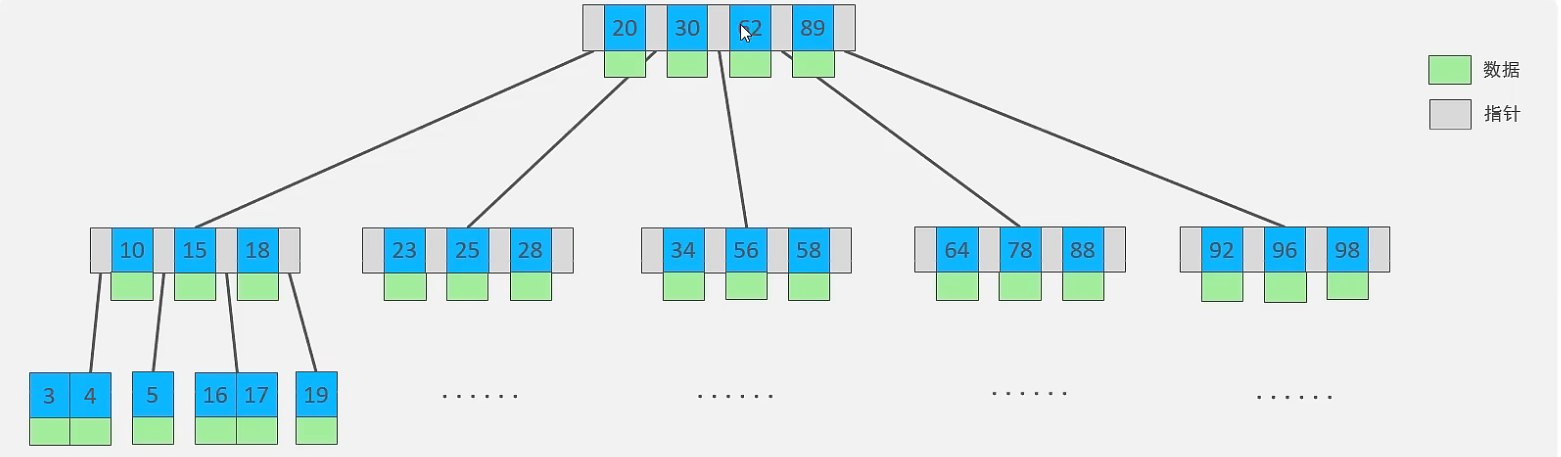
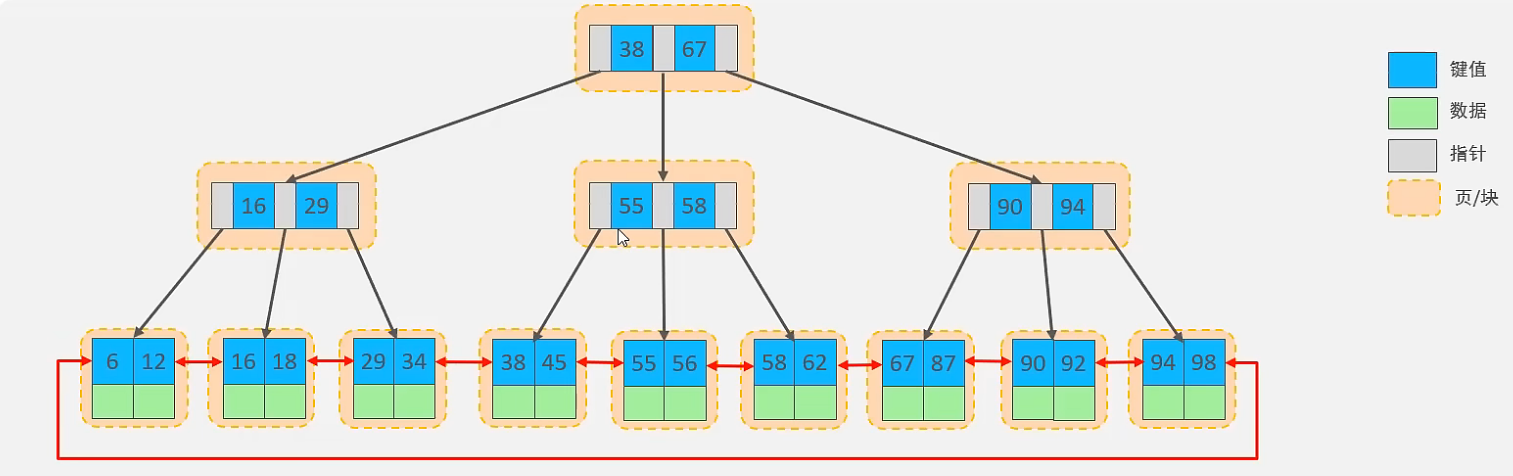
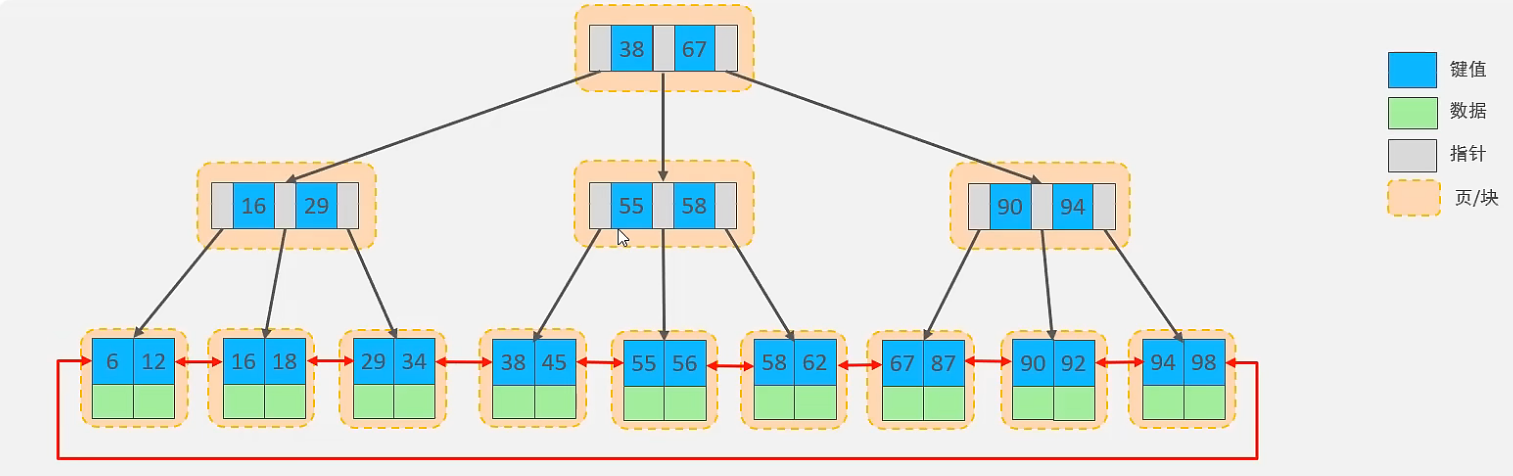
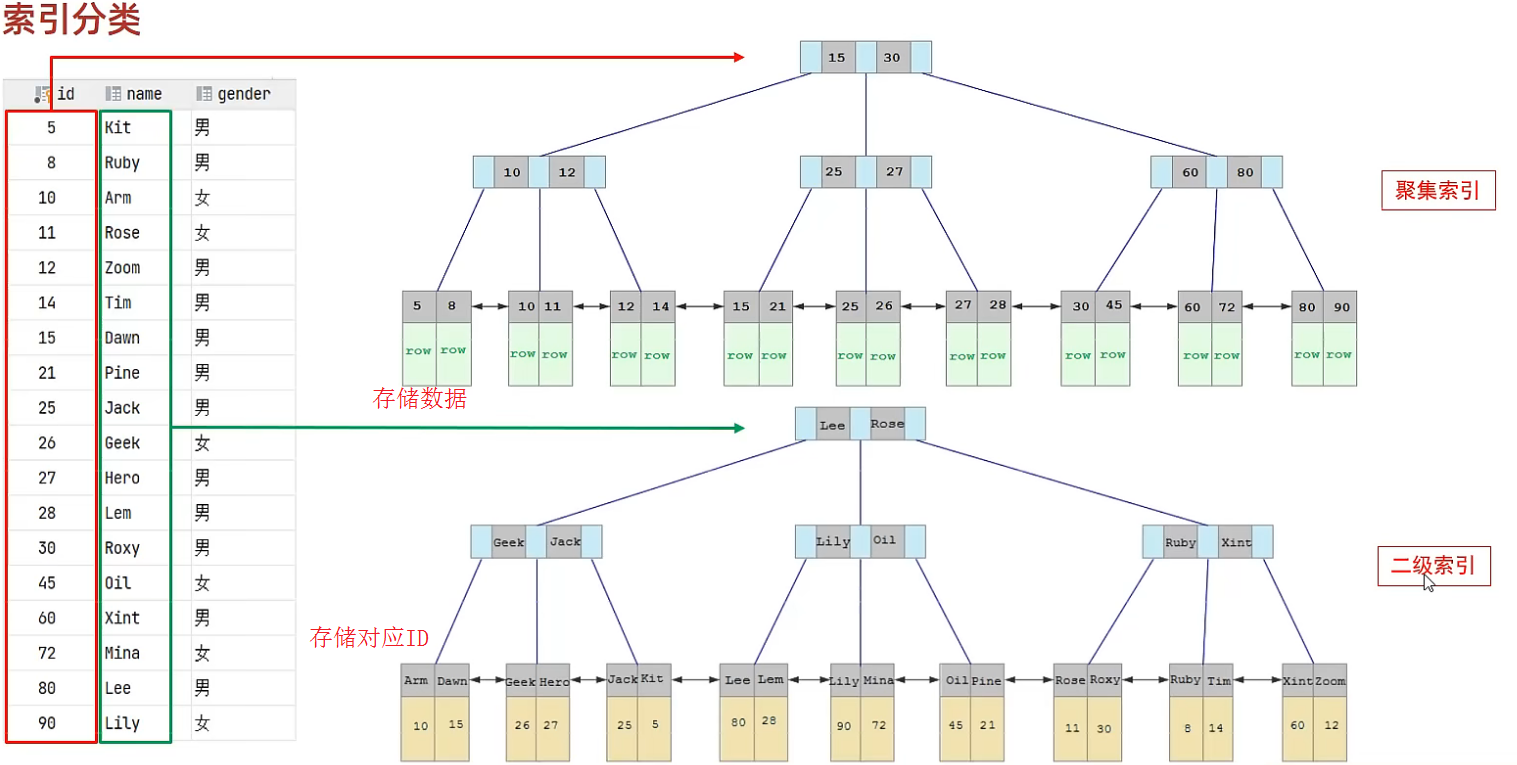
覆盖索引效率分析:①②③没懂可以看看前面聚集索引分类的图
① 如果在聚集索引中直接能找到对应的行,则直接返回行数据,只需要一次查询,哪怕是select *;如select * from tab where id=1;
② 如果在生成的二级索引(辅助索引)中可以一次性获得select所需要的字段,不需要回表查询。如select id, name from xxx where name='xxx';,也只需要通过辅助索引(name)查找到对应的id,返回name和name索引对应的id即可,只需要一次查询;
③ 如果是通过二级索引查找其他字段,则需要回表查询,如select id, name, gender from xxx where name='xxx';
所以尽量不要用select *,容易出现回表查询,降低效率,除非有联合索引包含了所有字段
例子:
第一条sql是直接聚集索引可以查到数据
第二条sql需要先二级索引查到id,然后再用id去聚集索引查到那行数据
面试题:一张表,有四个字段(id, username, password, status),由于数据量大,需要对以下SQL语句进行优化,该如何进行才是最优方案: select id, username, password from tb_user where username='itcast';
解:给username和password字段建立联合索引,则不需要回表查询,直接覆盖索引。
username和password字段建立联合索引的叶子节点挂的就是 id 所以不需要三者同时建索引。
语法:create index idx_xxxx on table_name(columnn(n));
例子:create index idx_user_phone_5 on table_name(phone(5));
前缀长度:可以根据索引的选择性来决定,而选择性是指不重复的索引值(基数)和数据表的记录总数的比值,索引选择性越高则查询效率越高,唯一索引的选择性是1,这是最好的索引选择性,性能也是最好的。
求选择性公式:
select count(distinct email) / count(*) from tb_user;
select count(distinct substring(email, 1, 5)) / count(*) from tb_user;
# 客户端连接服务端时,加上参数 --local-infile(这一行在bash/cmd界面输入)
mysql --local-infile -u root -p
# 设置全局参数local_infile为1(默认是0未开启),开启从本地加载文件导入数据的开关
set global local_infile = 1;
select @@local_infile; --查看local_infile这个参数的值是什么
# 建立一张表tb_user(这里省略如何建表)
#将本地文件数据导入数据库表。参数:本地文件地址、表名、数据之间用什么符号分割、数据每行之间用什么分割
load data local infile '/root/sql1.log' into table 'tb_user' fields terminated by ',' lines terminated by '\n';
Using filesort:通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区 sort buffer 中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫 FileSort 排序
Using index:通过有序索引顺序扫描直接返回有序数据,这种情况即为 using index,不需要额外排序,操作效率高
#没有创建索引时,根据age, phone进行排序
explain select id,age,phone from tb user order by age , phone;
#创建索引(没指定asc、desc时,默认都是顺序asc)
