Redis 技术整理
认识Redis
Redis官网:https://redis.io/
Redis诞生于2009年全称是Remote Dictionary Server 远程词典服务器,是一个基于内存的键值型NoSQL数据库
特征:
- 键值(key-value)型,value支持多种不同数据结构,功能丰富
- 单线程,每个命令具备原子性
- 低延迟,速度快(基于内存.IO多路复用.良好的编码)
- 支持数据持久化
- 支持主从集群、分片集群
NoSQL可以翻译做Not Only SQL(不仅仅是SQL),或者是No SQL(非SQL的)数据库。是相对于传统关系型数据库而言,有很大差异的一种特殊的数据库,因此也称之为非关系型数据库
关系型数据是结构化的,即有严格要求,而NoSQL则对数据库格式没有严格约束,往往形式松散,自由
可以是键值型:

也可以是文档型:

甚至可以是图格式:
在事务方面:
- 传统关系型数据库能满足事务ACID的原则
- 非关系型数据库往往不支持事务,或者不能严格保证ACID的特性,只能实现基本的一致性
除了上面说的,在存储方式.扩展性.查询性能上关系型与非关系型也都有着显著差异,总结如下:

- 存储方式
- 关系型数据库基于磁盘进行存储,会有大量的磁盘IO,对性能有一定影响
- 非关系型数据库,他们的操作更多的是依赖于内存来操作,内存的读写速度会非常快,性能自然会好一些
- 扩展性
- 关系型数据库集群模式一般是主从,主从数据一致,起到数据备份的作用,称为垂直扩展。
- 非关系型数据库可以将数据拆分,存储在不同机器上,可以保存海量数据,解决内存大小有限的问题。称为水平扩展。
- 关系型数据库因为表之间存在关联关系,如果做水平扩展会给数据查询带来很多麻烦
安装Redis
企业都是基于Linux服务器来部署项目,而且Redis官方也没有提供Windows版本的安装包
本文选择的Linux版本为CentOS 7
单机安装
- 安装需要的依赖
yum install -y gcc tcl
- 上传压缩包并解压
tar -zxf redis-7.0.12.tar.gz
- 进入解压的redis目录
cd redis-7.0.12
- 编译并安装
make && make install
默认的安装路径是在 /usr/local/bin目录下
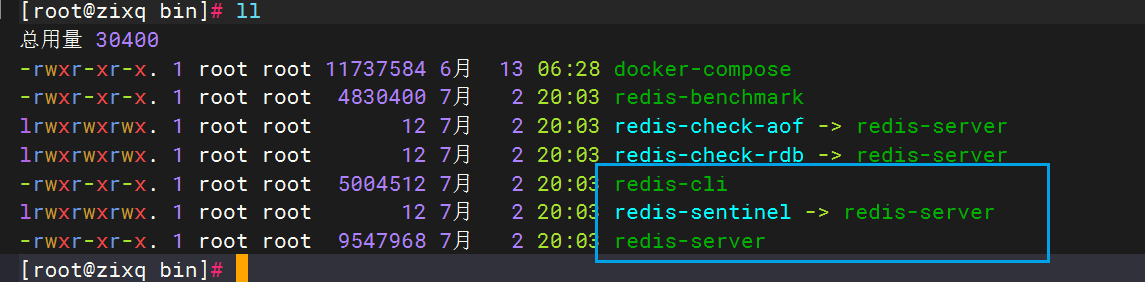
该目录已经默认配置到环境变量,因此可以在任意目录下运行这些命令。其中:
- redis-cli:是redis提供的命令行客户端
- redis-server:是redis的服务端启动脚本
- redis-sentinel:是redis的哨兵启动脚本
启动Redis
redis的启动方式有很多种,例如:
- 默认启动
- 指定配置启动
- 开机自启
默认启动
安装完成后,在任意目录输入redis-server命令即可启动Redis:
redis-server
这种启动属于“前台启动”,会阻塞整个会话窗口,窗口关闭或者按下CTRL + C则Redis停止
指定配置启动
如果要让Redis以“后台”方式启动,则必须修改Redis配置文件,就在之前解压的redis安装包下(/usr/local/src/redis-6.2.6),名字叫redis.conf
修改redis.conf文件中的一些配置:可以先拷贝一份再修改
# 允许访问的地址,默认是127.0.0.1,会导致只能在本地访问。修改为0.0.0.0则可以在任意IP访问,生产环境不要设置为0.0.0.0
bind 0.0.0.0
# 守护进程,修改为yes后即可后台运行
daemonize yes
# 密码,设置后访问Redis必须输入密码
requirepass 072413
Redis的其它常见配置:
# 监听的端口
port 6379
# 工作目录,默认是当前目录,也就是运行redis-server时的命令,日志、持久化等文件会保存在这个目录
dir .
# 数据库数量,设置为1,代表只使用1个库,默认有16个库,编号0~15
databases 1
# 设置redis能够使用的最大内存
maxmemory 512mb
# 日志文件,默认为空,不记录日志,可以指定日志文件名
logfile "redis.log"
启动Redis:
# 进入redis安装目录
cd /opt/redis-6.2.13
# 启动
redis-server redis.conf
停止服务:
# 利用redis-cli来执行 shutdown 命令,即可停止 Redis 服务,
# 因为之前配置了密码,因此需要通过 -u 来指定密码
redis-cli -u password shutdown
开机自启
可以通过配置来实现开机自启。
首先,新建一个系统服务文件:
vim /etc/systemd/system/redis.service
内容如下:
[Unit]
Description=redis-server
After=network.target
[Service]
Type=forking
ExecStart=/usr/local/bin/redis-server /opt/redis-7.0.12/redis.conf
PrivateTmp=true
[Install]
WantedBy=multi-user.target
然后重载系统服务:
systemctl daemon-reload
现在,我们可以用下面这组命令来操作redis了:
# 启动
systemctl start redis
# 停止
systemctl stop redis
# 重启
systemctl restart redis
# 查看状态
systemctl status redis
执行下面的命令,可以让redis开机自启:
systemctl enable redis
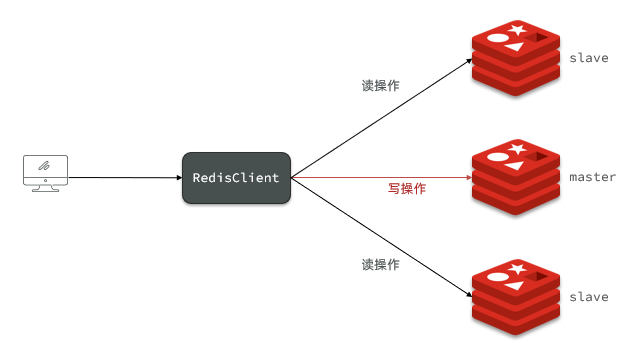
主从集群安装
主:具有读写操作
从:只有读操作
- 修改redis.conf文件
# 开启RDB
# save ""
save 3600 1
save 300 100
save 60 10000
# 关闭AOF
appendonly no
- 将上面的redis.conf文件拷贝到不同地方
# 方式一:逐个拷贝
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7001
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7002
cp /usr/local/bin/redis-7.0.12/redis.conf /tmp/redis-7003
# 方式二:管道组合命令,一键拷贝
echo redis-7001 redis-7002 redis-7003 | xargs -t -n 1 cp /usr/local/bin/redis-7.0.12/redis.conf
- 修改各自的端口、rdb目录改为自己的目录
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/redis-7001\//g' redis-7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/redis-7002\//g' redis-7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/redis-7003\//g' redis-7003/redis.conf
- 修改每个redis节点的IP声明。虚拟机本身有多个IP,为了避免将来混乱,需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
# redis实例的声明 IP
replica-announce-ip IP地址
# 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' redis-7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis-7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' redis-7003/redis.conf
# 或者一键修改
printf '%s\n' redis-7001 redis-7002 redis-7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf
- 启动
# 第1个
redis-server redis-7001/redis.conf
# 第2个
redis-server redis-7002/redis.conf
# 第3个
redis-server redis-7003/redis.conf
# 一键停止
printf '%s\n' redis-7001 redis-7002 redis-7003 | xargs -I{} -t redis-cli -p {} shutdown
- 开启主从关系:配置主从可以使用replicaof 或者slaveof(5.0以前)命令
永久配置:在redis.conf中添加一行配置
slaveof <masterip> <masterport>
临时配置:使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效)
# 5.0以后新增命令replicaof,与salveof效果一致
slaveof <masterip> <masterport>
卸载Redis
- 查看redis是否启动
ps aux | grep redis
- 若启动,则杀死进程
kill -9 PID

- 停止服务
redis-cli shutdown
- 查看
/usr/local/lib目录中是否有与Redis相关的文件
ll /usr/local/bin/redis-*
# 有的话就删掉
rm -rf /usr/local/bin/redis-*
Redis客户端工具
命令行客户端
Redis安装完成后就自带了命令行客户端:redis-cli,使用方式如下:
redis-cli [options] [commonds]
其中常见的options有:
-h 127.0.0.1:指定要连接的redis节点的IP地址,默认是127.0.0.1-p 6379:指定要连接的redis节点的端口,默认是6379-a 072413:指定redis的访问密码
其中的commonds就是Redis的操作命令,例如:
ping:与redis服务端做心跳测试,服务端正常会返回pong
不指定commond时,会进入redis-cli的交互控制台:

图形化客户端
地址:https://github.com/uglide/RedisDesktopManager
不过该仓库提供的是RedisDesktopManager的源码,并未提供windows安装包。
在下面这个仓库可以找到安装包:https://github.com/lework/RedisDesktopManager-Windows/releases
下载之后,解压、安装

Redis默认有16个仓库,编号从0至15. 通过配置文件可以设置仓库数量,但是不超过16,并且不能自定义仓库名称。
如果是基于redis-cli连接Redis服务,可以通过select命令来选择数据库
# 选择 0号库
select 0
Redis常见命令 / 对象
Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样:

查命令的官网: https://redis.io/commands
在交互界面使用 help 命令查询:
help [command]
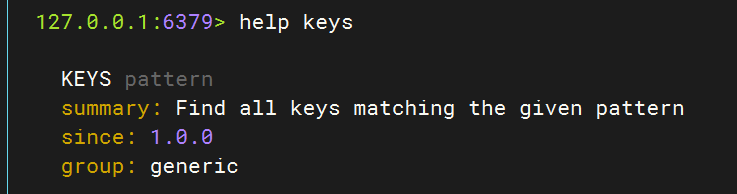
通用命令
通用指令是部分数据类型都可以使用的指令,常见的有:
- KEYS:查看符合模板的所有key。在生产环境下,不推荐使用keys 命令,因为这个命令在key过多的情况下,效率不高
- DEL:删除一个指定的key
- EXISTS:判断key是否存在
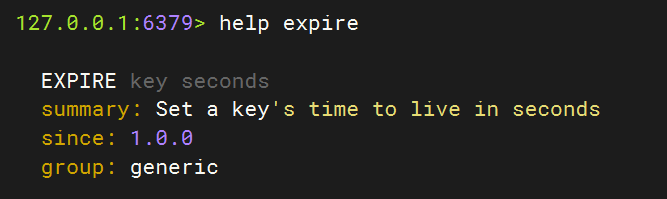
- EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除。内存非常宝贵,对于一些数据,我们应当给他一些过期时间,当过期时间到了之后,他就会自动被删除
- 当使用EXPIRE给key设置的有效期过期了,那么此时查询出来的TTL结果就是-2
- 如果没有设置过期时间,那么TTL返回值就是-1
- TTL:查看一个KEY的剩余有效期
String命令
使用场景:
- 验证码保存
- 不易变动的对象保存
- 简单锁的保存
String类型,也就是字符串类型,是Redis中最简单的存储类型
其value是字符串,不过根据字符串的格式不同,又可以分为3类:
- string:普通字符串
- int:整数类型,可以做自增.自减操作
- float:浮点类型,可以做自增.自减操作
String的常见命令有:
-
SET:添加或者修改已经存在的一个String类型的键值对,对于SET,若key不存在则为添加,存在则为修改
-
GET:根据key获取String类型的value
-
MSET:批量添加多个String类型的键值对
-
MGET:根据多个key获取多个String类型的value
-
INCR:让一个整型的key自增1
-
INCRBY:让一个整型的key自增并指定步长
- incrby num 2 让num值自增2
- 也可以使用负数,是为减法,如:incrby num -2 让num值-2。此种类似 DECR 命令,而DECR是每次-1
-
INCRBYFLOAT:让一个浮点类型的数字自增并指定步长
-
SETNX:添加一个String类型的键值对(key不存在为添加,存在则不执行)
-
SETEX:添加一个String类型的键值对,并且指定有效期
注:以上命令除了INCRBYFLOAT 都是常用命令
key问题
key的设计
Redis没有类似MySQL中的Table的概念,我们该如何区分不同类型的key?
可以通过给key添加前缀加以区分,不过这个前缀不是随便加的,有一定的规范
Redis的key允许有多个单词形成层级结构,多个单词之间用:隔开,格式如下:

这个格式并非固定,也可以根据自己的需求来删除或添加词条
如项目名称叫 automation,有user和product两种不同类型的数据,我们可以这样定义key:
-
user相关的key:automation:user:1
-
product相关的key:automation:product:1
同时还需要满足:
- key的长度最好别超过44字节(3.0版本是39字节)
- key中别包含特殊字符
BigKey问题
BigKey通常“以Key的大小和Key中成员的数量来综合判定”,例如:
- Key本身的数据量过大:一个String类型的Key,它的值为5 MB
- Key中的成员数过多:一个ZSET类型的Key,它的成员数量为10,000个
- Key中成员的数据量过大:一个Hash类型的Key,它的成员数量虽然只有1,000个但这些成员的Value(值)总大小为100 MB
判定元素大小的方式:
MEMORY USAGE key # 查看某个key的内存大小,不建议使用:因为此命令对CPU使用率较高
# 衡量值 或 值的个数
STRLEN key # string结构 某key的长度
LLEN key # list集合 某key的值的个数
.............
推荐值:
- 单个key的value小于10KB
- 对于集合类型的key,建议元素数量小于1000
BigKey的危害
- 网络阻塞:对BigKey执行读请求时,少量的QPS就可能导致带宽使用率被占满,导致Redis实例,乃至所在物理机变慢
- 数据倾斜:BigKey所在的Redis实例内存使用率远超其他实例,无法使数据分片的内存资源达到均衡
- Redis阻塞:对元素较多的hash、list、zset等做运算会耗时较旧,使主线程被阻塞
- CPU压力:对BigKey的数据序列化和反序列化会导致CPU的使用率飙升,影响Redis实例和本机其它应用
如何发现BigKey
- redis-cli --bigkeys 命令:
redis-cli -a 密码 --bigkeys
此命令可以遍历分析所有key,并返回Key的整体统计信息与每个数据的Top1的key
不足:返回的是内存大小是TOP1的key,而此key不一定是BigKey,同时TOP2、3.......的key也不一定就不是BigKey
- scan命令扫描:]每次会返回2个元素,第一个是下一次迭代的光标(cursor),第一次光标会设置为0,当最后一次scan 返回的光标等于0时,表示整个scan遍历结束了,第二个返回的是List,一个匹配的key的数组
127.0.0.1:7001> help SCAN
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
summary: Incrementally iterate the keys space
since: 2.8.0
group: generic
自定义代码来判定是否为BigKey
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.ScanResult;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class JedisTest {
private final static int STR_MAX_LEN = 10 * 1024;
private final static int HASH_MAX_LEN = 500;
private Jedis jedis;
@BeforeEach
void setUp() {
// 1.建立连接
jedis = new Jedis("192.168.146.100", 6379);
// 2.设置密码
jedis.auth("072413");
// 3.选择库
jedis.select(0);
}
@Test
void testScan() {
int maxLen = 0;
long len = 0;
String cursor = "0";
do {
// 扫描并获取一部分key
ScanResult<String> result = jedis.scan(cursor);
// 记录cursor
cursor = result.getCursor();
List<String> list = result.getResult();
if (list == null || list.isEmpty()) {
break;
}
// 遍历
for (String key : list) {
// 判断key的类型
String type = jedis.type(key);
switch (type) {
case "string":
len = jedis.strlen(key);
maxLen = STR_MAX_LEN;
break;
case "hash":
len = jedis.hlen(key);
maxLen = HASH_MAX_LEN;
break;
case "list":
len = jedis.llen(key);
maxLen = HASH_MAX_LEN;
break;
case "set":
len = jedis.scard(key);
maxLen = HASH_MAX_LEN;
break;
case "zset":
len = jedis.zcard(key);
maxLen = HASH_MAX_LEN;
break;
default:
break;
}
if (len >= maxLen) {
System.out.printf("Found big key : %s, type: %s, length or size: %d %n", key, type, len);
}
}
} while (!cursor.equals("0"));
}
@AfterEach
void tearDown() {
if (jedis != null) {
jedis.close();
}
}
}
- 第三方工具
- 利用第三方工具,如 Redis-Rdb-Tools 分析RDB快照文件,全面分析内存使用情况
- 网络监控
- 自定义工具,监控进出Redis的网络数据,超出预警值时主动告警
- 一般阿里云搭建的云服务器就有相关监控页面
如何删除BigKey
BigKey内存占用较多,即便是删除这样的key也需要耗费很长时间,导致Redis主线程阻塞,引发一系列问题
- redis 3.0 及以下版本:如果是集合类型,则遍历BigKey的元素,先逐个删除子元素,最后删除BigKey

- Redis 4.0以后:使用异步删除的命令 unlink
127.0.0.1:7001> help UNLINK
UNLINK key [key ...]
summary: Delete a key asynchronously in another thread. Otherwise it is just as DEL, but non blocking.
since: 4.0.0
group: generic
解决BigKey问题
上一节是删除BigKey,但是数据最终还是未解决
要解决BigKey:
- 选择合适的数据结构(String、Hash、List、Set、ZSet、Stream、GEO、HyperLogLog、BitMap)
- 将大数据拆为小数据,具体根据业务来
如:一个对象放在hash中,hash底层会使用ZipList压缩,但entry数量超过500时(看具体redis版本),会使用哈希表而不是ZipList
# 查看redis的entry数量
[root@zixq ~]# redis-cli
127.0.0.1:7001> config get hash-max-ziplist-entries
# 修改redis的entry数量 别太离谱即可
config set hash-max-ziplist-entries
因此:一个hash的key中若是field-value约束在一定的entry以内即可,超出的就用另一个hash的key来存储,具体实现以业务来做
Hash命令
使用场景:
- 易改变对象的保存
- 分布式锁的保存(Redisson分布式锁的实现原理)
这个在工作中使用频率很高
Hash类型,也叫散列,其value是一个无序字典,类似于Java中的HashMap结构。
String结构是将对象序列化为JSON字符串后存储,当需要修改对象某个字段时很不方便:

Hash结构可以将对象中的每个字段独立存储,可以针对单个字段做CRUD:

Hash类型的常见命令
-
HSET key field value:添加或者修改hash类型key的field的值。同理:操作不存在数据是为新增,存在则为修改
-
HGET key field:获取一个hash类型key的field的值
-
HMSET:批量添加多个hash类型key的field的值
-
HMGET:批量获取多个hash类型key的field的值
-
HGETALL:获取一个hash类型的key中的所有的field和value
-
HKEYS:获取一个hash类型的key中的所有的field
-
HINCRBY:让一个hash类型key的field的value值自增并指定步长
-
HSETNX:添加一个hash类型的key的field值,前提是这个field不存在,否则不执行
List命令 - 命令规律开始变化
Redis中的List类型与Java中的LinkedList类似,可以看做是一个双向链表结构。既可以支持正向检索,也可以支持反向检索。
特征也与LinkedList类似:
- 有序
- 元素可以重复
- 插入和删除快
- 查询速度一般
使用场景:
- 朋友圈点赞列表
- 评论列表
List的常见命令有:
- LPUSH key element ... :向列表左侧插入一个或多个元素
- LPOP key:移除并返回列表左侧的第一个元素,没有则返回nil
- RPUSH key element ... :向列表右侧插入一个或多个元素
- RPOP key:移除并返回列表右侧的第一个元素
- LRANGE key star end:返回一段角标范围内的所有元素
- BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil

Set命令
Redis的Set结构与Java中的HashSet类似,可以看做是一个value为null的HashMap。因为也是一个hash表,因此具备与HashSet类似的特征:
- 无序
- 元素不可重复
- 查找快
- 支持交集.并集.差集等功能
使用场景:
- 一人一次的业务。如:某商品一个用户只能买一次
- 共同拥有的业务,如:关注、取关与共同关注
Set类型的常见命令
- SADD key member ... :向set中添加一个或多个元素
- SREM key member ... :移除set中的指定元素
- SCARD key:返回set中元素的个数
- SISMEMBER key member:判断一个元素是否存在于set中
- SMEMBERS:获取set中的所有元素
- SINTER key1 key2 ... :求key1与key2的交集
- SDIFF key1 key2 ... :求key1与key2的差集
- SUNION key1 key2 ..:求key1和key2的并集
SortedSet / ZSet 命令
Redis的SortedSet是一个可排序的set集合,与Java中的TreeSet有些类似,但底层数据结构却差别很大。SortedSet中的每一个元素都带有一个score属性,可以基于score属性对元素排序,底层的实现是一个跳表(SkipList)加 hash表。
SortedSet具备下列特性:
- 可排序
- 元素不重复
- 查询速度快
使用场景:
- 排行榜
SortedSet的常见命令有:
- ZADD key score member:添加一个或多个元素到sorted set ,如果已经存在则更新其score值
- ZREM key member:删除sorted set中的一个指定元素
- ZSCORE key member : 获取sorted set中的指定元素的score值
- ZRANK key member:获取sorted set 中的指定元素的排名
- ZCARD key:获取sorted set中的元素个数
- ZCOUNT key min max:统计score值在给定范围内的所有元素的个数
- ZINCRBY key increment member:让sorted set中的指定元素自增,步长为指定的increment值
- ZRANGE key min max:按照score排序后,获取指定排名范围内的元素
- ZRANGEBYSCORE key min max:按照score排序后,获取指定score范围内的元素
- ZDIFF.ZINTER.ZUNION:求差集.交集.并集
注意:所有的排名默认都是升序,如果要降序则在命令的Z后面添加REV即可,例如:
- 升序获取sorted set 中的指定元素的排名:ZRANK key member
- 降序获取sorted set 中的指定元素的排名:ZREVRANK key memeber
Stream命令
基于Stream的消息队列-消费者组
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。具备下列特点:

- 创建消费者组
XGROUP CREATE key groupName ID [MKSTREAM]
- key:队列名称
- groupName:消费者组名称
- ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
- MKSTREAM:队列不存在时自动创建队列
- 删除指定的消费者组
XGROUP DESTORY key groupName
- 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
- 删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername
- 从消费者组读取消息
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
-
group:消费组名称
-
consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
-
count:本次查询的最大数量
-
BLOCK milliseconds:当没有消息时最长等待时间
-
NOACK:无需手动ACK,获取到消息后自动确认
-
STREAMS key:指定队列名称
-
ID:获取消息的起始ID:
- ">":从下一个未消费的消息开始
- 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始
STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
消费者监听消息的基本思路:

GEO命令
GEO就是Geolocation的简写形式,代表地理坐标。Redis在3.2版本中加入了对GEO的支持,允许存储地理坐标信息,帮助我们根据经纬度来检索数据
常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEORADIUS:指定圆心、半径,找到该圆内包含的所有member,并按照与圆心之间的距离排序后返回。6.以后已废弃
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。6.2.新功能
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。 6.2.新功能
BitMap命令
bit:指的就是bite,二进制,里面的内容就是非0即1咯
map:就是说将适合使用0或1的业务进行关联。如:1为签到、0为未签到,这样就直接使用某bite就可表示出一个用户一个月的签到情况,减少内存花销了
BitMap底层是基于String实现的,因此:在Java中BitMap相关的操作封装到了redis的String操作中
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
HyperLogLog 命令
UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次
PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值
相关算法原理大家可以参考:https://juejin.cn/post/6844903785744056333#heading-0
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb。作为代价,其测量结果是概率性的,有小于0.81%的误差,同时此结构自带去重
常用命令如下:目前也只有这些命令
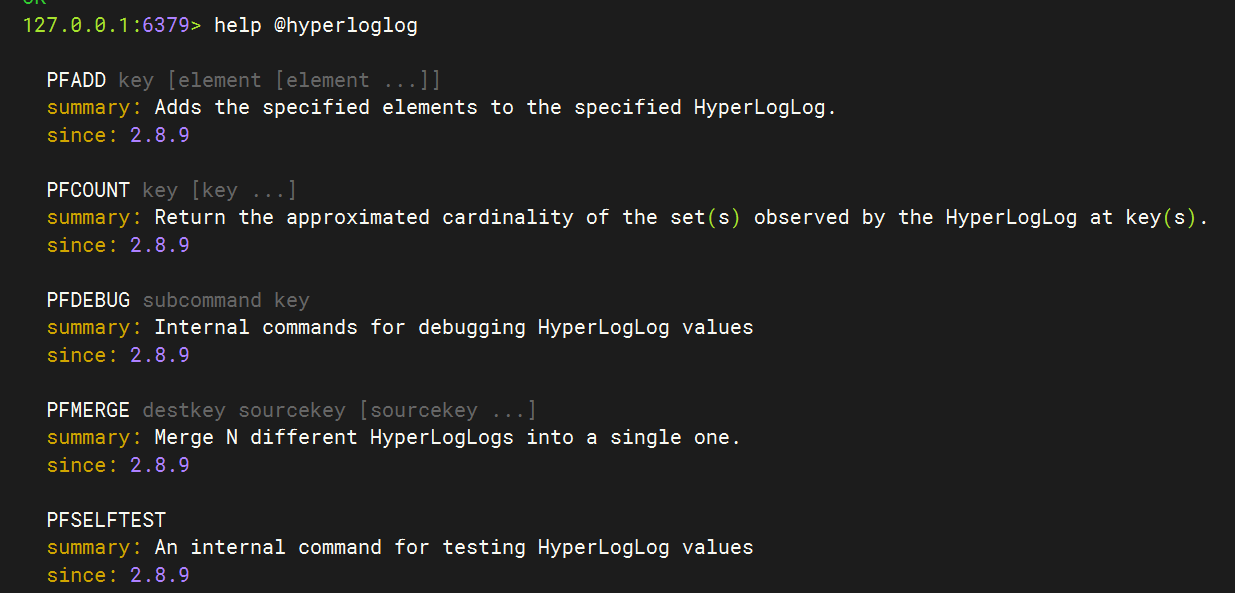
PubSub 发布订阅
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息
- SUBSCRIBE channel [channel] :订阅一个或多个频道
- PUBLISH channel msg :向一个频道发送消息
- PSUBSCRIBE pattern[pattern] :订阅与pattern格式匹配的所有频道。pattern支持的通配符如下:
? 表示 一个 字符 如:h?llo 则可以为 hallo、hxllo
* 表示 0个或N个 字符 如:h*llo 则可以为 hllo、heeeello.........
[ae] 表示 是a或e都行 如:h[ae]llo 则可以为 hello、hallo
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
Java操作:Jedis
官网:https://redis.io/docs/clients/
其中Java客户端也包含很多:

标记为❤的就是推荐使用的Java客户端,包括:
- Jedis和Lettuce:这两个主要是提供了“Redis命令对应的API”,方便我们操作Redis,而SpringDataRedis又对这两种做了抽象和封装
- Redisson:是在Redis基础上实现了分布式的可伸缩的Java数据结构,例如Map.Queue等,而且支持跨进程的同步机制:Lock.Semaphore等待,比较适合用来实现特殊的功能需求
入门Jedis
创建Maven项目
- 依赖
<!--jedis-->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>3.7.0</version>
</dependency>
- 测试:其他类型如Hash、Set、List、SortedSet和下面String是一样的用法
package com.zixieqing.redis;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import redis.clients.jedis.Jedis;
/**
* jedis操作redis:redis的命令就是jedis对应的API
*
* @author : ZiXieqing
*/
public class QuickStartTest {
private Jedis jedis;
@Before
public void setUp() throws Exception {
jedis = new Jedis("host", 6379);
// 设置密码
jedis.auth("072413");
// 设置库
jedis.select(0);
}
@After
public void tearDown() throws Exception {
if (null != jedis) jedis.close();
}
/**
* String类型
*/
@Test
public void stringTest() {
// 添加key-value
String result = jedis.set("name", "zixieqing");
System.out.println("result = " + result);
// 通过key获取value
String value = jedis.get("name");
System.out.println("value = " + value);
// 批量添加或修改
String mset = jedis.mset("age", "18", "sex", "girl");
System.out.println("mset = " + mset);
System.out.println("jedis.keys() = " + jedis.keys("*"));
// 给key自增并指定步长
long incrBy = jedis.incrBy("age", 5L);
System.out.println("incrBy = " + incrBy);
// 若key不存在,则添加,存在则不执行
long setnx = jedis.setnx("city", "hangzhou");
System.out.println("setnx = " + setnx);
// 添加key-value,并指定有效期
String setex = jedis.setex("job", 10L, "Java");
System.out.println("setex = " + setex);
// 获取key的有效期
long ttl = jedis.ttl("job");
System.out.println("ttl = " + ttl);
}
}
连接池
Jedis本身是线程不安全的,并且频繁的创建和销毁连接会有性能损耗,推荐使用Jedis连接池代替Jedis的直连方式
package com.zixieqing.redis.util;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
import java.time.Duration;
/**
* Jedis连接池
*
* @author : ZiXieqing
*/
public class JedisConnectionFactory {
private static JedisPool jedisPool;
static {
// 设置连接池
JedisPoolConfig PoolConfig = new JedisPoolConfig();
PoolConfig.setMaxTotal(30);
PoolConfig.setMaxIdle(30);
PoolConfig.setMinIdle(0);
PoolConfig.setMaxWait(Duration.ofSeconds(1));
/*
设置链接对象
JedisPool(GenericObjectPoolConfig<Jedis> poolConfig, String host, int port, int timeout, String password)
*/
jedisPool = new JedisPool(PoolConfig, "192.168.46.128", 6379, 1000, "072413");
}
public static Jedis getJedis() {
return jedisPool.getResource();
}
}
Java操作:SpringDataRedis
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis
官网:https://spring.io/projects/spring-data-redis
- 提供了对不同Redis客户端的整合(Lettuce和Jedis)
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型
- 支持Redis哨兵和Redis集群
- 支持基于JDK.JSON、字符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的JDKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。并且将不同数据类型的操作API封装到了不同的类型中:

入门SpringDataRedis
创建SpringBoot项目
- pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.9.RELEASE</version>
<relativePath/>
</parent>
<groupId>com.zixieqing</groupId>
<artifactId>02-spring-data-redis</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>02-spring-data-redis</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>8</java.version>
</properties>
<dependencies>
<!--redis依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!--common-pool-->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!--Jackson依赖-->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
- YAML文件配置
spring:
redis:
host: 192.168.46.128
port: 6379
password: "072413"
jedis:
pool:
max-active: 100 # 最大连接数
max-idle: 100 # 最大空闲数
min-idle: 0 # 最小空闲数
max-wait: 5 # 最大链接等待时间 单位:ms
- 测试:其他如Hash、List、Set、SortedSet的方法和下面String差不多
package com.zixieqing.springdataredis;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
@SpringBootTest(classes = App.class)
class ApplicationTests {
@Resource
private RedisTemplate<String, Object> redisTemplate;
/**
* SpringDataRedis操作redis:String类型 其他类型都是同理操作
*
* String:opsForValue
* Hash:opsForHash
* List:opsForList
* Set:opsForSet
* SortedSet:opsForZSet
*/
@Test
void stringTest() {
// 添加key-value
redisTemplate.opsForValue().set("name", "紫邪情");
// 根据key获取value
String getName = Objects.requireNonNull(redisTemplate.opsForValue().get("name")).toString();
System.out.println("getName = " + getName);
// 添加key-value 并 指定有效期
redisTemplate.opsForValue().set("job", "Java", 10L, TimeUnit.SECONDS);
String getJob = Objects.requireNonNull(redisTemplate.opsForValue().get("job")).toString();
System.out.println("getJob = " + getJob);
// 就是 setnx 命令,key不存在则添加,存在则不执行
redisTemplate.opsForValue().setIfAbsent("city", "杭州");
redisTemplate.opsForValue().setIfAbsent("info", "脸皮厚,欠揍", 10L, TimeUnit.SECONDS);
ArrayList<String> keys = new ArrayList<>();
keys.add("name");
keys.add("job");
keys.add("city");
keys.add("info");
redisTemplate.delete(keys);
}
}
数据序列化
RedisTemplate可以接收Object类型作为值写入Redis:
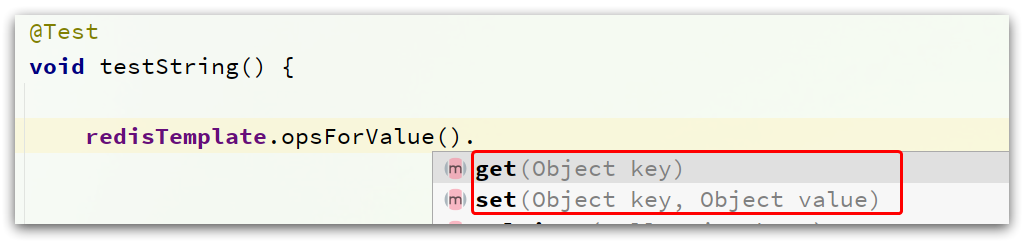
只不过写入前会把Object序列化为字节形式,默认是采用JDK序列化,得到的结果是这样的:

缺点:
- 可读性差
- 内存占用较大
Jackson序列化
我们可以自定义RedisTemplate的序列化方式,代码如下:
package com.zixieqing.springdataredis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializer;
/**
* redis自定义序列化方式
*
* @author : ZiXieqing
*/
@Configuration
public class RedisSerializeConfig {
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory){
// 创建RedisTemplate对象
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 设置连接工厂
template.setConnectionFactory(connectionFactory);
// 创建JSON序列化工具
GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();
// 设置Key的序列化
template.setKeySerializer(RedisSerializer.string());
template.setHashKeySerializer(RedisSerializer.string());
// 设置Value的序列化
template.setValueSerializer(jsonRedisSerializer);
template.setHashValueSerializer(jsonRedisSerializer);
// 返回
return template;
}
}
这里采用了JSON序列化来代替默认的JDK序列化方式。最终结果如图:

整体可读性有了很大提升,并且能将Java对象自动的序列化为JSON字符串,并且查询时能自动把JSON反序列化为Java对象
不过,其中记录了序列化时对应的class名称,目的是为了查询时实现自动反序列化。这会带来额外的内存开销。
StringRedisTemplate
尽管JSON的序列化方式可以满足我们的需求,但依然存在一些问题

为了在反序列化时知道对象的类型,JSON序列化器会将类的class类型写入json结果中,存入Redis,会带来额外的内存开销。
为了减少内存的消耗,我们可以采用手动序列化的方式,换句话说,就是不借助默认的序列化器,而是我们自己来控制序列化的动作,同时,我们只采用String的序列化器,这样,在存储value时,我们就不需要在内存中多存储数据,从而节约我们的内存空间
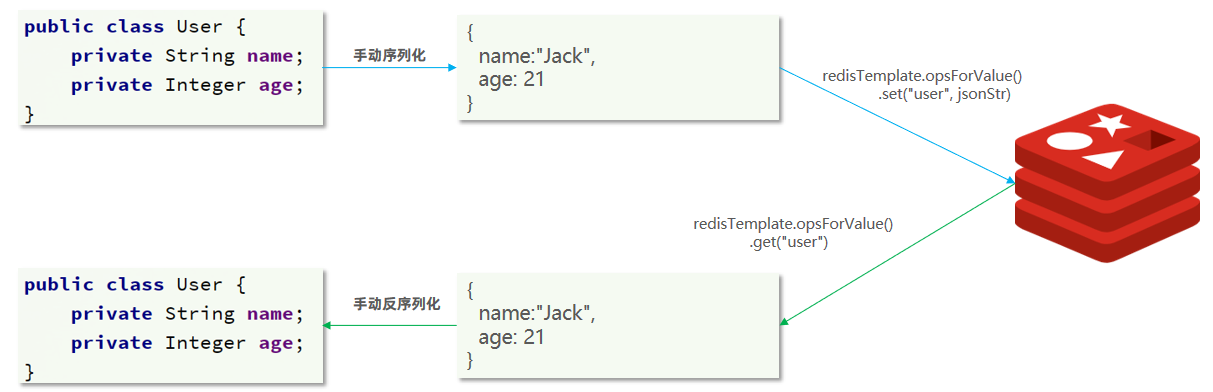
这种用法比较普遍,因此SpringDataRedis就提供了RedisTemplate的子类:StringRedisTemplate,它的key和value的序列化方式默认就是String方式


使用示例:
package com.zixieqing.springdataredis;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.zixieqing.springdataredis.entity.User;
import lombok.extern.slf4j.Slf4j;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.StringRedisTemplate;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.Objects;
import java.util.concurrent.TimeUnit;
@Slf4j
@SpringBootTest(classes = App.class)
class ApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
// 是jackson中的
private final ObjectMapper mapper = new ObjectMapper();
/**
* 使用StringRedisTemplate操作Redis 和 序列化与反序列化
*
* 操作redis和String类型一样的
*/
@Test
void serializeTest() throws JsonProcessingException {
User user = new User();
user.setName("zixieqing")
.setJob("Java");
// 序列化
String userStr = mapper.writeValueAsString(user);
stringRedisTemplate.opsForValue().set("com:zixieqing:springdataredis:user", userStr);
// 反序列化
String userStr2 = stringRedisTemplate.opsForValue().get("com:zixieqing:springdataredis:user");
User user2 = mapper.readValue(userStr2, User.class);
log.info("反序列化结果:{}", user2);
}
}

缓存更新策略
缓存更新是redis为了节约内存而设计出来的一个东西,主要是因为内存数据宝贵,当我们向redis插入太多数据,此时就可能会导致缓存中的数据过多,所以redis会对部分数据进行淘汰

内存淘汰:redis自动进行,当redis内存达到咱们设定的max-memery的时候,会自动触发淘汰机制,淘汰掉一些不重要的数据(可以自己设置策略方式)
超时剔除:当我们给redis设置了过期时间ttl之后,redis会将超时的数据进行删除,方便咱们继续使用缓存
主动更新:我们可以手动调用方法把缓存删掉,通常用于解决缓存和数据库不一致问题
业务场景:先说结论,后面分析这些结论是怎么来的
- 低一致性需求:使用Redis自带的内存淘汰机制
- 高一致性需求:主动更新,并以超时剔除作为兜底方案读操作:
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间写操作
- 写操作:
- 先写数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性(单体系统写库操作和删除缓存操作放入一个事务;分布式系统使用分布式事务管理这二者)
- 读操作:
主动更新策略:数据库与缓存不一致问题
由于我们的缓存的数据源来自于数据库,而数据库的数据是会发生变化的。因此,如果当数据库中数据发生变化,而缓存却没有同步,此时就会有一致性问题存在,其后果是:
用户使用缓存中的过时数据,就会产生类似多线程数据安全问题,从而影响业务,产品口碑等;怎么解决呢?有如下几种方案