create index idx_user_age_phone_aa on tb_user(age,phone);
#创建索引后,根据age, phone进行升序排序(此时会用索引,用Using index)
explain select id,age,phone from tb user order by age,phone;
#创建索引后,根据age,phone进行降序排序(此时也会用索引,用Using index,因为数据库可以倒序索引)
explain select id,age,phone from tb user order by age desc , phone desc;
#根据age, phone进行降序一个升序,一个降序(此时不会用索引,还是用Using filesort,因为索引是两者顺序,这里是一顺一反)
explain select id,agephone from tb user order by age asc , phone desc;
#根据age, phone进行降序一个升序,一个降序(此时不会用索引,还是用Using filesort,因为索引是先age后phone,这里是反了)
explain select id,agephone from tb user order by phone asc , age asc;
#创建索引
create index idx user age phone ad on tb user(age asc ,phone desc);
#根据age, phone进行降序一个升序,一个降序(此时会用索引,用Using index,因为创建索引时是一顺一反)
explain select id,agephone from tb user order by age asc , phone desc;
创建索引时都是升序,如果order by字段全部使用升序排序或者降序排序,则都会走索引,但是如果一个字段升序排序,另一个字段降序排序,则不会走索引,explain的extra信息显示的是Using index, Using filesort,如果要优化掉Using filesort,则需要另外再创建一个索引,如:create index idx_user_age_phone_ad on tb_user(age asc, phone desc);,此时使用select id, age, phone from tb_user order by age asc, phone desc;会全部走索引
如索引为idx_user_pro_age_stat,则句式可以是select ... where profession order by age,这样也符合最左前缀法则
limit优化
常见的问题如limit 2000000, 10,此时需要 MySQL 排序前2000000条记录,但仅仅返回2000000 - 2000010的记录,其他记录丢弃,查询排序的代价非常大。
优化方案:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
例如:
-- 此语句耗时很长(19s)
select * from tb_sku limit 9000000, 10;
-- 通过覆盖索引加快速度,直接通过主键索引进行排序及查询
select id from tb_sku order by id limit 9000000, 10;
-- 下面的语句是错误的,因为 MySQL 不支持 in 里面使用 limit
-- select * from tb_sku where id in (select id from tb_sku order by id limit 9000000, 10);
-- 通过连表查询即可实现第一句的效果,并且能达到第二句的速度(11s)
select * from tb_sku as s, (select id from tb_sku order by id limit 9000000, 10) as a where s.id = a.id;
如以下两条语句: update student set no = '123' where id = 1;,这句由于id有主键索引,所以只会锁这一行; update student set no = '123' where name = 'test';,这句由于name没有索引,所以会把整张表都锁住进行数据更新,解决方法是给name字段添加索引,就可以由表锁变成行锁。