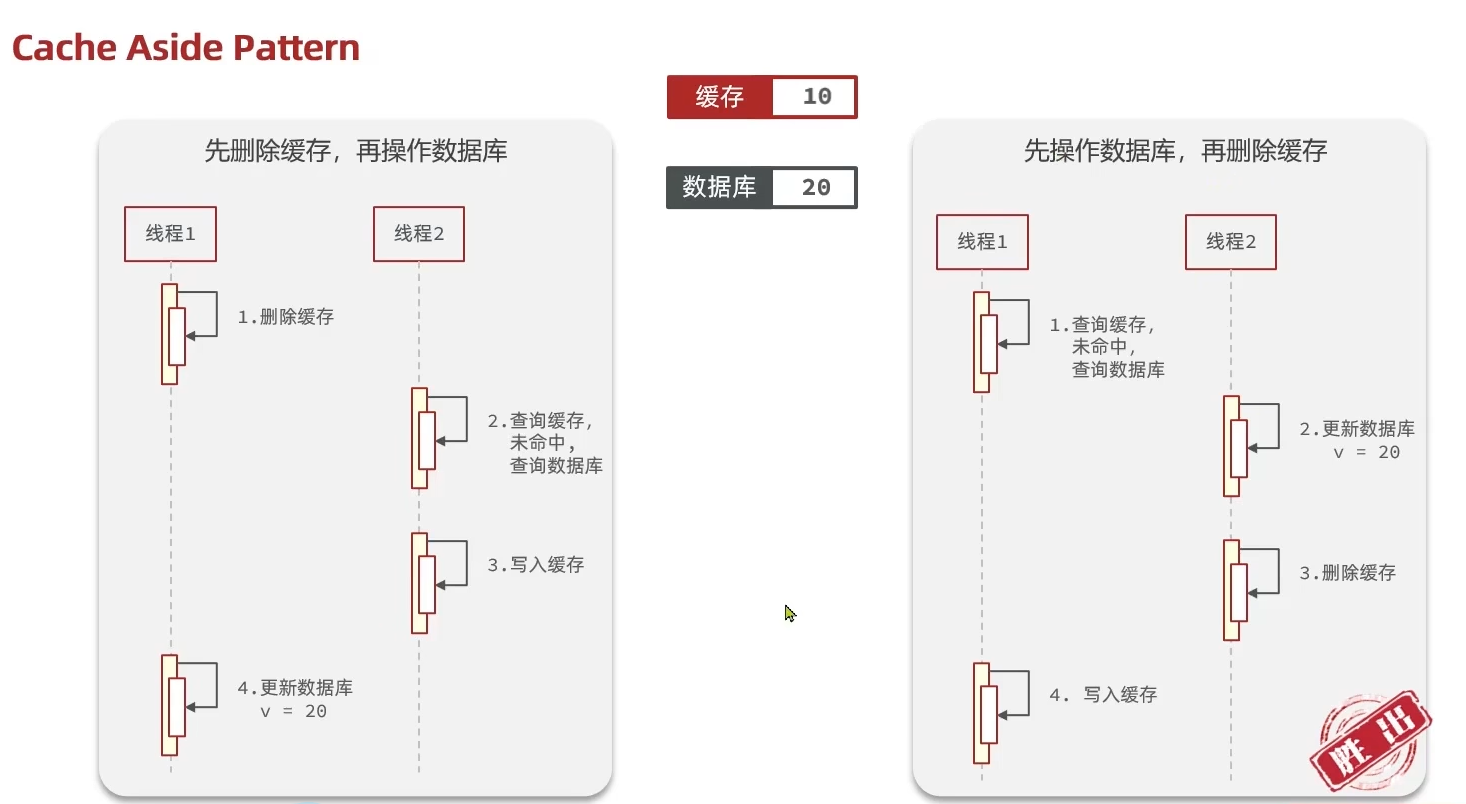
Cache Aside Pattern 人工编码方式:缓存调用者在更新完数据库后再去更新缓存,也称之为双写方案。这种由我们自己编写,所以可控,因此此种方式胜出
Read/Write Through Pattern : 由系统本身完成,数据库与缓存的问题交由系统本身去处理
Write Behind Caching Pattern :调用者只操作缓存,其他线程去异步处理数据库,实现最终一致
Cache Aside 人工编码 解决数据库与缓存不一致
由上一节知道数据库与缓存不一致的解决方案是 Cache Aside 人工编码,但是这个玩意儿需要考虑几个问题:
-
删除缓存还是更新缓存?
-
更新缓存:每次更新数据库都更新缓存,无效写操作较多
-
删除缓存:更新数据库时让缓存失效,查询时再更新缓存(胜出)
-
-
如何保证缓存与数据库的操作的同时成功或失败?
- 单体系统,将缓存与数据库操作放在一个事务
- 分布式系统,利用TCC等分布式事务方案
-
先操作缓存还是先操作数据库?
-
先删除缓存,再操作数据库
-
先操作数据库,再删除缓存(胜出)
-
为什么是先操作数据库,再删除缓存?
操作数据库和操作缓存在“串行”情况下没什么太大区别,问题不大,但是:在“并发”情况下,二者就有区别,就会产生数据库与缓存数据不一致的问题
先看“先删除缓存,再操作数据库”:
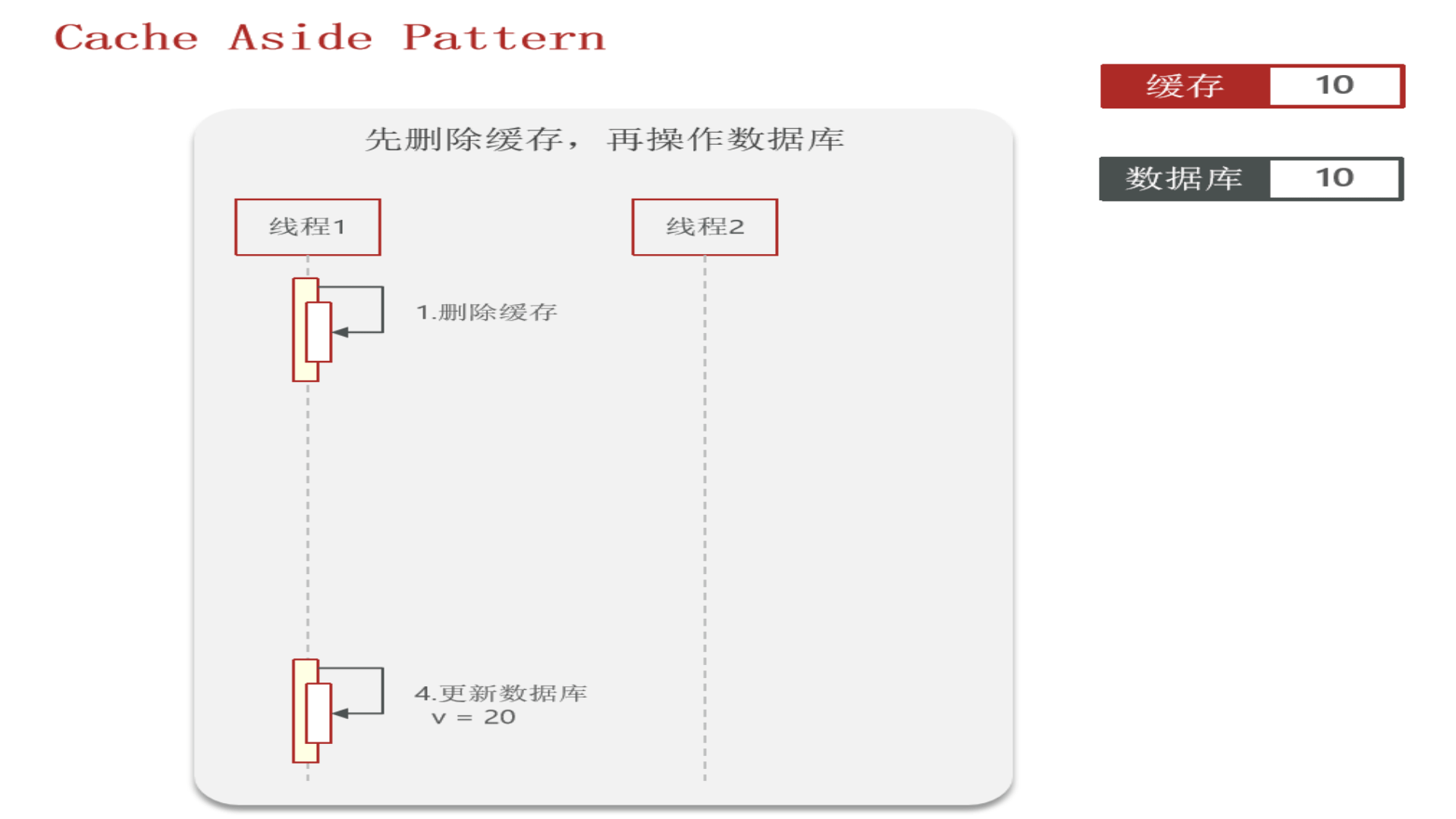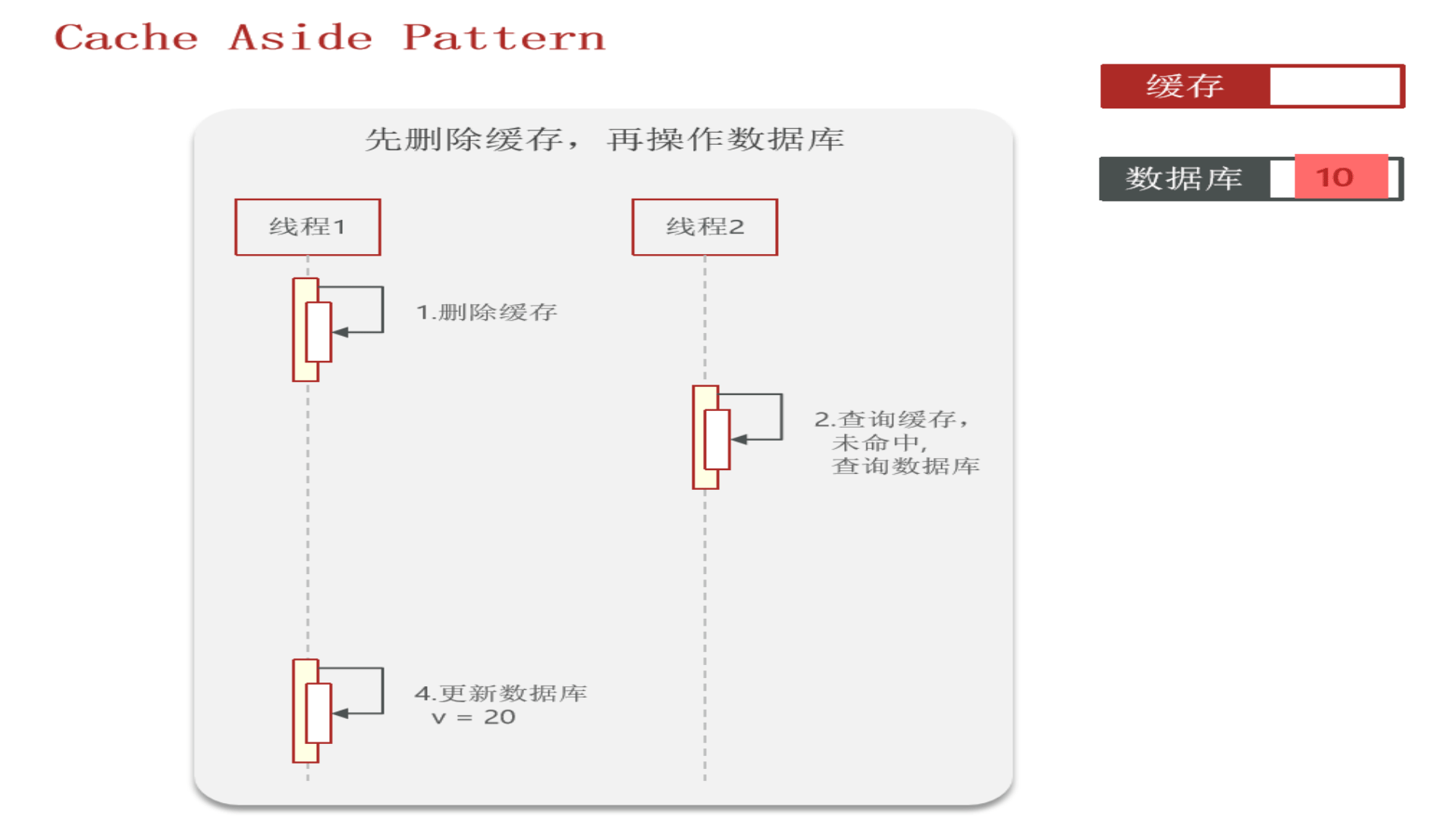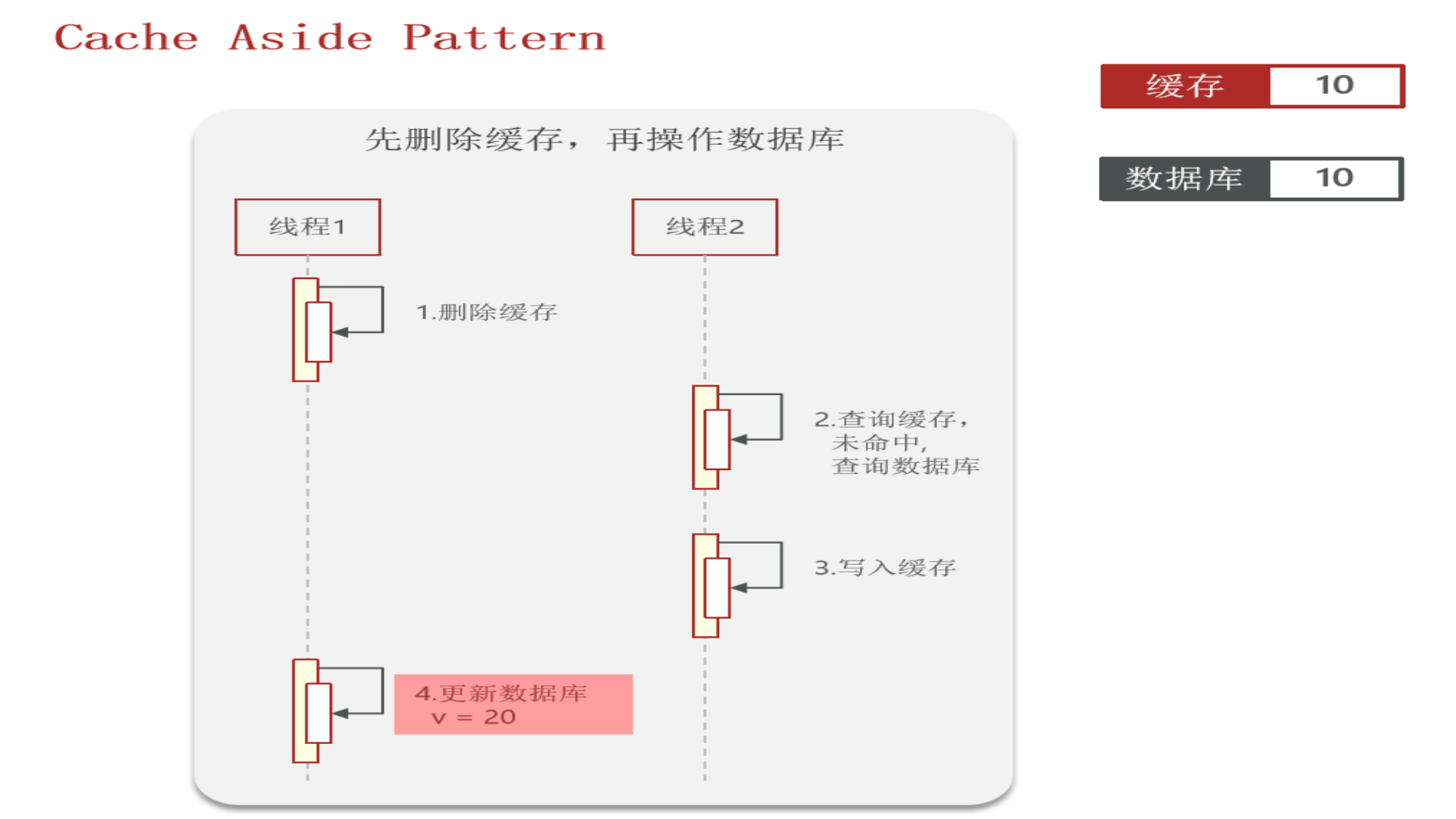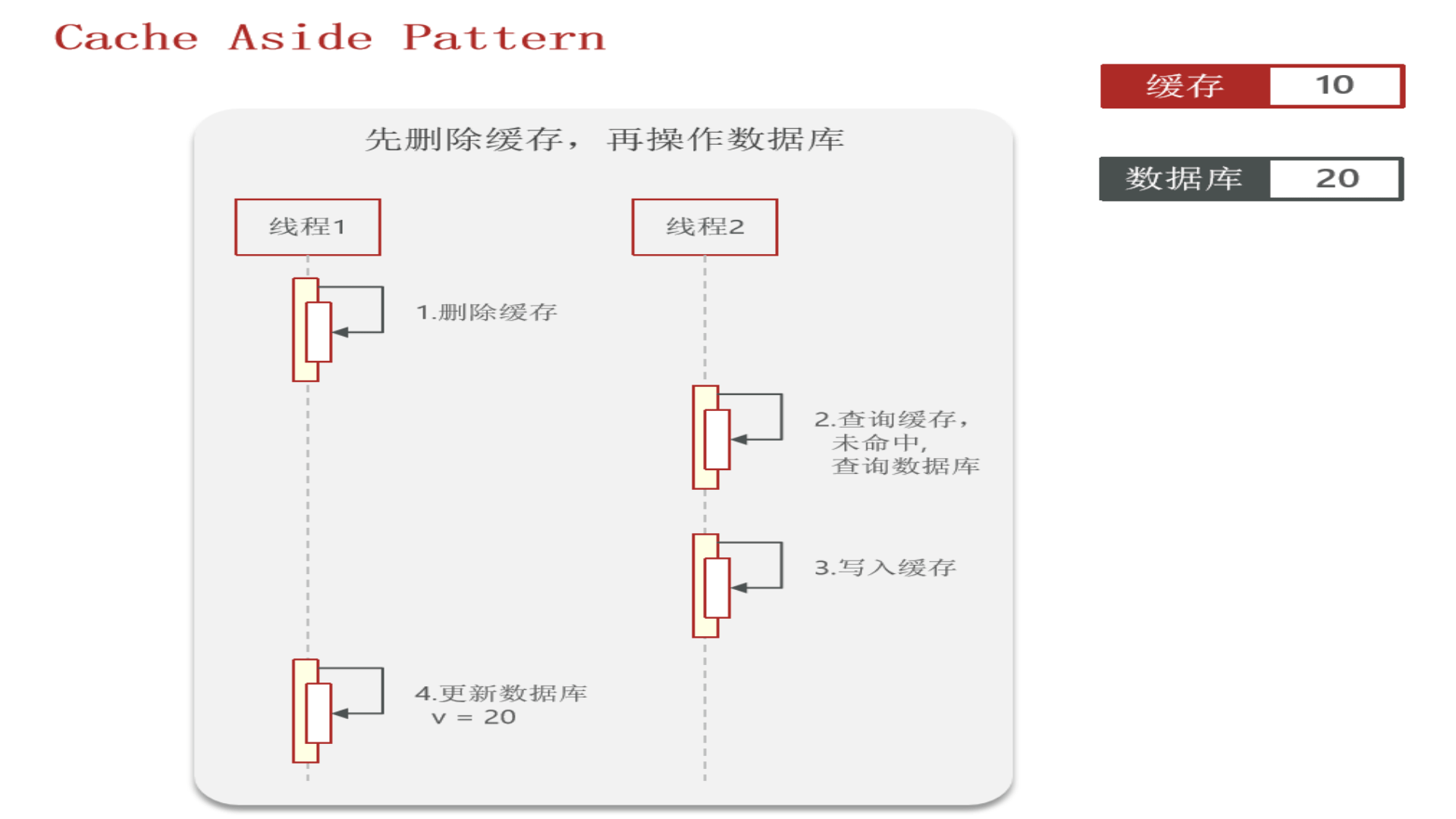
再看“先操作数据库,再删除缓存”:redis操作几乎是微秒级,所以下图线程1会很快完成,然后线程2业务一般都慢一点,所以缓存中能极快地更新成数据库中的最新数据,因此这种方式虽也会发生数据不一致,但几率很小(数据库操作一般不会在微秒级别内完成)
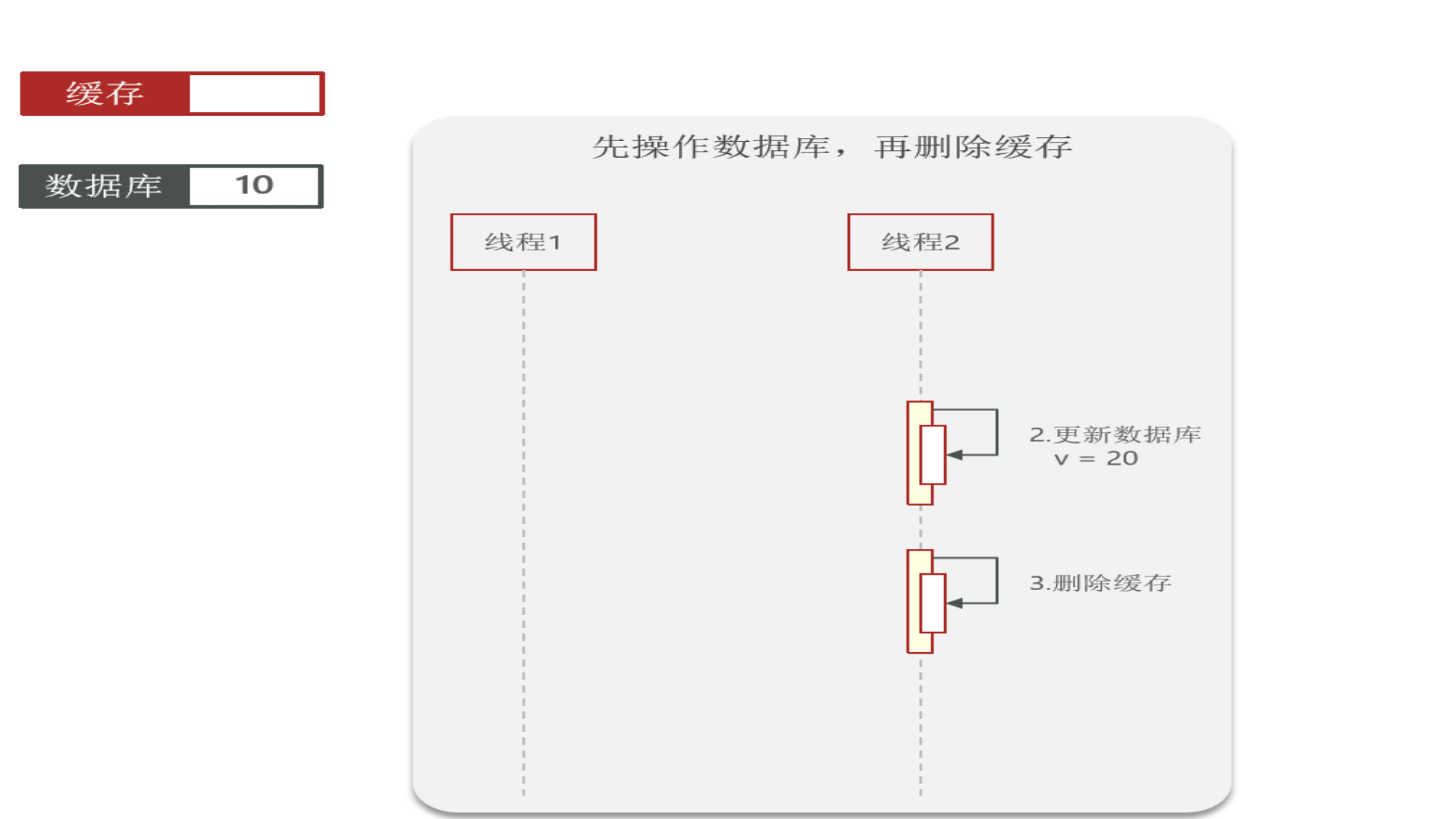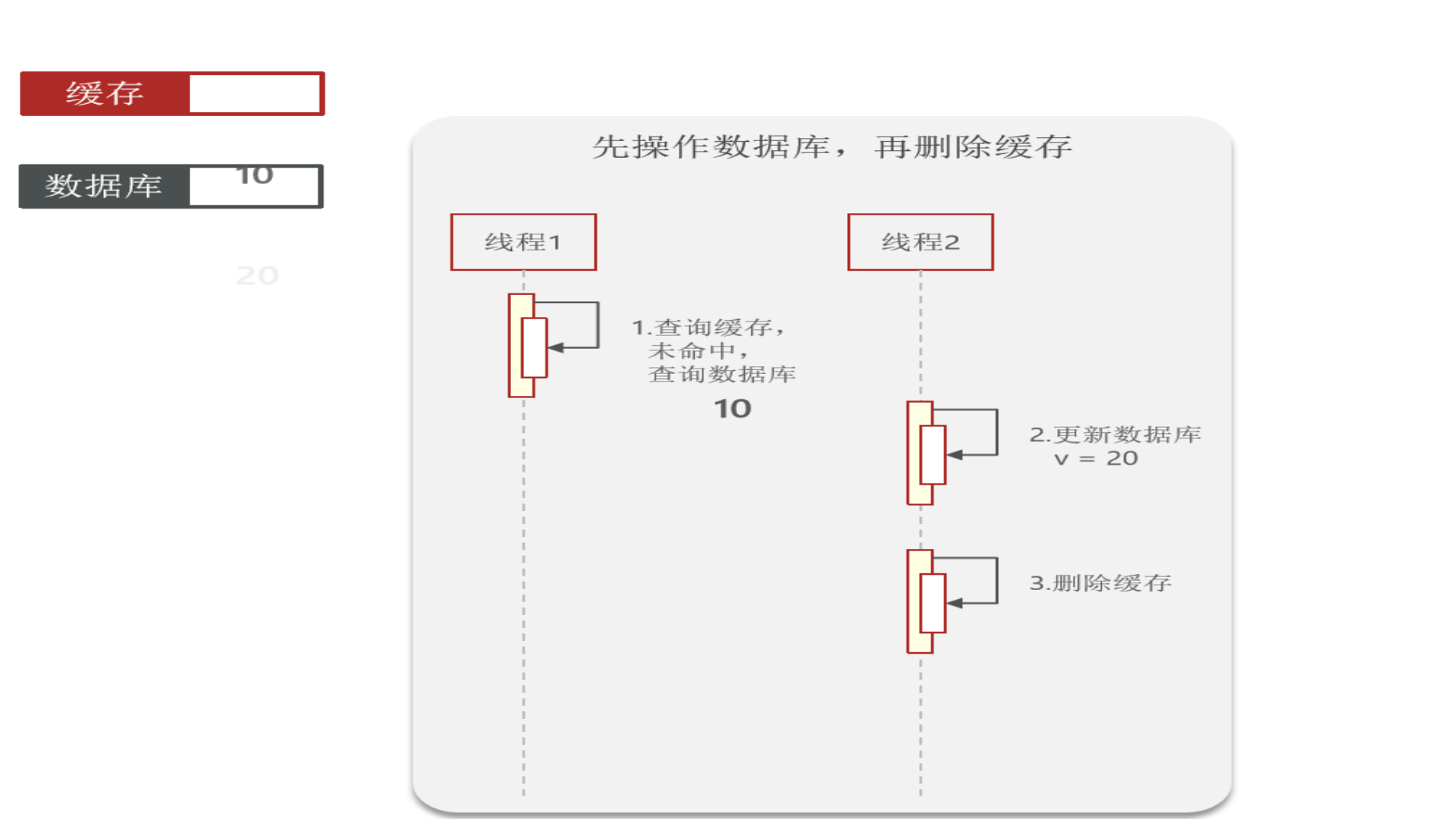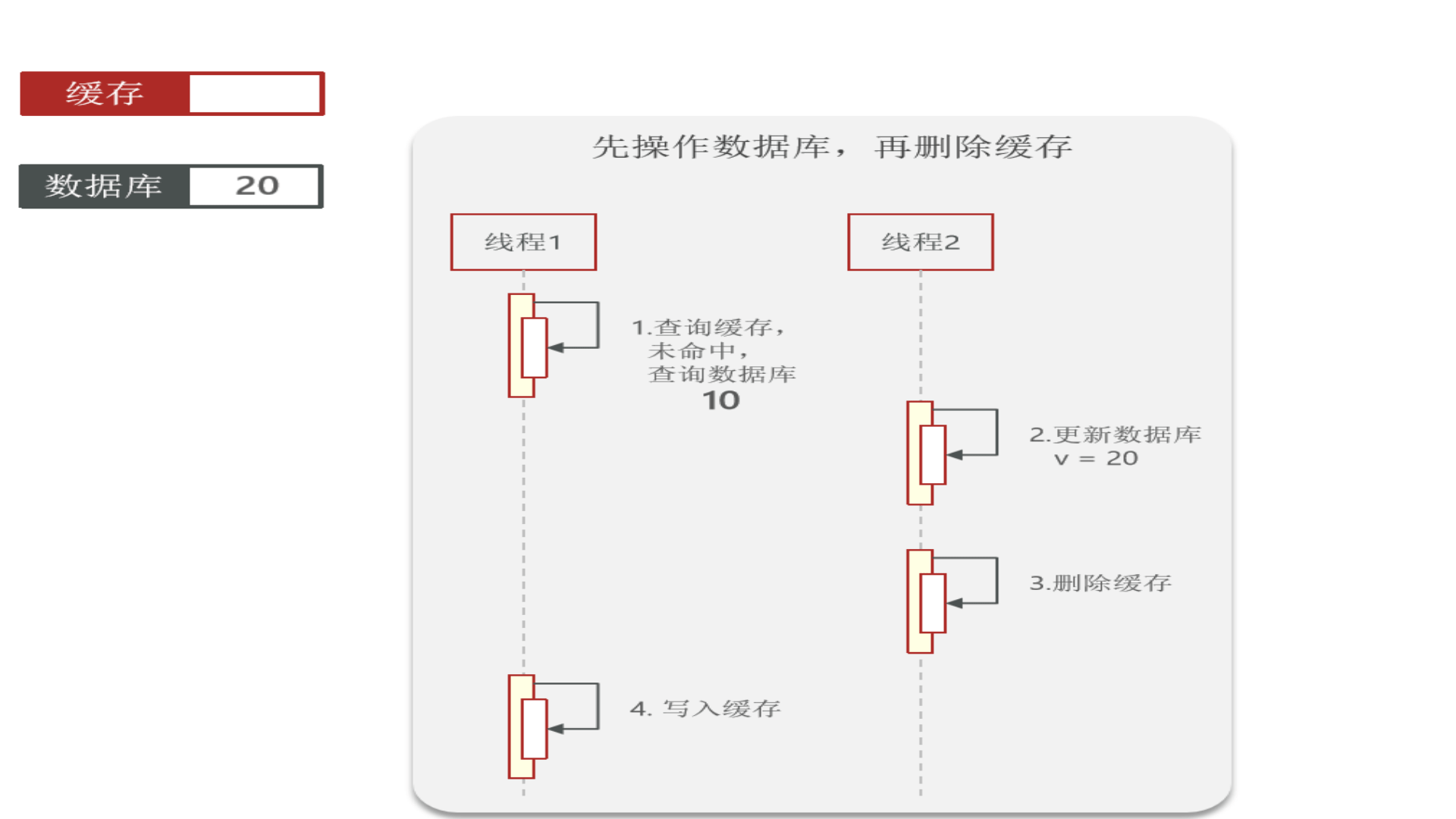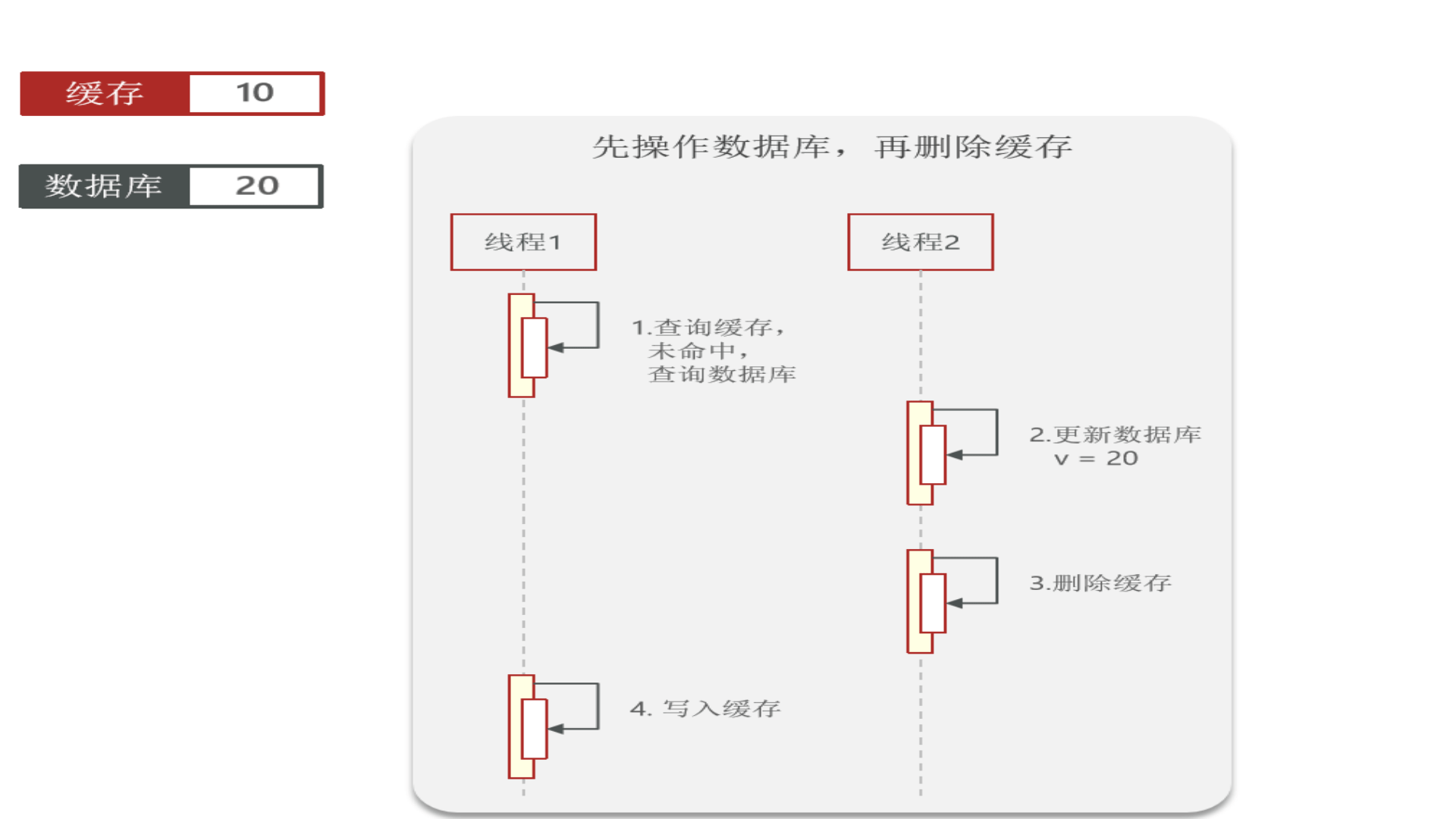
因此:胜出的是“先操作数据库,再删除缓存”
缓存穿透及解决方式
缓存穿透:指客户端请求的数据在缓存中和数据库中都不存在。这样缓存永远不会生效,这些请求都会打到数据库
场景:如别人模仿id,然后发起大量请求,而这些id对应的数据redis中没有,然后全跑去查库,数据库压力就会增大,导致数据库扛不住而崩掉
解决方式:
-
缓存空对象:就是缓存和数据库中都没有时,直接放个空对象到缓存中,并设置有效期即可
-
优点:实现简单,维护方便
-
缺点:
- 额外的内存消耗
- 可能造成短期的不一致。一开始redis和数据库都没有,后面新增了数据,而此数据的id可能恰好对上,这样redis中存的这id的数据还是空对象
-
-
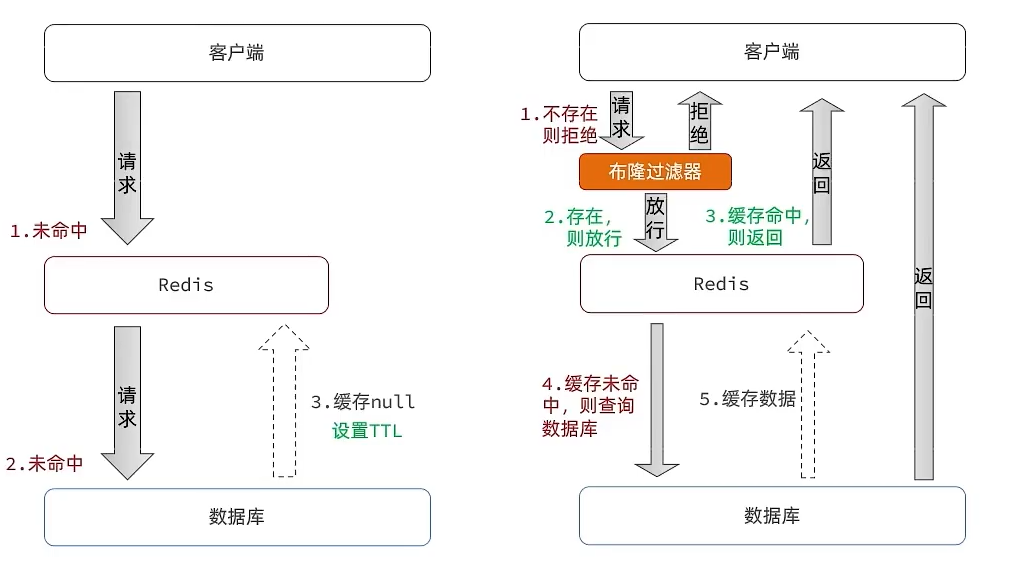
布隆过滤:采用的是哈希思想来解决这个问题,通过一个庞大的二进制数组,用哈希思想去判断当前这个要查询的数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回
-
优点:内存占用较少,没有多余key
-
缺点:
-
实现复杂
-
存在误判可能。布隆过滤器判断存在,可数据库中不一定真存在,因它采用的是哈希算法,就会产生哈希冲突
-
-
-
增加主键id的复杂度,从而提前做好基础数据校验
-
做用户权限认证
-
做热点参数限流
空对象和布隆过滤的架构如下:左为空对象,右为布隆过滤
缓存空对象示例:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result findShopById(Long id) {
String cacheKey = CACHE_SHOP_KEY + id;
// 查 redis
Map<Object, Object> shopMap = stringRedisTemplate.opsForHash().entries(cacheKey);
// 有则返回 同时需要看是否命中的是:空对象
if (!shopMap.isEmpty()) {
return Result.ok(JSONUtil.toJsonStr(shopMap));
}
// 无则查库
Shop shop = getById(id);
// 库中无
if (null == shop) {
// 向 redis 中放入 空对象,且设置有效期
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put("", "");
stringRedisTemplate.opsForHash().putAll(cacheKey, hashMap);
// CACHE_NULL_TTL = 2L
stringRedisTemplate.expire(cacheKey, CACHE_NULL_TTL, TimeUnit.MINUTES);
return Result.fail("商铺不存在");
}
// 库中有 BeanUtil 使用的是hutool工具
// 这步意思:因为Shop实例类中字段类型不是均为String,因此需要将字段值转成String,否则存入Redis时会发生 造型异常
Map<String, Object> shopMapData = BeanUtil.beanToMap(shop, new HashMap<>(16),
CopyOptions.create()
.ignoreNullValue()
.setIgnoreError(false)
.setFieldValueEditor((filedKey, filedValue) -> filedValue = filedValue + "")
);
// 写入 redis
stringRedisTemplate.opsForHash().putAll(cacheKey, shopMapData);
// 设置有效期 CACHE_SHOP_TTL = 30L
stringRedisTemplate.expire(cacheKey, CACHE_SHOP_TTL, TimeUnit.MINUTES);
// 返回客户端
return Result.ok(JSONUtil.toJsonStr(shop));
}
}
缓存雪崩及解决方式
缓存雪崩:指在同一时段大量的缓存key同时失效 或 Redis服务宕机,导致大量请求到达数据库,带来巨大压力
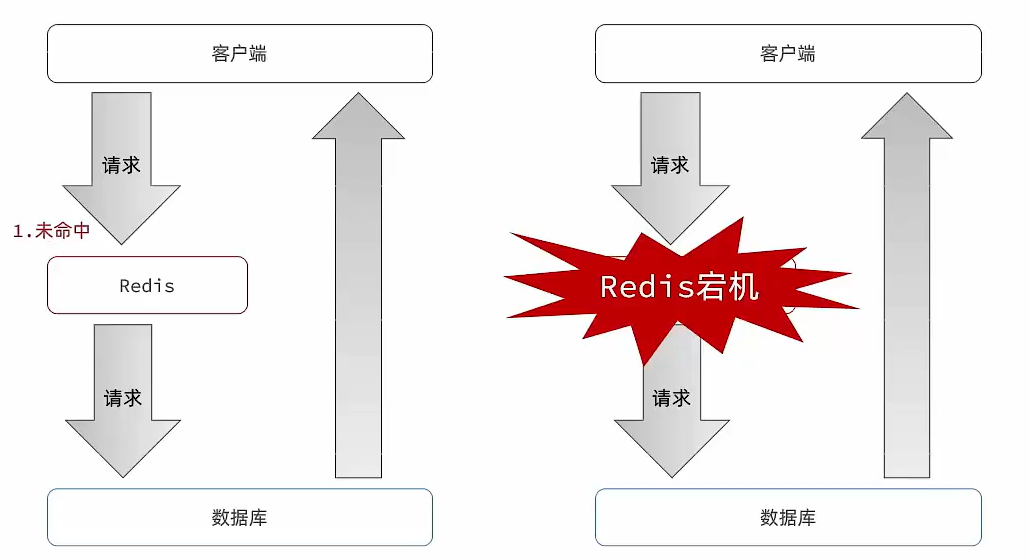
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿及解决方式
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击

常见的解决方案有两种:
- 互斥锁
- 逻辑过期
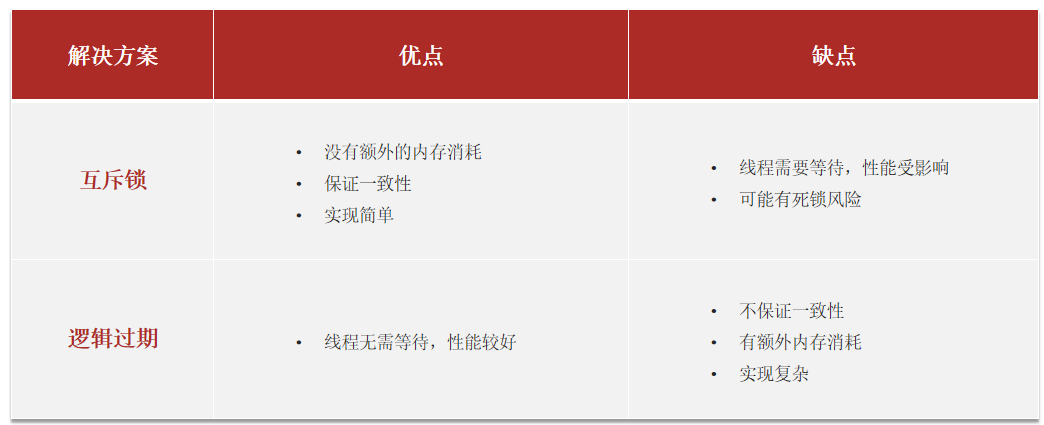
互斥锁 - 保一致
互斥锁:保一致性,会让线程阻塞,有死锁风险
本质:利用了String的setnx指令;key不存在则添加,存在则不操作