# 既可以做创建语句也可以做修改语句,因为已经存在该视图的话会直接覆盖掉
create or replace view v1 as select id,name from student where id<=20;
# 只能做修改语句
alter view v1 as select id,name from student where id<=20;
删除视图
DROP VIEW [IF EXISTS] 视图名称 [视图名称]
视图检查选项
当使用WITH CHECK QPTION子句创建/修改视图时,MySQL会通过视图检查正在更改的每个行,例如插入,更新,删除,以使其符合视图的定义。MySQL允许基于另一个视图创建视图,它还会检查依赖视图中的规则以保持一致性。为了确定检查的范围,mysql提供了两个选项:CASCADED 和 LOCAL ,默认值为 CASCADED。
# 比如下面的例子:创建stu_V_l 视图,id是小于等于 20的。
create or replace view stu_V_l as select id,name from student where id <=20;
# 再创建 stu_v_2 视图(由于加了级联检查,所以对2视图增删改的时候需要满足:id>=10,id<=20. 别忘了级联检查也会检查关联视图)
create or replace view stu_v_2 as select id,name from stu_v_1 where id >=10 with cascaded check option;
# 再创建 stu_v_3 视图。
create or replace view stu_v_3 as select id,name from stu_v_2 where id<=15;
# 可以插入。stu_v_3 没有开检查选项所以不会去判断 id 是否小于等于15,因为使用到了视图stu_v_2且其加了级联检查,所以需要判断stu_v_2与stu_v_1视图的条件是否满足,都满足可以插入。
insert into stu_v_3 values(17,'Tom');
# 可以插入。虽然不符合stu_v_3的条件,但stu_v_3没有级联检查,关联视图stu_v_2、stu_v_1才有级联检查,符合stu_v_2、stu_v_1的条件
insert into stu_v_3 values(11,'Tom');
# 不能插入。和上面同理,这里是不满足stu_v_1的条件
insert into stu_v_3 values(28,'Tom');
# 比如下面的例子:创建stu_V_l 视图,id是小于等于 20的。
create or replace view stu_V_l as select id,name from student where id <=20;
# 再创建 stu_v_2 视图(由于加了本地检查,所以对2视图增删改的时候需要满足:id>=10)
create or replace view stu_v_2 as select id,name from stu_v_1 where id >=10 with local check option;
# 再创建 stu_v_3 视图。
create or replace view stu_v_3 as select id,name from stu_v_2 where id<=15;
# 可以插入。stu_v_3 没有开检查选项所以不会去判断 id 是否小于等于15,因为使用到了视图stu_v_2且其加了本地检查,所以需要判断stu_v_2的条件是否满足,再去检查stu_v_1发现其未加检查,所以不判断stu_v_1的条件。
insert into stu_v_3 values(17,'Tom');
# 可以插入。虽然不符合stu_v_3的条件,但stu_v_3没有检查,关联视图stu_v_2才有级联检查,符合stu_v_2的条件。
insert into stu_v_3 values(11,'Tom');
# 可以插入。和上面同理
insert into stu_v_3 values(28,'Tom');
SELECT* FROM INFORMATION_SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA = 'xxx'
存储过程名称;--查询某个存储过程的定义