示例:下列逻辑该封装则封装即可
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public Result queryShopById(Long id) {
String cacheKey = CACHE_SHOP_KEY + id;
// 查 redis
Map<Object, Object> shopMap = stringRedisTemplate.opsForHash().entries(cacheKey);
// redis 中有责返回
if (!shopMap.isEmpty()) {
Shop shop = BeanUtil.fillBeanWithMap(shopMap, new Shop(), false);
return Result.ok(shop);
}
Shop shop = null;
try {
// 无则获取 互斥锁
Boolean res = stringRedisTemplate
.opsForValue()
.setIfAbsent(LOCK_SHOP_KEY + id, UUID.randomUUID().toString(true), LOCK_SHOP_TTL, TimeUnit.MINUTES);
boolean flag = BooleanUtil.isTrue(res);
// 获取失败则等一会儿再试
if (!flag) {
Thread.sleep(20);
return queryShopById(id);
}
// 获取锁成功则查 redis 此时有没有,从而减少缓存重建
Map<Object, Object> shopMa = stringRedisTemplate.opsForHash().entries(cacheKey);
// redis 中有责返回
if (!shopMa.isEmpty()) {
shop = BeanUtil.fillBeanWithMap(shopMa, new Shop(), false);
return Result.ok(shop);
}
// 有则返回,无则查库
shop = getById(id);
// 库中无
if (null == shop) {
// 向 redis放入 空值,并设置有效期
Map<String, String> hashMap = new HashMap<>(16);
hashMap.put("", "");
stringRedisTemplate.opsForHash().putAll(cacheKey, hashMap);
stringRedisTemplate.expire(cacheKey, 2L, TimeUnit.MINUTES);
return Result.fail("无此数据");
}
// 库中有则写入 redis,并设置有效期
Map<String, Object> sMap = BeanUtil.beanToMap(shop, new HashMap<>(16),
CopyOptions.create()
.ignoreNullValue()
.setIgnoreError(false)
.setFieldValueEditor((filedKey, filedValue) -> filedValue = filedValue + "")
);
stringRedisTemplate.opsForHash().putAll(cacheKey, sMap);
stringRedisTemplate.expire(cacheKey, CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 释放锁
stringRedisTemplate.delete(LOCK_SHOP_KEY + id);
}
//返回客户端
return Result.ok(shop);
}
}
逻辑过期 - 保性能
这玩意儿在互斥锁的基础上再变动一下即可
逻辑过期:不保一致性,性能好,有额外内存消耗,会造成短暂的数据不一致
本质:数据不过期,一直在Redis中,只是程序员自己使用过期字段和当前时间来判定是否过期,过期则获取“互斥锁”,获取锁成功(此时可以再判断一下Redis中的数据是否过期,减少缓存重建),则开线程重建缓存即可
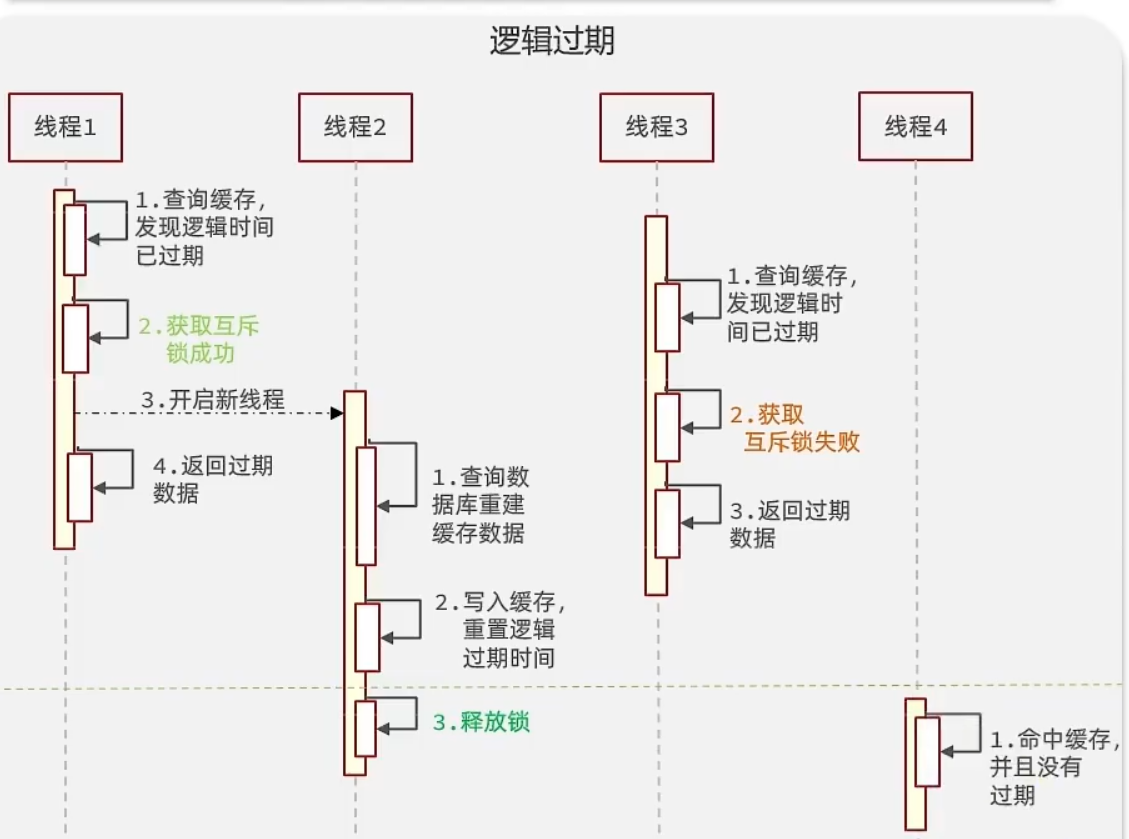
示例:
@Data
@Accessors(chain = true)
public class RedisData {
private LocalDateTime expireTime;
private Object data;
}
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {
@Resource
private StringRedisTemplate stringRedisTemplate;
private static final ExecutorService EXECUTORS = Executors.newFixedThreadPool(10);
@Override
public Result queryShopById(Long id) {
// 使用互斥锁解决 缓存击穿
// return cacheBreakDownWithMutex(id);
String cacheKey = CACHE_SHOP_KEY + id;
// 查 redis
String shopJson = stringRedisTemplate.opsForValue().get(cacheKey);
// redis 中没有则报错(理论上是一直存在redis中的,逻辑过期而已,所以这一步不用判断都可以)
if (StrUtil.isBlank(shopJson)) {
return Result.fail("无此数据");
}
// redis 中有,则看是否过期
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
LocalDateTime expireTime = redisData.getExpireTime();
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
// 没过期,直接返回数据
if (expireTime.isAfter(LocalDateTime.now())) {
return Result.ok(shop);
}
try {
// 获取互斥锁 LOCK_SHOP_TTL = 10L
Boolean res = stringRedisTemplate
.opsForValue()
.setIfAbsent(LOCK_SHOP_KEY + id, UUID.randomUUID().toString(true),
LOCK_SHOP_TTL, TimeUnit.SECONDS);
boolean flag = BooleanUtil.isTrue(res);
// 获取锁失败则眯一会儿再尝试
if (!flag) {
Thread.sleep(20);
return queryShopById(id);
}
// 获取锁成功
// 再看 redis 中的数据是否过期,减少缓存重建
shopJson = stringRedisTemplate.opsForValue().get(cacheKey);
redisData = JSONUtil.toBean(shopJson, RedisData.class);
expireTime = redisData.getExpireTime();
shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
// 已过期
if (expireTime.isBefore(LocalDateTime.now())) {
EXECUTORS.submit(() -> {
// 重建缓存
this.buildCache(id, 20L);
});
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 释放锁
stringRedisTemplate.delete(LOCK_SHOP_KEY + id);
}
// 返回客户端
return Result.ok(shop);
}
/**
* 重建缓存
*/
public void buildCache(Long id, Long expireTime) {
String key = LOCK_SHOP_KEY + id;
// 重建缓存
Shop shop = getById(id);
if (null == shop) {
// 库中没有则放入 空对象
stringRedisTemplate.opsForValue().set(key, "", 10L, TimeUnit.SECONDS);
}
RedisData redisData = new RedisData();
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireTime))
.setData(shop);
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
}
简单认识Lua脚本
Redis提供了Lua脚本功能,在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性
基本语法可以参考网站:https://www.runoob.com/lua/lua-tutorial.html
Redis提供的调用函数,语法如下:
redis.call('命令名称', 'key', '其它参数', ...)
如:先执行set name Rose,再执行get name,则脚本如下:
# 先执行 set name jack
redis.call('set', 'name', 'Rose')
# 再执行 get name
local name = redis.call('get', 'name')
# 返回
return name
写好脚本以后,需要用Redis命令来调用脚本,调用脚本的常见命令如下:
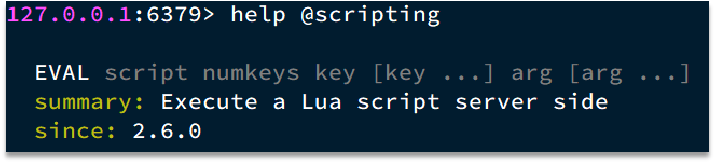
例如,我们要执行 redis.call('set', 'name', 'jack') 这个脚本,语法如下:

如果脚本中的key、value不想写死,可以作为参数传递
key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数:

Java+Redis调用Lua脚本
RedisTemplate中,可以利用execute方法去执行lua脚本,参数对应关系就如下图股

示例:
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
// 搞出脚本对象 DefaultRedisScript是RedisTemplate的实现类
UNLOCK_SCRIPT = new DefaultRedisScript<>();
// 脚本在哪个旮旯地方
UNLOCK_SCRIPT.setLocation(new ClassPathResource("unlock.lua"));
// 返回值类型
UNLOCK_SCRIPT.setResultType(Long.class);
}
public void unlock() {
// 调用lua脚本
stringRedisTemplate.execute(
UNLOCK_SCRIPT, // lua脚本
Collections.singletonList(KEY_PREFIX + name), // 对应key参数的数值:KEYS数组
ID_PREFIX + Thread.currentThread().getId()); // 对应其他参数的数值:ARGV数组
}
Redisson
官网地址: https://redisson.org
GitHub地址: https://github.com/redisson/redisson
分布式锁需要解决几个问题:而下图的问题可以通过Redisson这个现有框架解决

Redisson是一个在Redis的基础上实现的Java驻内存数据网格(In-Memory Data Grid)。它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务,其中就包含了各种分布式锁的实现

使用Redisson
- 依赖2
<!-- 基本 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.13.6</version>
</dependency>
<!-- Spring Boot整合的依赖 -->
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.13.6</version>
</dependency>
- 创建redisson客户端
YAML配置:常用参数戳这里
spring:
application:
name: springboot-redisson
redis:
redisson:
config: |
singleServerConfig:
password: "redis服务密码"
address: "redis:/redis服务ip:6379"
database: 1
threads: 0
nettyThreads: 0
codec: !<org.redisson.codec.FstCodec> {}
transportMode: "NIO"
代码配置
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.redisson.config.TransportMode;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
Config config = new Config();
config.setTransportMode(TransportMode.NIO);
// 添加redis地址,这里添加了单点的地址,也可以使用 config.useClusterServers() 添加集群地址
config.useSingleServer()
.setAddress("redis://redis服务ip:6379")
.setPassword("redis密码");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
- 使用redisson客户端
@Resource
private RedissionClient redissonClient;
@Test
void testRedisson() throws Exception{
// 获取锁(可重入),指定锁的名称
RLock lock = redissonClient.getLock("lockName");
/*
* 尝试获取锁
*
* 参数分别是:获取锁的最大等待时间(期间会重试),锁自动释放时间,时间单位
*/
boolean isLock = lock.tryLock(1, 10, TimeUnit.SECONDS);
// 判断获取锁成功
if(isLock){
try{
System.out.println("执行业务");
}finally{
//释放锁
lock.unlock();
}
}
}
Redisson 可重入锁原理
- 采用Hash结构
- key为锁名
- field为线程标识
- value就是一个计数器count,同一个线程再来获取锁就让此值 +1,同线程释放一次锁此值 -1
- PS:Java中使用的是state,C语言中用的是count,作用差不多
源码在:lock.tryLock(waitTime, leaseTime, TimeUnit)中,leaseTime这个参数涉及到WatchDog机制,所以可以直接看 lock.tryLock(waitTime, TimeUnit) 这个的源码
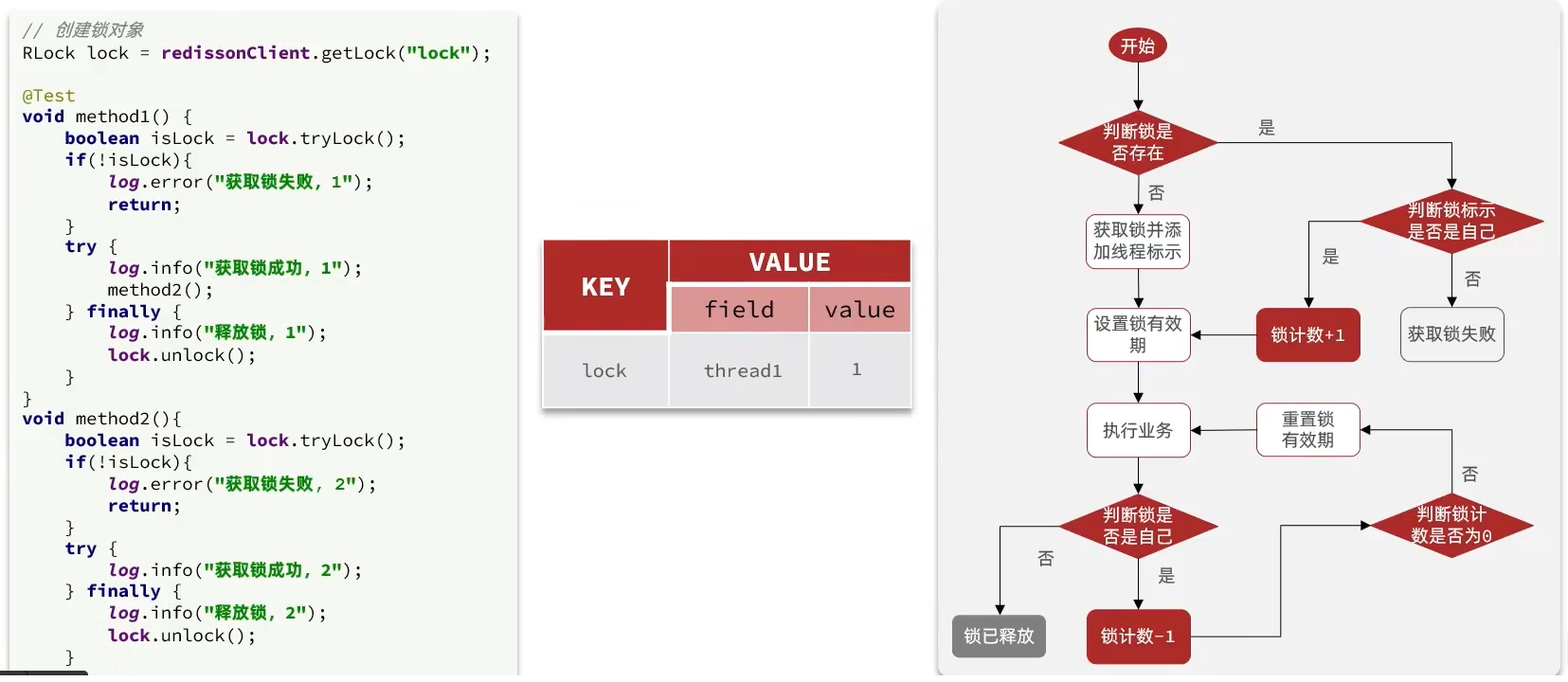
核心点在里面的lua脚本中:
"if (redis.call('exists', KEYS[1]) == 0) then " + -- KEYS[1] : 锁名称 判断锁是否存在
-- ARGV[2] = id + ":" + threadId 锁的小key 充当 field
"redis.call('hset', KEYS[1], ARGV[2], 1); " + -- 当前这把锁不存在则添加锁,value=count=1 是hash结构
"redis.call('pexpire', KEYS[1], ARGV[1]); " + -- 并给此锁设置有效期
"return nil; " + -- 获取锁成功,返回nil,即:null
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " + -- 判断 key+field 是否存在。即:判断是否是同一线程来获取锁
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " + -- 是自己,让value +1
"redis.call('pexpire', KEYS[1], ARGV[1]); " + -- 给锁重置有效期
"return nil; " + -- 成功,返回nil,即:null
"end; " +
"return redis.call('pttl', KEYS[1]);" -- 获取锁失败(含失效),返回锁的TTL有效期
Redission 锁重试 和 WatchDog机制
看源码时选择:RedissonLock
锁重试
这里的 tryLock(long waitTime, long leaseTime, TimeUnit unit)选择的是带参的,无参的 tryLock()是,默认不会重试的
public class RedissonLock extends RedissonExpirable implements RLock {
@Override
public boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException {
// 将 waitTime 最大等待时间转成 毫秒
long time = unit.toMillis(waitTime);
// 获取此时的毫秒值
long current = System.currentTimeMillis();
// 获取当前线程ID
long threadId = Thread.currentThread().getId();
// 抢锁逻辑:涉及到WatchDog,待会儿再看
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// lock acquired 表示在上一步 tryAcquire() 中抢锁成功
if (ttl == null) {
return true;
}
// 有获取当前时间
time -= System.currentTimeMillis() - current;
// 看执行上面的逻辑之后,是否超出了waitTime最大等待时间
if (time <= 0) {
// 超出waitTime最大等待时间,则获取锁失败
acquireFailed(waitTime, unit, threadId);
return false;
}
// 再精确时间,看经过上面逻辑之后,是否超出waitTime最大等待时间
current = System.currentTimeMillis();
// 订阅 发布逻辑是在 lock.unLock() 的逻辑中,里面有一个lua脚本,使用了 publiser 命令
RFuture<RedissonLockEntry> subscribeFuture = subscribe(threadId);
// 若订阅在waitTime最大等待时间内未完成,即超出waitTime最大等待时间
if (!subscribeFuture.await(time, TimeUnit.MILLISECONDS)) {
// 同时订阅也未取消
if (!subscribeFuture.cancel(false)) {
subscribeFuture.onComplete((res, e) -> {
if (e == null) {
// 则取消订阅
unsubscribe(subscribeFuture, threadId);
}
});
}
// 订阅在waitTime最大等待时间内未完成,则获取锁失败
acquireFailed(waitTime, unit, threadId);
return false;
}
try {
// 继续精确时间,经过上面逻辑之后,是否超出waitTime最大等待时间
time -= System.currentTimeMillis() - current;
if (time <= 0) {
acquireFailed(waitTime, unit, threadId);
return false;
}
// 还在waitTime最大等待时间内 这里面就是重试的逻辑
while (true) {
long currentTime = System.currentTimeMillis();
// 抢锁
ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
// lock acquired 获取锁成功
if (ttl == null) {
return true;
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) { // 经过上面逻辑之后,时间已超出waitTime最大等待时间,则获取锁失败
acquireFailed(waitTime, unit, threadId);
return false;
}
// waiting for message
currentTime = System.currentTimeMillis();
// 未失效 且 失效期还在 waitTime最大等待时间 以内
if (ttl >= 0 && ttl < time) {
// 同时该进程也未被中断,则通过该信号量继续获取锁
subscribeFuture.getNow().getLatch().tryAcquire(ttl, TimeUnit.MILLISECONDS);
} else {
// 否则处于任务调度的目的,从而禁用当前线程,让其处于休眠状态
// 除非其他线程调用当前线程的 release方法 或 当前线程被中断 或 waitTime已过
subscribeFuture.getNow().getLatch().tryAcquire(time, TimeUnit.MILLISECONDS);
}
time -= System.currentTimeMillis() - currentTime;
if (time <= 0) {
// 还未获取锁成功,那就真的是获取锁失败了
acquireFailed(waitTime, unit, threadId);
return false;
}
}
} finally {
// 取消订阅
unsubscribe(subscribeFuture, threadId);
}
// return get(tryLockAsync(waitTime, leaseTime, unit));
}
}
上面说到“订阅”,“发布”的逻辑需要进入:lock.unlock();,和前面说的一样,选择:RedissonLock
import org.junit.jupiter.api.Test;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
import java.util.concurrent.TimeUnit;
@SpringBootTest
class ApplicationTests {
@Resource
private RedissonClient redissonClient;
/**
* 伪代码
*/
@Test
void buildCache() throws InterruptedException {
// 获取 锁名字
RLock lock = redissonClient.getLock("");
// 获取锁
boolean isLock = lock.tryLock(1L, TimeUnit.SECONDS);
// 释放锁
lock.unlock();
}
}
public class RedissonLock extends RedissonExpirable implements RLock {
protected RFuture<Boolean> unlockInnerAsync(long threadId) {
return evalWriteAsync(
getName(),
LongCodec.INSTANCE,
RedisCommands.EVAL_BOOLEAN,
"if (redis.call('hexists', KEYS[1], ARGV[3]) == 0) then " +
"return nil;" +
"end; " +
"local counter = redis.call('hincrby', KEYS[1], ARGV[3], -1); " +
"if (counter > 0) then " +
"redis.call('pexpire', KEYS[1], ARGV[2]); " +
"return 0; " +
"else " +
"redis.call('del', KEYS[1]); " +
"redis.call('publish', KEYS[2], ARGV[1]); " + // 发布,从而在上面的 重试 中进行订阅
"return 1; " +
"end; " +
"return nil;",
Arrays.asList(
getName(), getChannelName()), LockPubSub.UNLOCK_MESSAGE,
internalLockLeaseTime, getLockName(threadId)
);
}
}
WatchDog 机制
上一节中有如下的代码:进入 tryAcquire()
// 抢锁逻辑:涉及到WatchDog,待会儿再看
Long ttl = tryAcquire(waitTime, leaseTime, unit, threadId);
public class RedissonLock extends RedissonExpirable implements RLock {
private Long tryAcquire(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
return get(tryAcquireAsync(waitTime, leaseTime, unit, threadId));
}
/**
* 异步获取锁
*/
private <T> RFuture<Long> tryAcquireAsync(long waitTime, long leaseTime, TimeUnit unit, long threadId) {
// leaseTime到期时间 等于 -1 否,此值决定着是否开启watchDog机制
if (leaseTime != -1) {
return tryLockInnerAsync(waitTime, leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(
waitTime,
/*
* getLockWatchdogTimeout() 就是获取 watchDog 时间,即:
* private long lockWatchdogTimeout = 30 * 1000;
*/
commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(),
TimeUnit.MILLISECONDS,
threadId,
RedisCommands.EVAL_LONG
);
// 上一步ttlRemainingFuture异步执行完时
ttlRemainingFuture.onComplete((ttlRemaining, e) -> {
// 若出现异常了,则说明获取锁失败,直接滚犊子了
if (e != null) {
return;
}
// lock acquired 获取锁成功
if (ttlRemaining == null) {
// 过期了,则重置到期时间,进入这个方法瞄一下
scheduleExpirationRenewal(threadId);
}
});
return ttlRemainingFuture;
}
/**
* 重新续约到期时间
*/
private void scheduleExpirationRenewal(long threadId) {
ExpirationEntry entry = new ExpirationEntry();
/*
* private static final ConcurrentMap<String, ExpirationEntry> EXPIRATION_RENEWAL_MAP = new ConcurrentHashMap<>();
*
* getEntryName() 就是 this.entryName = id + ":" + name
* 而 this.id = commandExecutor.getConnectionManager().getId()
*
* putIfAbsent() key未有value值则进行关联,相当于:
* if (!map.containsKey(key))
* return map.put(key, value);
* else
* return map.get(key);
*/
ExpirationEntry oldEntry = EXPIRATION_RENEWAL_MAP.putIfAbsent(getEntryName(), entry);
if (oldEntry != null) {
oldEntry.addThreadId(threadId);
} else {
entry.addThreadId(threadId);
// 续订到期 续约逻辑就在这里面
renewExpiration();
}
}
/**
* 续约
*/
private void renewExpiration() {
ExpirationEntry ee = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ee == null) {
return;
}
/*
* 这里 newTimeout(new TimerTask(), 参数2, 参数3) 指的是:参数2,参数3去描述什么时候去做参数1的事情
* 这里的参数2:internalLockLeaseTime / 3 就是前面的 lockWatchdogTimeout = (30 * 1000) / 3 = 1000ms = 10s
*
* 锁的失效时间是30s,当10s之后,此时这个timeTask 就触发了,它就去进行续约,把当前这把锁续约成30s,
* 如果操作成功,那么此时就会递归调用自己,再重新设置一个timeTask(),于是再过10s后又再设置一个timerTask,
* 完成不停的续约
*/
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
ExpirationEntry ent = EXPIRATION_RENEWAL_MAP.get(getEntryName());
if (ent == null) {
return;
}
Long threadId = ent.getFirstThreadId();
if (threadId == null) {
return;
}
// renewExpirationAsync() 里面就是一个lua脚本,脚本中使用 pexpire 指令重置失效时间,
// pexpire 此指令是以 毫秒 进行,expire是以 秒 进行
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.onComplete((res, e) -> {
if (e != null) {
log.error("Can't update lock " + getName() + " expiration", e);
return;
}
if (res) {
// reschedule itself 递归此方法,从而完成不停的续约
renewExpiration();
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
ee.setTimeout(task);
}
}
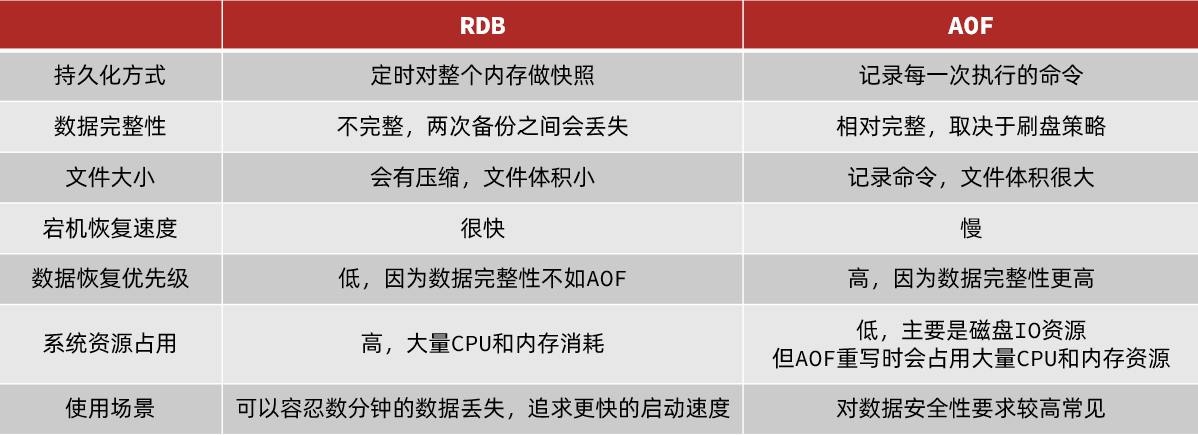
Redis持久化
分为两种:RDB和AOF
Redis的持久化虽然可以保证数据安全,但也会带来很多额外的开销,因此持久化请遵循下列建议:
- 用来做缓存的Redis实例尽量不要开启持久化功能
- 建议关闭RDB持久化功能,使用AOF持久化
- 利用脚本定期在slave节点做RDB,实现数据备份
- 设置合理的rewrite阈值,避免频繁的bgrewrite
- [不是绝对,依情况而行]配置no-appendfsync-on-rewrite = yes,禁止在rewrite / fork期间做aof,避免因AOF引起的阻塞
部署有关建议:
- Redis实例的物理机要预留足够内存,应对fork和rewrite
- 单个Redis实例内存上限不要太大,如4G或8G。可以加快fork的速度、减少主从同步、数据迁移压力
- 不要与CPU密集型应用部署在一起。如:一台虚拟机中部署了很多应用
- 不要与高硬盘负载应用一起部署。例如:数据库、消息队列.........,这些应用会不断进行磁盘IO
RDB 持久化
RDB全称Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。里面的内容是二进制。简单来说就是把内存中的所有数据都记录到磁盘中。当Redis实例故障重启后,从磁盘读取快照文件,恢复数据。快照文件称为RDB文件,默认是保存在当前运行目录(redis.conf的dir配置)
RDB持久化在四种情况下会执行::
- save命令:save命令会导致主进程执行RDB,这个过程中其它所有命令都会被阻塞。只有在数据迁移时可能用到。执行下面的命令,可以立即执行一次RDB

- bgsave命令:这个命令执行后会开启独立进程完成RDB,主进程可以持续处理用户请求,不受影响。下面的命令可以异步执行RDB

- Redis停机时:Redis停机时会执行一次save命令,实现RDB持久化
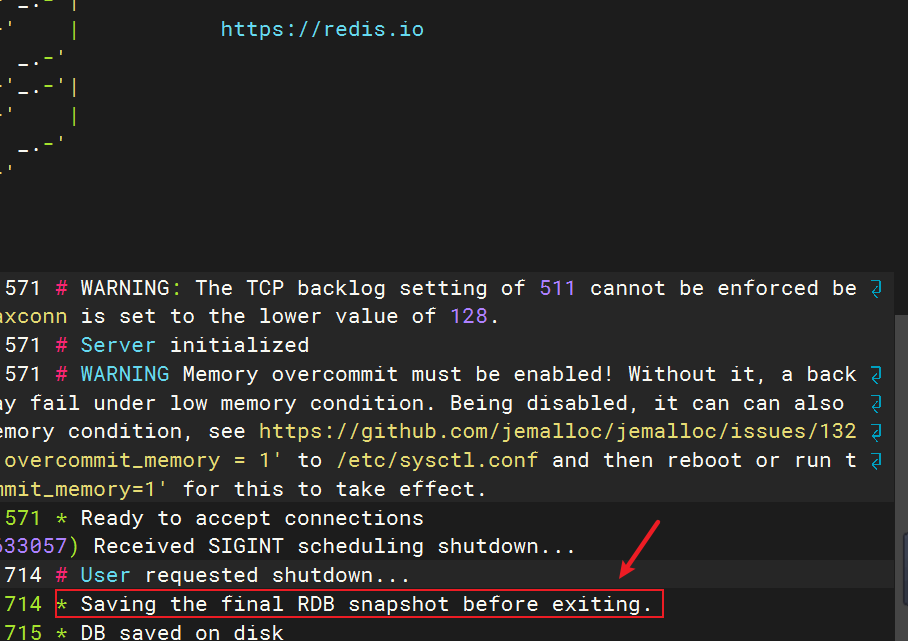
- 触发RDB条件:redis.conf文件中配置的条件满足时就会触发RDB,如下列样式
# 900秒内,如果至少有1个key被修改,则执行bgsave,如果是save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
RDB的其它配置也可以在redis.conf文件中设置:
# 是否压缩 ,建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
# RDB文件名称
dbfilename dump.rdb
# 文件保存的路径目录
dir ./
RDB的原理
RDB方式bgsave的基本流程?
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
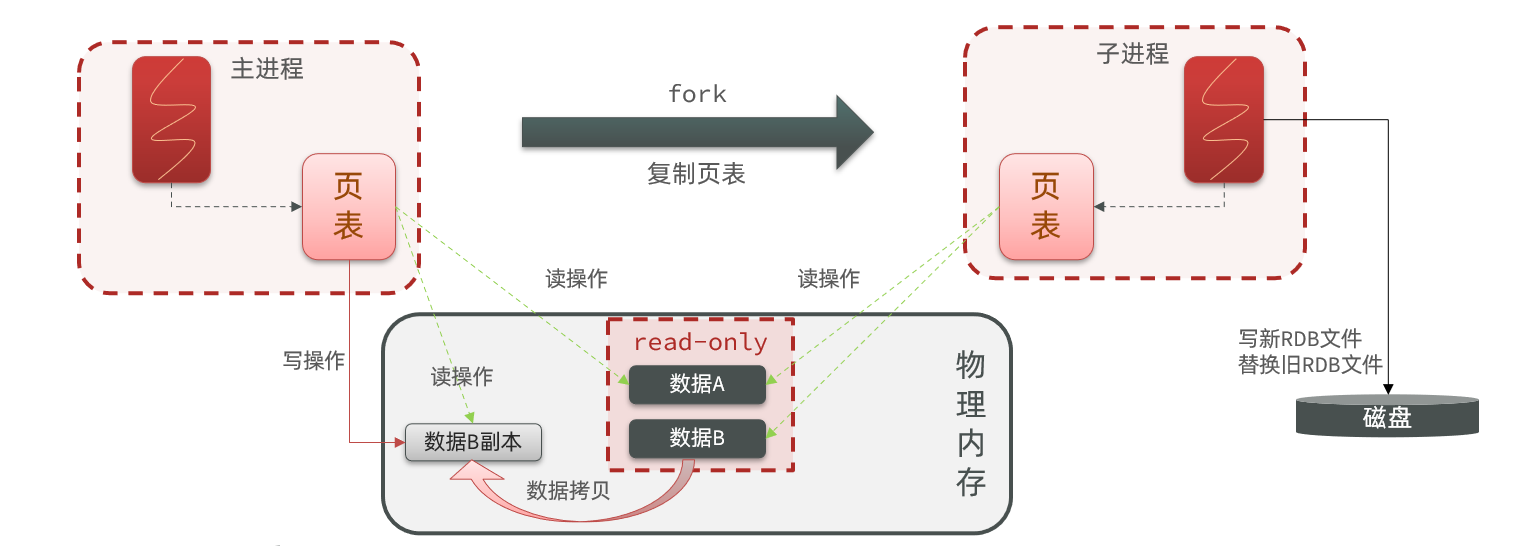
所以1可以得知:RDB的缺点
- RDB执行间隔时间长,两次RDB之间写入数据有丢失的风险
- fork子进程、压缩、写出RDB文件都比较耗时
AOF 持久化
AOF全称为Append Only File(追加文件)。Redis处理的每一个写命令都会记录在AOF文件,可以看做是命令日志文件

OF默认是关闭的,需要修改redis.conf配置文件来开启AOF:
# 是否开启AOF功能,默认是no
appendonly yes
# AOF文件的名称
appendfilename "appendonly.aof"
AOF的命令记录的频率也可以通过redis.conf文件来配:
# 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
# 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
# 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no
三种策略对比:

AOF文件重写
因为是记录命令,AOF文件会比RDB文件大的多。而且AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义。通过执行bgrewriteaof命令,可以让AOF文件执行重写功能,用最少的命令达到相同效果。