SHOW CREATE PROCEDURE
例子:
--查询db_name数据库中的所有的存储过程
select name from mysql.proc where db='db_name';
--例子:
select name from mysql.proc where db='demo_01';
--查询存储过程的状态信息
show procedure status;
--查询某个存储过程的定义
show create procedure pro_test1 \G;
delimiter $
create procedure pro_test5()
begin
declare height int(11) default 175;
declare description varchar(50);
if height > 180 then
set description='身材高挑';
elseif height >=170 and height <= 180 then
set description='标准身材';
else set description='一般身材';
end if;
select description;
end$
delimiter ;
delimiter $
create procedure pro_test6(in height int)
begin
declare description varchar(50) default '';
if height >= 180 then
set description='身材高挑';
elseif height >=170 and height < 180 then
set description='标准身材';
else set description='一般身材';
end if;
select concat('身高 ', height , '对应的身材类型为:',description);
end$
delimiter ;
OUT-输出
需求 :定义两个参数,传入身高和身材描述的值(传出参数)
delimiter $
create procedure pro_test7(in height int(11),out description varchar(50))
begin
if height >= 180 then
set description='身材高挑';
elseif height >= 170 and height < 180 then
set description='标准身材';
else set description='一般身材';
end if;
end$
delimiter ;
create procedure p5(inout score double)
begin
set score := score * 0.5;
end;
set @score = 198;
call p5(@score);
select @score;
case结构
语法结构 :
方式一 :
CASE case_value
WHEN when_value THEN statement_list
[WHEN when_value THEN statement_list] ...
[ELSE statement_list]
END CASE;
方式二 :
CASE
WHEN search_condition THEN statement_list
[WHEN search_condition THEN statement_list] ...
[ELSE statement_list]
END CASE;
需求:给定一个月份, 然后计算出所在的季度
delimiter $
create procedure pro_test8(month int)
begin
declare result varchar(50) default '';
case
when month >=1 and month <=3 then
set result ='第一季度';
when month >=4 and month <=6 then
set result ='第二季度';
when month >=7 and month <=9 then
set result ='第三季度';
when month >=10 and month <=12 then
set result ='第四季度';
end case;
select concat('您输入的月份是:',month,',对应的季节是:',result) content;
end$
delimiter ;
while循环
语法结构:
while search_condition do
statement_list
end while;
需求:计算从1加到n的值,传入参数是n
delimiter $
create procedure pro_test9(in n int)
begin
declare countvalue int(11) default 0;
while n > 0 do
set countvalue=countvalue+n;
set n=n-1;
end while;
select concat('从1加到n的和是:',countvalue);
end$
delimiter ;
REPEAT
statement_list
UNTIL search_condition
END REPEAT;
需求:计算从1到n的和
delimiter $
create procedure pro_test10(n int)
begin
declare total int default 0;
repeat
set total = total + n;
set n = n - 1;
until n=0
end repeat;
select total ;
end$
delimiter ;
用来从标注的流程构造中退出,通常和 BEGIN ... END 或者循环一起使用。下面是一个使用 LOOP 和 LEAVE 的简单例子 , 退出循环:
delimiter $
create procedure pro_test11(in n int)
begin
declare total int default 0;
ins:loop
if n<=0 then
leave ins;
end if;
set total = total+n;
set n = n-1;
end loop ins;
select total;
end $
delimiter ;
create procedure p1l(in uage int)
begin
declare uname varchar(100);
decLare upro varchar(100);
declare u_cursor cursor for select name,profession from tb_user where age <= uage;
当 条件处理程序的处理的状态码为02000的时候,就会退出。
declare exit handler for SQLSTATE '02000'close u_cursor;
drop table if exists tb_user_pro;
create table if not exists tb_user_pro(
id int primary key auto_increment,
name varchar(100),
profession varchar(100)
);
open u_cursor;
while true do
fetch u_cursor into uname,Upro;
insert into tb_user_pro values(null,uname,Upro);
end while;
close u_cursor;
end;
示例 :
初始化脚本:
create table emp(
id int(11) not null auto_increment ,
name varchar(50) not null comment '姓名',
age int(11) comment '年龄',
salary int(11) comment '薪水',
primary key(`id`)
)engine=innodb default charset=utf8 ;
insert into emp(id,name,age,salary) values(null,'金毛狮王',55,3800),(null,'白眉鹰王',60,4000),(null,'青翼蝠王',38,2800),(null,'紫衫龙王',42,1800);
mysql> call pro_test12();
+---------------------------------------------------------------------------------+
| concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为:',e_salary) |
+---------------------------------------------------------------------------------+
| id=5, name=金毛狮王, age=55, 薪资为:3800 |
+---------------------------------------------------------------------------------+
1 row in set (0.00 sec)
+---------------------------------------------------------------------------------+
| concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为:',e_salary) |
+---------------------------------------------------------------------------------+
| id=6, name=白眉鹰王, age=60, 薪资为:4000 |
+---------------------------------------------------------------------------------+
1 row in set (0.00 sec)
+---------------------------------------------------------------------------------+
| concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为:',e_salary) |
+---------------------------------------------------------------------------------+
| id=7, name=青翼蝠王, age=38, 薪资为:2800 |
+---------------------------------------------------------------------------------+
1 row in set (0.00 sec)
+---------------------------------------------------------------------------------+
| concat('id=',e_id , ', name=',e_name, ', age=', e_age, ', 薪资为:',e_salary) |
+---------------------------------------------------------------------------------+
| id=8, name=紫衫龙王, age=42, 薪资为:1800 |
+---------------------------------------------------------------------------------+
1 row in set (0.00 sec)
ERROR 1329 (02000): No data - zero rows fetched, selected, or processed
可以看到最后的时候报了一个错误:ERROR 1329 (02000): No data - zero rows fetched, selected, or processed,这是因为游标中已经没有数据了,而我们还在fetch,所以就报错了。我们要防止这个错误,就要使用循环来从游标中获取数据,如下操作:
delimiter $
create procedure pro_test13()
begin
declare e_id int(11);
declare e_name varchar(50);
declare e_age int(11);
declare e_salary int(11);
declare has_data int default 1;