Redis也会在触发阈值时自动去重写AOF文件。阈值也可以在redis.conf中配置:
# AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
# AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb
主从数据同步原理
全量同步
完整流程描述:先说完整流程,然后再说怎么来的
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
主从第一次建立连接时,会执行全量同步,将master节点的所有数据都拷贝给slave节点,流程:
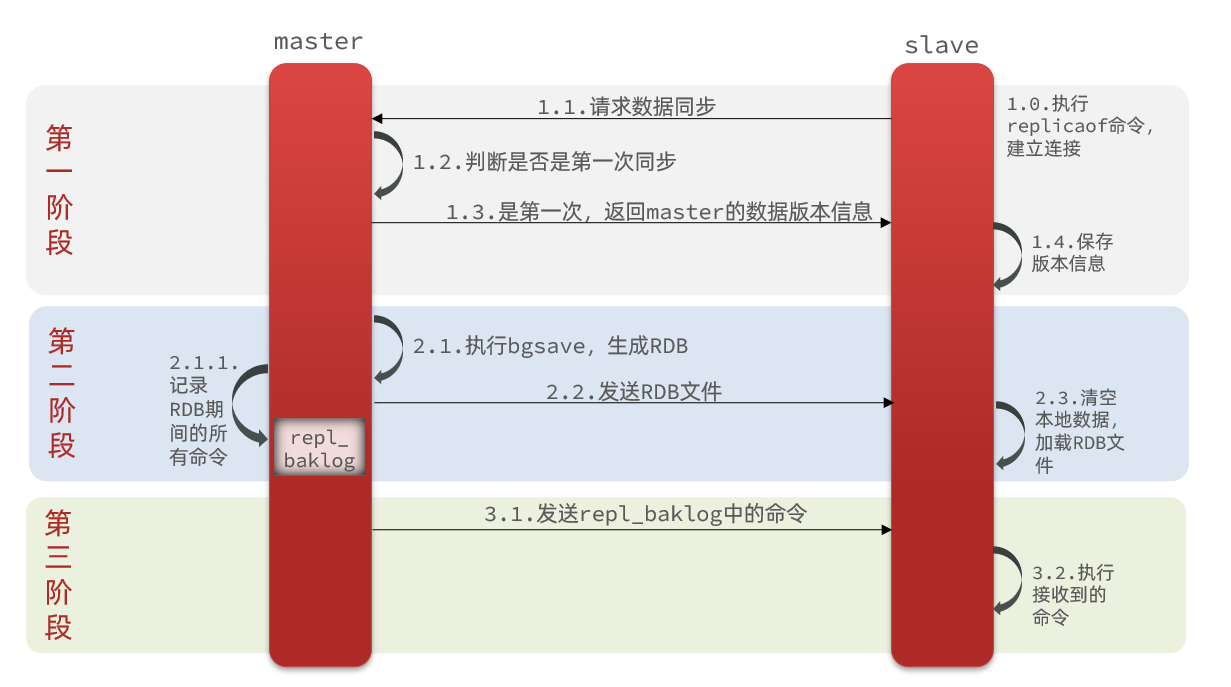
master如何得知salve是第一次来连接??
有两个概念,可以作为判断依据:
- Replication Id:简称replid,是数据集的标记,id一致则说明是同一数据集。每一个master都有唯一的replid,slave则会继承master节点的replid
- offset:偏移量,随着记录在repl_baklog中的数据增多而逐渐增大。slave完成同步时也会记录当前同步的offset。如果slave的offset小于master的offset,说明slave数据落后于master,需要更新
因此slave做数据同步,必须向master声明自己的replication id 和 offset,master才可以判断到底需要同步哪些数据
因为slave原本也是一个master,有自己的replid和offset,当第一次变成slave与master建立连接时,发送的replid和offset是自己的replid和offset
master判断发现slave发送来的replid与自己的不一致,说明这是一个全新的slave,就知道要做全量同步了
master会将自己的replid和offset都发送给这个slave,slave保存这些信息。以后slave的replid就与master一致了。
因此,master判断一个节点是否是第一次同步的依据,就是看replid是否一致。
如图:

增量同步
全量同步需要先做RDB,然后将RDB文件通过网络传输个slave,成本太高了。因此除了第一次做全量同步,其它大多数时候slave与master都是做增量同步
增量同步:就是只更新slave与master存在差异的部分数据
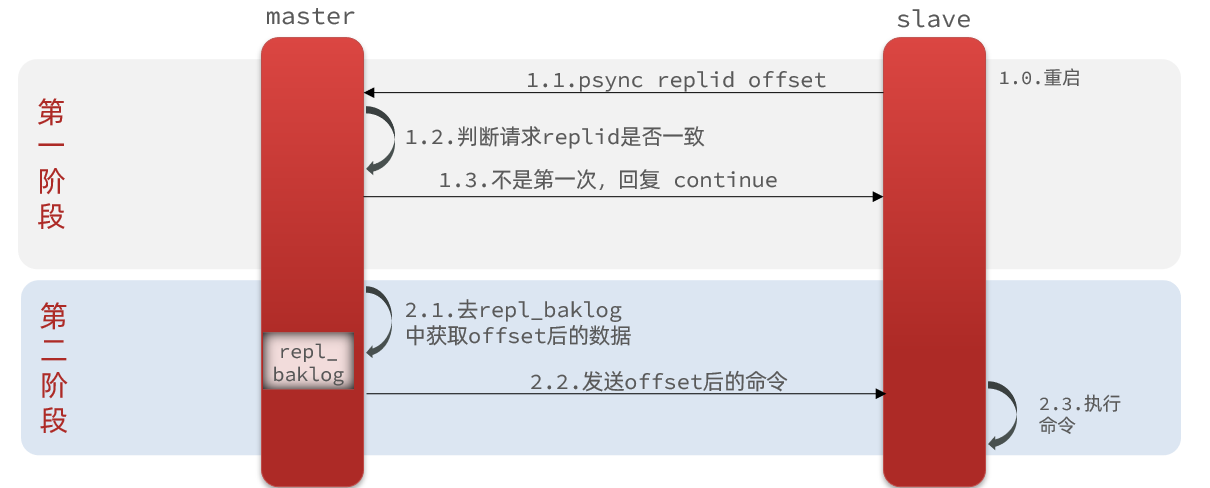
这种方式会出现失效的情况:原因就在repl_baklog中
repl_baklog原理
master怎么知道slave与自己的数据差异在哪里呢?
这就要说到全量同步时的repl_baklog文件了。
这个文件是一个固定大小的数组,只不过数组是环形,也就是说角标到达数组末尾后,会再次从0开始读写,这样数组头部的数据就会被覆盖。
repl_baklog中会记录Redis处理过的命令日志及offset,包括master当前的offset,和slave已经拷贝到的offset:
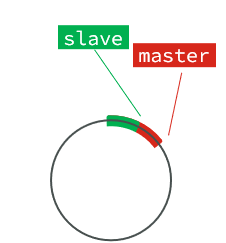
slave与master的offset之间的差异,就是salve需要增量拷贝的数据了。
随着不断有数据写入,master的offset逐渐变大,slave也不断的拷贝,追赶master的offset:
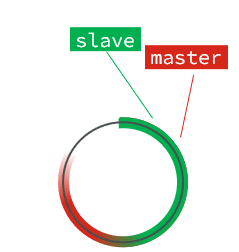
直到数组被填满:
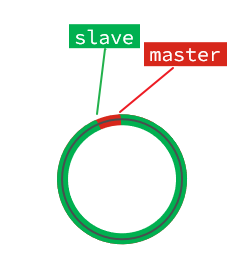
此时,如果有新的数据写入,就会覆盖数组中的旧数据。不过,旧的数据只要是绿色的,说明是已经被同步到slave的数据,即便被覆盖了也没什么影响。因为未同步的仅仅是红色部分。
但是,如果slave出现网络阻塞,导致master的offset远远超过了slave的offset:
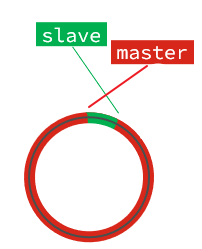
如果master继续写入新数据,其offset就会覆盖旧的数据,直到将slave现在的offset也覆盖:
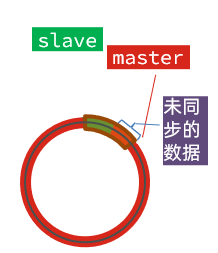
棕色框中的红色部分,就是尚未同步,但是却已经被覆盖的数据。此时如果slave恢复,需要同步,却发现自己的offset都没有了,无法完成增量同步了。只能做全量同步。

主从同步优化
可以从以下几个方面来优化Redis主从集群:
- 在master中配置repl-diskless-sync yes启用无磁盘复制,避免全量同步时的磁盘IO。
- Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力

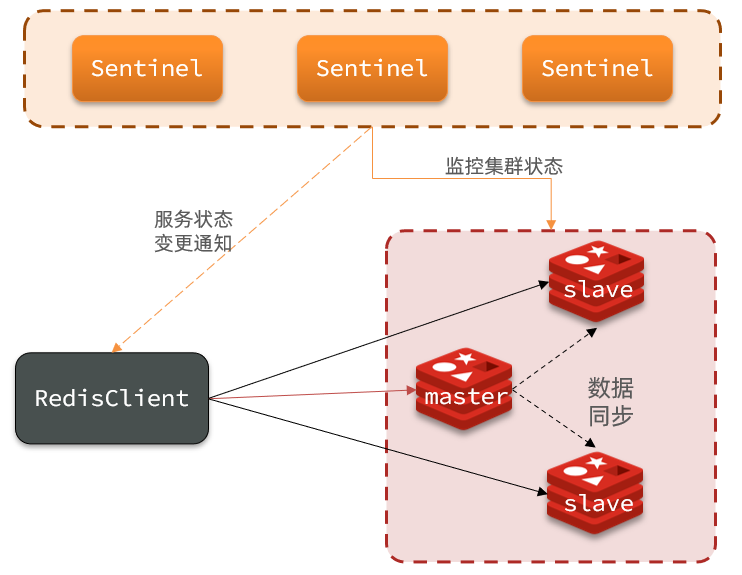
哨兵集群
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复
哨兵的作用
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
集群监控原理
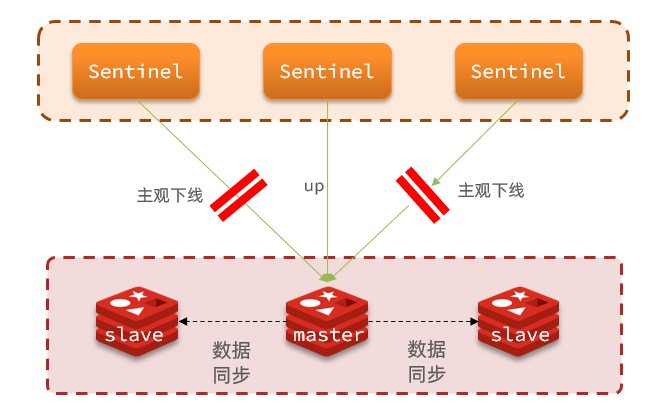
Sentinel基于心跳机制监测服务状态,每隔1秒向集群的每个实例发送ping命令:
- 主观下线:如果某sentinel节点发现某实例未在规定时间响应,则认为该实例主观下线
- 客观下线:若超过指定数量(quorum)的sentinel都认为该实例主观下线,则该实例客观下线。quorum值最好超过Sentinel实例数量的一半
集群故障恢复原理
一旦发现master故障,sentinel需要在salve中选择一个作为新的master,选择依据是这样的:
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(redis.conf配置的down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 若slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 若offset一样,则最后判断slave节点的运行id(redis开启时都会分配一个)大小,越小优先级越高
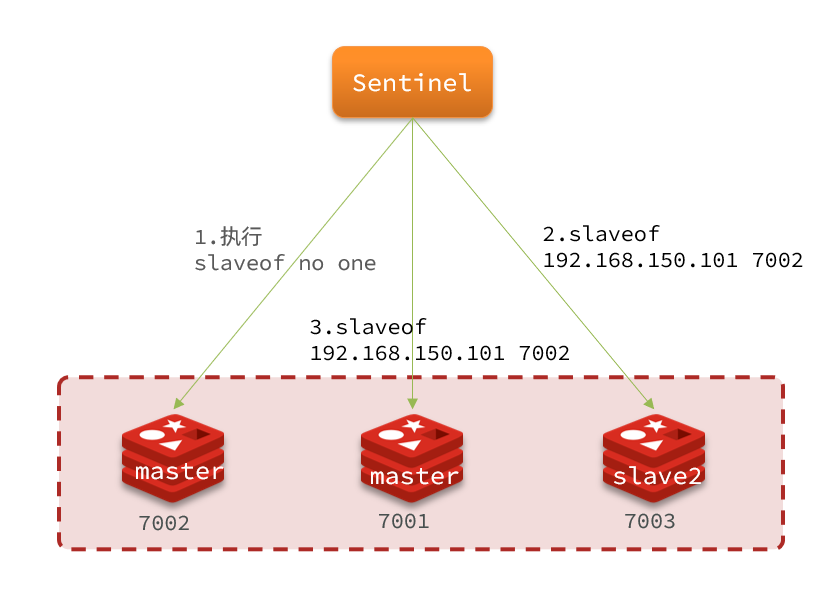
当选出一个新的master后,该如何实现切换?流程如下:
- sentinel链接备选的slave节点,让其执行 slaveof no one(翻译:不要当奴隶) 命令,让该节点成为master
- sentinel给所有其它slave发送
slaveof <newMasterIp> <newMasterPort>命令,让这些slave成为新master的从节点,开始从新的master上同步数据 - 最后,sentinel将故障节点标记为slave,当故障节点恢复后会自动成为新的master的slave节点
搭建哨兵集群
- 创建目录
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir s1 s2 s3
- 在s1目录中创建sentinel.conf文件,编辑如下内容
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
dir "/tmp/s1"
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
- 将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
# 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
# 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf
- 修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf
- 启动
# 第1个
redis-sentinel s1/sentinel.conf
# 第2个
redis-sentinel s2/sentinel.conf
# 第3个
redis-sentinel s3/sentinel.conf
RedisTemplate的哨兵模式
- 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- YAML配置哨兵集群
spring:
redis:
sentinel:
master: mymaster # 前面哨兵集群搭建时的名字
nodes:
- 192.168.150.101:27001 # 这里的ip:port是sentinel哨兵的,而不用关注哨兵监管下的那些节点
- 192.168.150.101:27002
- 192.168.150.101:27003
- 配置读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
- 就可以在需要的地方正常使用RedisTemplate了,如前面玩的StringRedisTemplate
分片集群
主从和哨兵可以解决高可用、高并发读的问题。但是依然有两个问题没有解决:
-
海量数据存储问题
-
高并发写的问题
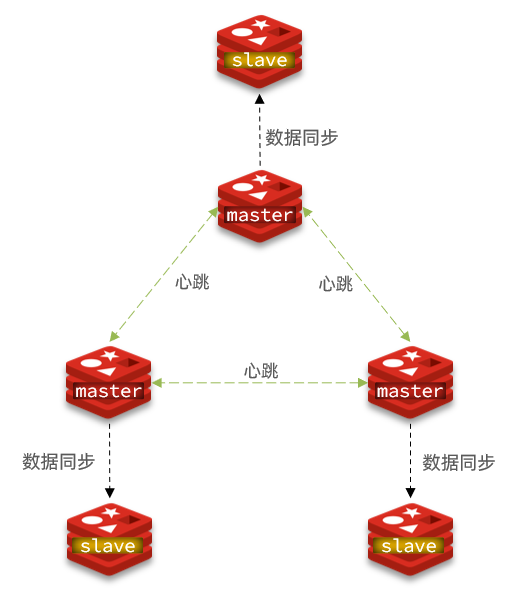
分片集群可解决上述问题,分片集群特征:
-
集群中有多个master,每个master保存不同数据
-
每个master都可以有多个slave节点
-
master之间通过ping监测彼此健康状态
-
客户端请求可以访问集群任意节点,最终都会被转发到正确节点
搭建分片集群
- 创建目录
# 进入/tmp目录
cd /tmp
# 创建目录
mkdir 7001 7002 7003 8001 8002 8003
- 在temp目录下新建redis.conf文件,编辑内容如下:
port 6379
# 开启集群功能
cluster-enabled yes
# 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
# 节点心跳失败的超时时间
cluster-node-timeout 5000
# 持久化文件存放目录
dir /tmp/6379
# 绑定地址
bind 0.0.0.0
# 让redis后台运行
daemonize yes
# 注册的实例ip
replica-announce-ip 192.168.146.100
# 保护模式
protected-mode no
# 数据库数量
databases 1
# 日志
logfile /tmp/6379/run.log
- 将文件拷贝到每个目录下
# 进入/tmp目录
cd /tmp
# 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf
- 将每个目录下的第redis.conf中的6379改为所在目录一致
# 进入/tmp目录
cd /tmp
# 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf
- 启动
# 进入/tmp目录
cd /tmp
# 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf
# 查看启动状态
ps -ef | grep redis
# 关闭所有进程
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown
- 创建集群:上一步启动了redis,但这几个redis之间还未建立联系,以下命令要求redis版本大于等于5.0
redis-cli \
--cluster create \
--cluster-replicas 1 \
192.168.146.100:7001 \
192.168.146.100:7002 \
192.168.146.100:7003 \
192.168.146.100:8001 \
192.168.146.100:8002 \
192.168.146.100:8003
# 更多集群相关命令
redis-cli --cluster help
create host1:port1 ... hostN:portN
--cluster-replicas <arg>
check <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
info <host:port> or <host> <port> - separated by either colon or space
fix <host:port> or <host> <port> - separated by either colon or space
--cluster-search-multiple-owners
--cluster-fix-with-unreachable-masters
reshard <host:port> or <host> <port> - separated by either colon or space
--cluster-from <arg>
--cluster-to <arg>
--cluster-slots <arg>
--cluster-yes
--cluster-timeout <arg>
--cluster-pipeline <arg>
--cluster-replace
rebalance <host:port> or <host> <port> - separated by either colon or space
--cluster-weight <node1=w1...nodeN=wN>
--cluster-use-empty-masters
--cluster-timeout <arg>
--cluster-simulate
--cluster-pipeline <arg>
--cluster-threshold <arg>
--cluster-replace
add-node new_host:new_port existing_host:existing_port
--cluster-slave
--cluster-master-id <arg>
del-node host:port node_id
call host:port command arg arg .. arg
--cluster-only-masters
--cluster-only-replicas
set-timeout host:port milliseconds
import host:port
--cluster-from <arg>
--cluster-from-user <arg>
--cluster-from-pass <arg>
--cluster-from-askpass
--cluster-copy
--cluster-replace
backup host:port backup_directory
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
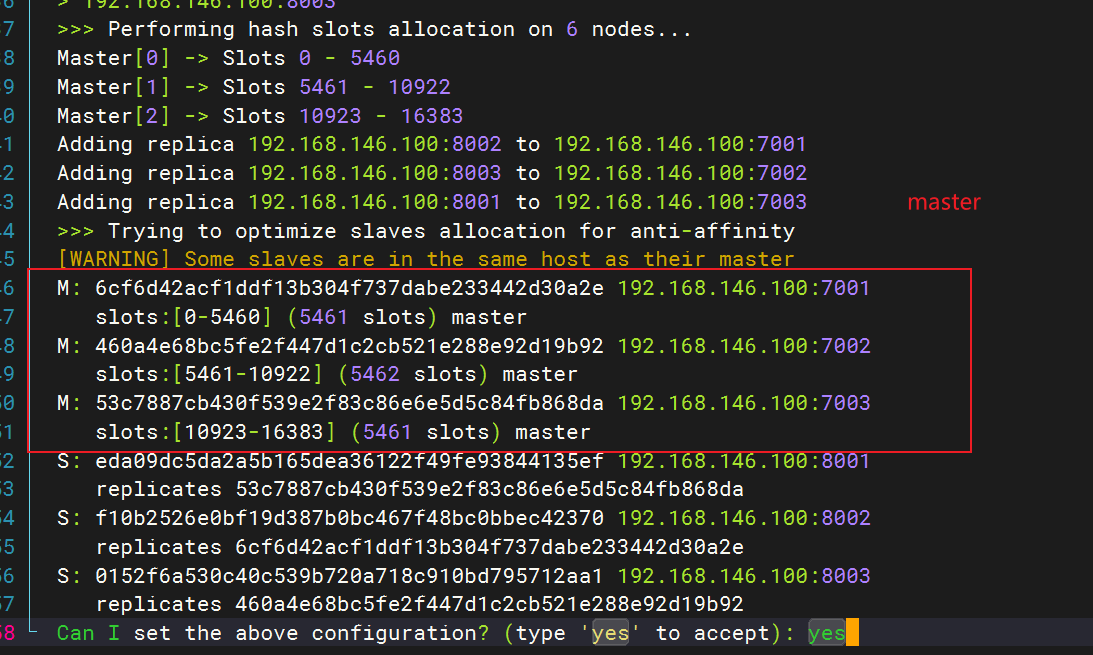
- 查看集群状态
redis-cli -p 7001 cluster nodes
- 命令行链接集群redis注意点
# 需要加上 -c 参数,否则进行写操作时会报错
redis-cli -c -p 7001
散列插槽
Redis会把每一个master节点映射到0~16383共16384个插槽(hash slot)上,查看集群信息时就能看到
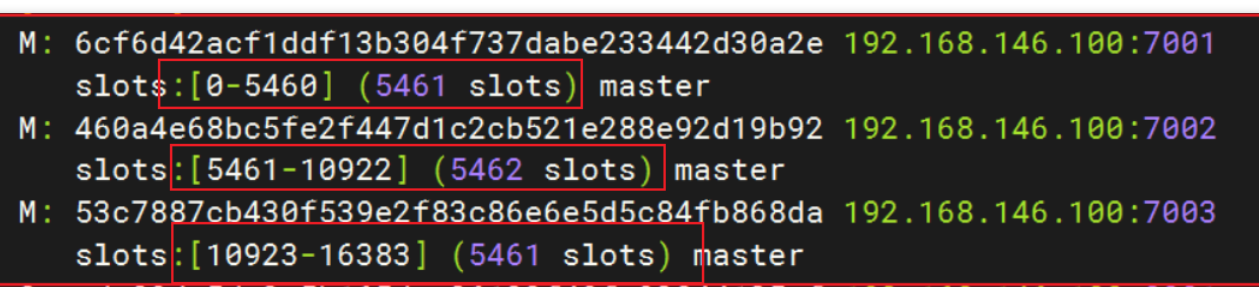
数据key不是与节点绑定,而是与插槽绑定。redis会根据key的有效部分计算插槽值,分两种情况:
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
好处:节点挂了,但插槽还在,将插槽分配给健康的节点,那数据就恢复了
如:key是num,那么就根据num计算;如果是{name}num,则根据name计算。计算方式是利用CRC16算法得到一个hash值,然后对16384取余,得到的结果就是slot值
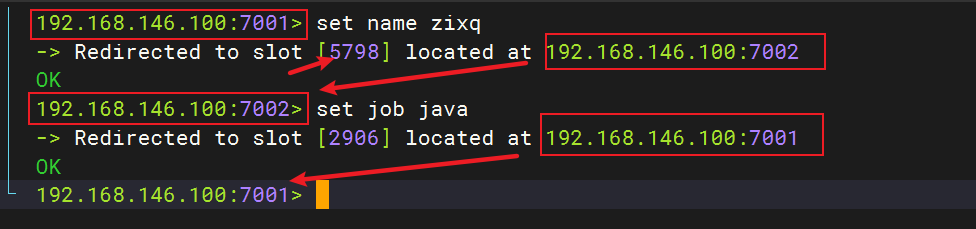
如上:在7001存入name,对name做hash运算,之后对16384取余,得到的5798就是name=zixq要存储的位置,而5798在7002节点中,所以跳入了7002节点;而 set job java 也是同样的道理
利用上述的原理可以做到:将同一类数据固定地保存在同一个Redis实例/节点(即:这一类数据使用相同的有效部分,如key都以{typeId}为前缀)
分片集群下的故障转移
分片集群下,虽然没有哨兵,但是也可以进行故障转移
-
自动故障转移:master挂了、选一个slave为主........,和前面玩过的主从一样
-
手动故障转移:后续新增的节点(此时是slave),性能比原有的节点(master)性能好,故而将新节点弄为master
# 在新增节点一方执行下列命令,就会让此新增节点与其master节点身份对调
cluster failover
failover命令可以指定三种模式:
- 缺省:默认的流程,如下图1~6歩(推荐使用)
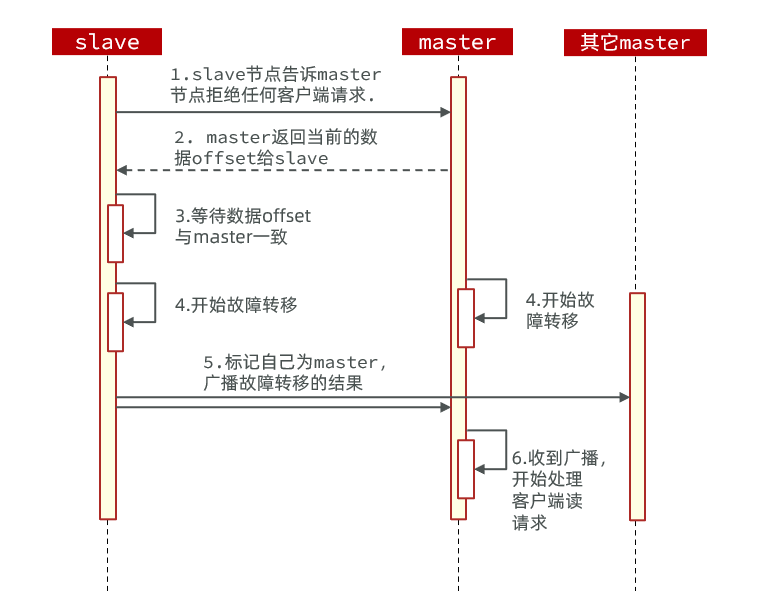
- force:省略了对offset的一致性校验
- takeover:直接执行第5歩,忽略数据一致性、忽略master状态和其它master的意见
RedisTemplate访问分片集群
RedisTemplate底层同样基于lettuce实现了分片集群的支持、所以和哨兵集群的RedisTemplate一样,区别就是YAML配置
- 依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- YAML配置分片集群
spring:
redis:
cluster:
nodes:
- 192.168.146.100:7001 # 和哨兵集群的区别:此集群没有哨兵,这里使用的是分片集群的每个节点的ip:port
- 192.168.146.100:7002
- 192.168.146.100:7003
- 192.168.146.100:8001
- 192.168.146.100:8002
- 192.168.146.100:8003
- 配置读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer clientConfigurationBuilderCustomizer(){
return clientConfigurationBuilder -> clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}
这个bean中配置的就是读写策略,包括四种:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
- 就可以在需要的地方正常使用RedisTemplate了,如前面玩的StringRedisTemplate
集群伴随的问题
集群虽然具备高可用特性,能实现自动故障恢复,但是如果使用不当,也会存在一些问题
- 集群完整性问题:在Redis的默认配置中,如果发现任意一个插槽不可用,则整个集群都会停止对外服务,即就算有一个slot不能用了,那么集群也会不可用,像什么set、get......命令也用不了了,因此开发中,最重要的是可用性,因此修改 redis.conf文件中的内容
# 集群全覆盖 默认值是 yes,改为no即可
cluster-require-full-coverage no
- 集群带宽问题:集群节点之间会不断的互相Ping来确定集群中其它节点的状态。每次Ping携带的信息至少包括
- 插槽信息
- 集群状态信息
集群中节点越多,集群状态信息数据量也越大,10个节点的相关信息可能达到1kb,此时每次集群互通需要的带宽会非常高,这样会导致集群中大量的带宽都会被ping信息所占用,这是一个非常可怕的问题,所以我们需要去解决这样的问题
解决途径:
- 避免大集群,集群节点数不要太多,最好少于1000,如果业务庞大,则建立多个集群。
- 避免在单个物理机中运行太多Redis实例
- 配置合适的cluster-node-timeout值
-
lua和事务的问题:这两个都是为了保证原子性,这就要求执行的所有key都落在一个节点上,而集群则会破坏这一点,集群中无法保证lua和事务问题
-
数据倾斜问题:因为hash_tag(散列插槽中说的hash算的slot值)落在一个节点上,就导致大量数据都在一个redis节点中了
-
集群和主从选择问题:单体Redis(主从Redis+哨兵)已经能达到万级别的QPS,并且也具备很强的高可用特性。如果主从能满足业务需求的情况下,若非万不得已的情况下,尽量不搭建Redis集群
批处理
单机redis批处理:mxxx命令 与 Pipeline
Mxxx虽然可以批处理,但是却只能操作部分数据类型(String是mset、Hash是hmset、Set是sadd key member.......),因此如果有对复杂数据类型的批处理需要,建议使用Pipeline
注意点:mxxx命令可以保证原子性,一堆命令一起执行;而Pipeline是非原子性的,这是将一堆命令一起发给redis服务器,然后把这些命令放入服务器的一个队列中,最后慢慢执行而已,因此执行命令不一定是一起执行的
@Test
void testPipeline() {
// 创建管道 Pipeline 此对象基本上可以进行所有的redis操作,如:pipeline.set()、pipeline.hset().....
Pipeline pipeline = jedis.pipelined();
for (int i = 1; i <= 100000; i++) {
// 放入命令到管道
pipeline.set("test:key_" + i, "value_" + i);
if (i % 1000 == 0) {
// 每放入1000条命令,批量执行
pipeline.sync();
}
}
}
集群redis批处理
MSET或Pipeline这样的批处理需要在一次请求中携带多条命令,而此时如果Redis是一个集群,那批处理命令的多个key必须落在一个插槽中,否则就会导致执行失败。这样的要求很难实现,因为我们在批处理时,可能一次要插入很多条数据,这些数据很有可能不会都落在相同的节点上,这就会导致报错了