declare emp_result cursor for select * from emp;
declare exit handler for not found set has_data=0;
open emp_result;
repeat
fetch emp_result into e_id,e_name,e_age,e_salary;
select concat('id=',e_id,',name=',e_name,',age=',e_age,',薪资:',e_salary);
until has_data=0
end repeat;
close emp_result;
end$
delimiter ;
注意:切记一点,until语句后面是没有分号结尾的
调用效果:
mysql> call pro_test13()$
+----------------------------------------------------------------------------+
| concat('id=',e_id,',name=',e_name,',age=',e_age,',薪资:',e_salary) |
+----------------------------------------------------------------------------+
| id=5,name=金毛狮王,age=55,薪资:3800 |
+----------------------------------------------------------------------------+
1 row in set (0.00 sec)
+----------------------------------------------------------------------------+
| concat('id=',e_id,',name=',e_name,',age=',e_age,',薪资:',e_salary) |
+----------------------------------------------------------------------------+
| id=6,name=白眉鹰王,age=60,薪资:4000 |
+----------------------------------------------------------------------------+
1 row in set (0.00 sec)
+----------------------------------------------------------------------------+
| concat('id=',e_id,',name=',e_name,',age=',e_age,',薪资:',e_salary) |
+----------------------------------------------------------------------------+
| id=7,name=青翼蝠王,age=38,薪资:2800 |
+----------------------------------------------------------------------------+
1 row in set (0.00 sec)
+----------------------------------------------------------------------------+
| concat('id=',e_id,',name=',e_name,',age=',e_age,',薪资:',e_salary) |
+----------------------------------------------------------------------------+
| id=8,name=紫衫龙王,age=42,薪资:1800 |
+----------------------------------------------------------------------------+
1 row in set (0.00 sec)
Query OK, 0 rows affected (0.00 sec)
CREATE FUNCTION function_name([param type ... ])
RETURNS type
BEGIN
...
END;
案例 :定义一个存储函数, 请求满足条件的总记录数 ;
delimiter $
create function fun_count_city(countryId int)
returns int
begin
declare cnum int(11);
select count(1) into cnum from city where country_id=countryId;
return cnum;
end$
delimiter ;
调用:
mysql> select fun_count_city(1);
+-------------------+
| fun_count_city(1) |
+-------------------+
| 3 |
+-------------------+
1 row in set (0.00 sec)
使用别名 OLD 和 NEW 来引用触发器中发生变化的记录内容,这与其他的数据库是相似的。现在Mysql触发器还只支持行级触发,不支持语句级触发(Oracle支持语句级触发)。
触发器类型
NEW 和 OLD的使用
INSERT 型触发器
NEW 表示将要或者已经新增的数据
UPDATE 型触发器
OLD 表示修改之前的数据 , NEW 表示将要或已经修改后的数据
DELETE 型触发器
OLD 表示将要或者已经删除的数据
创建触发器
语法结构 :
create trigger trigger_name
before/after insert/update/delete
on tbl_name
[ for each row ] -- 行级触发器
begin
trigger_stmt ;
end;
需求:通过触发器记录 emp 表的数据变更日志 , 包含增加, 修改 , 删除 ;
首先创建一张日志表 :
create table emp_logs(
id int(11) not null auto_increment,
operation varchar(20) not null comment '操作类型, insert/update/delete',
operate_time datetime not null comment '操作时间',
operate_id int(11) not null comment '操作表的ID',
operate_params varchar(500) comment '操作参数',
primary key(`id`)
)engine=innodb default charset=utf8;
创建 insert 型触发器,完成插入数据时的日志记录 :
delimiter $
create trigger emp_logs_insert_trigger
after insert
on emp
for each row
begin
insert into emp_logs values(null,'insert',now(),new.id,concat('插入的数据是:id=',new.id,',name=',new.name,',age=',new.age,',薪资是:',new.salary));
end$
delimiter ;
insert into emp values(null,'光明左使',23,9000);
--查询emp_logs表
select * from emp_logs;
效果如下:
mysql> insert into emp values(null,'光明左使',23,9000);
Query OK, 1 row affected (0.01 sec)
mysql> select * from emp_logs;
+----+-----------+---------------------+------------+---------------------------------------------------------------------------+
| id | operation | operate_time | operate_id | operate_params |
+----+-----------+---------------------+------------+---------------------------------------------------------------------------+
| 1 | insert | 2019-07-06 08:29:20 | 9 | 插入的数据是:id=9,name=光明左使,age=23,薪资是:9000 |
+----+-----------+---------------------+------------+---------------------------------------------------------------------------+
1 row in set (0.00 sec)
创建 update 型触发器,完成更新数据时的日志记录
delimiter $
create trigger emp_logs_update_trigger
after update
on emp
for each row
begin
insert into emp_logs values(null,'update',now(),new.id,concat('修改之前的数据是:id=',old.id,',name=',old.name,',age=',old.age,',薪资是:',old.salary,'修改完成后的数据是:id=',new.id,',name=',new.name,',age=',new.age,',薪资是:',new.salary));
end$
delimiter ;
delimiter $
create trigger emp_logs_delete_trigger
after delete
on emp
for each row
begin
insert into emp_logs values(null,'delete',now(),old.id,concat('删除的数据是:id=',old.id,',name是:',old.name,',年龄是:',old.age,',薪资是:',old.salary));
end$
delimiter ;