解决方式:hash_tag就是前面散列插槽中说的算插槽的hash值

在jedis中,对于集群下的批处理并没有解决,因此一旦使用jedis来操作redis,那么就需要我们自己来实现集群的批处理逻辑,一般选择串行slot或并行slot即可
而在Spring中是解决了集群下的批处理问题的
@Test
void testMSetInCluster() {
Map<String, String> map = new HashMap<>(4);
map.put("name", "Rose");
map.put("age", "21");
map.put("sex", "Female");
stringRedisTemplate.opsForValue().multiSet(map);
List<String> strings = stringRedisTemplate
.opsForValue()
.multiGet(Arrays.asList("name", "age", "sex"));
strings.forEach(System.out::println);
}
原理:使用jedis操作时,要编写集群的批处理逻辑可以借鉴
在RedisAdvancedClusterAsyncCommandsImpl 类中
首先根据slotHash算出来一个partitioned的map,map中的key就是slot,而他的value就是对应的对应相同slot的key对应的数据
通过 RedisFuture<String> mset = super.mset(op); 进行异步的消息发送
public class RedisAdvancedClusterAsyncCommandsImpl {
@Override
public RedisFuture<String> mset(Map<K, V> map) {
// 算key的slot值,然后key相同的分在一组
Map<Integer, List<K>> partitioned = SlotHash.partition(codec, map.keySet());
if (partitioned.size() < 2) {
return super.mset(map);
}
Map<Integer, RedisFuture<String>> executions = new HashMap<>();
for (Map.Entry<Integer, List<K>> entry : partitioned.entrySet()) {
Map<K, V> op = new HashMap<>();
entry.getValue().forEach(k -> op.put(k, map.get(k)));
// 异步发送:即mset()中的逻辑就是并行slot方式
RedisFuture<String> mset = super.mset(op);
executions.put(entry.getKey(), mset);
}
return MultiNodeExecution.firstOfAsync(executions);
}
}
慢查询
Redis执行时耗时超过某个阈值的命令,称为慢查询
慢查询的危害:由于Redis是单线程的,所以当客户端发出指令后,他们都会进入到redis底层的queue来执行,如果此时有一些慢查询的数据,就会导致大量请求阻塞,从而引起报错,所以我们需要解决慢查询问题

慢查询的阈值可以通过配置指定:
slowlog-log-slower-than:慢查询阈值,单位是微秒。默认是10000,建议1000
慢查询会被放入慢查询日志中,日志的长度有上限,可以通过配置指定:
slowlog-max-len:慢查询日志(本质是一个队列)的长度。默认是128,建议1000

- 临时配置
config set slowlog-log-slower-than 1000 # 临时配置:慢查询阈值,重启redis则失效
config set slowlog-max-len 1000 # 慢查询日志长度
- 永久配置:在redis.conf文件中添加相应内容即可
# 慢查询阈值
slowlog-log-slower-than 1000
# 慢查询日志长度
slowlog-max-len 1000
查看慢查询
- 命令方式
slowlog len # 查询慢查询日志长度
slowlog get [n] # 读取n条慢查询日志
slowlog reset # 清空慢查询列表

- 客户端工具:不同客户端操作不一样

内存配置
当Redis内存不足时,可能导致Key频繁被删除、响应时间变长、QPS不稳定等问题。当内存使用率达到90%以上时就需要我们警惕,并快速定位到内存占用的原因
redis中的内存划分:
| 内存占用 | 说明 | 备注 |
|---|---|---|
| 数据内存 | 是Redis最主要的部分,存储Redis的键值信息。主要问题是BigKey问题、内存碎片问题 | 内存碎片问题:Redis底层分配并不是这个key有多大,他就会分配多大,而是有他自己的分配策略,比如8,16,20等等,假定当前key只需要10个字节,此时分配8肯定不够,那么他就会分配16个字节,多出来的6个字节就不能被使用,这就是我们常说的 碎片问题。这种一般重启redis就解决了 |
| 进程内存 | Redis主进程本身运⾏肯定需要占⽤内存,如代码、常量池等等;这部分内存⼤约⼏兆,在⼤多数⽣产环境中与Redis数据占⽤的内存相⽐可以忽略 | 这部分内存一般都可以忽略不计 |
| 缓冲区内存 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,不当使用BigKey,可能导致内存溢出 | 一般包括客户端缓冲区、AOF缓冲区、复制缓冲区等。客户端缓冲区又包括输入缓冲区和输出缓冲区两种。这部分内存占用波动较大,所以这片内存也是需要重点分析的内存问题 |
查看内存情况
- 查看内存分配的情况
# 要查看info自己看哪些东西,直接输入 info 回车即可看到
info memory
# 示例
127.0.0.1:7001> INFO memory
# Memory
used_memory:2353272
used_memory_human:2.24M
used_memory_rss:9281536
used_memory_rss_human:8.85M
used_memory_peak:2508864
used_memory_peak_human:2.39M
used_memory_peak_perc:93.80%
used_memory_overhead:1775724
used_memory_startup:1576432
used_memory_dataset:577548
used_memory_dataset_perc:74.35%
allocator_allocated:2432096
allocator_active:2854912
allocator_resident:5439488
total_system_memory:1907740672
total_system_memory_human:1.78G
used_memory_lua:31744
used_memory_vm_eval:31744
used_memory_lua_human:31.00K
used_memory_scripts_eval:0
number_of_cached_scripts:0
number_of_functions:0
number_of_libraries:0
used_memory_vm_functions:32768
used_memory_vm_total:64512
used_memory_vm_total_human:63.00K
used_memory_functions:184
used_memory_scripts:184
used_memory_scripts_human:184B
maxmemory:0
maxmemory_human:0B
maxmemory_policy:noeviction
allocator_frag_ratio:1.17
allocator_frag_bytes:422816
allocator_rss_ratio:1.91
allocator_rss_bytes:2584576
rss_overhead_ratio:1.71
rss_overhead_bytes:3842048
mem_fragmentation_ratio:3.95
mem_fragmentation_bytes:6930528
mem_not_counted_for_evict:0
mem_replication_backlog:184540
mem_total_replication_buffers:184536
mem_clients_slaves:0
mem_clients_normal:3600
mem_cluster_links:10880
mem_aof_buffer:0
mem_allocator:jemalloc-5.2.1
active_defrag_running:0
lazyfree_pending_objects:0
lazyfreed_objects:0
- 查看key的主要占用情况
memory xxx
# 用法查询
127.0.0.1:7001> help MEMORY
MEMORY
summary: A container for memory diagnostics commands
since: 4.0.0
group: server
MEMORY DOCTOR
summary: Outputs memory problems report
since: 4.0.0
group: server
MEMORY HELP
summary: Show helpful text about the different subcommands
since: 4.0.0
group: server
MEMORY MALLOC-STATS
summary: Show allocator internal stats
since: 4.0.0
group: server
MEMORY PURGE
summary: Ask the allocator to release memory
since: 4.0.0
group: server
MEMORY STATS
summary: Show memory usage details
since: 4.0.0
group: server
MEMORY USAGE key [SAMPLES count]
summary: Estimate the memory usage of a key
since: 4.0.0
group: server
MEMORY STATS查询结果解读
127.0.0.1:7001> MEMORY STATS
1) "peak.allocated" # redis进程自启动以来消耗内存的峰值
2) (integer) 2508864
3) "total.allocated" # redis使用其分配器分配的总字节数,即当前的总内存使用量
4) (integer) 2353152
5) "startup.allocated" # redis启动时消耗的初始内存量,即redis启动时申请的内存大小
6) (integer) 1576432
7) "replication.backlog" # 复制积压缓存区的大小
8) (integer) 184540
9) "clients.slaves" # 主从复制中所有从节点的读写缓冲区大小
10) (integer) 0
11) "clients.normal" # 除从节点外,所有其他客户端的读写缓冲区大小
12) (integer) 3600
13) "cluster.links" #
14) (integer) 10880
15) "aof.buffer" # AOF持久化使用的缓存和AOF重写时产生的缓存
16) (integer) 0
17) "lua.caches" #
18) (integer) 0
19) "functions.caches" #
20) (integer) 184
21) "db.0" # 业务数据库的数量
22) 1) "overhead.hashtable.main" # 当前数据库的hash链表开销内存总和,即元数据内存
2) (integer) 72
3) "overhead.hashtable.expires" # 用于存储key的过期时间所消耗的内存
4) (integer) 0
5) "overhead.hashtable.slot-to-keys" #
6) (integer) 16
23) "overhead.total" # 数值 = startup.allocated + replication.backlog + clients.slaves + clients.normal + aof.buffer + db.X
24) (integer) 1775724
25) "keys.count" # 当前redis实例的key总数
26) (integer) 1
27) "keys.bytes-per-key" # 当前redis实例每个key的平均大小。计算公式:(total.allocated - startup.allocated) / keys.count
28) (integer) 776720
29) "dataset.bytes" # 纯业务数据占用的内存大小
30) (integer) 577428
31) "dataset.percentage" # 纯业务数据占用的第内存比例。计算公式:dataset.bytes * 100 / (total.allocated - startup.allocated)
32) "74.341850280761719"
33) "peak.percentage" # 当前总内存与历史峰值的比例。计算公式:total.allocated * 100 / peak.allocated
34) "93.793525695800781"
35) "allocator.allocated" #
36) (integer) 2459024
37) "allocator.active" #
38) (integer) 2891776
39) "allocator.resident" #
40) (integer) 5476352
41) "allocator-fragmentation.ratio" #
42) "1.1759852170944214"
43) "allocator-fragmentation.bytes" #
44) (integer) 432752
45) "allocator-rss.ratio" #
46) "1.8937677145004272"
47) "allocator-rss.bytes" #
48) (integer) 2584576
49) "rss-overhead.ratio" #
50) "1.6851159334182739"
51) "rss-overhead.bytes" #
52) (integer) 3751936
53) "fragmentation" # 内存的碎片率
54) "3.9458441734313965"
55) "fragmentation.bytes" # 内存碎片所占字节大小
56) (integer) 6889552
- 客户端链接工具查看:不同redis客户端链接工具不一样,操作不一样
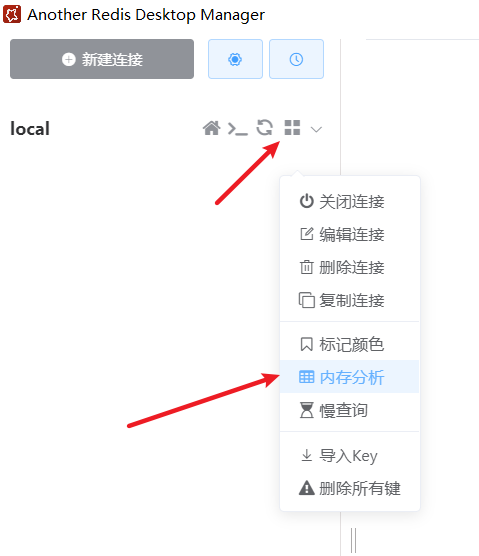
解决内存问题
由前面铺垫得知:内存缓冲区常见的有三种
- 复制缓冲区:主从复制的repl_backlog_buf,如果太小可能导致频繁的全量复制,影响性能。通过replbacklog-size来设置,默认1mb
- AOF缓冲区:AOF刷盘之前的缓存区域,AOF执行rewrite的缓冲区。无法设置容量上限
- 客户端缓冲区:分为输入缓冲区和输出缓冲区,输入缓冲区最大1G且不能设置。输出缓冲区可以设置
其他的基本上可以忽略,最关键的其实是客户端缓冲区的问题:
客户端缓冲区:指的就是我们发送命令时,客户端用来缓存命令的一个缓冲区,也就是我们向redis输入数据的输入端缓冲区和redis向客户端返回数据的响应缓存区
输入缓冲区最大1G且不能设置,所以这一块我们根本不用担心,如果超过了这个空间,redis会直接断开,因为本来此时此刻就代表着redis处理不过来了,我们需要担心的就是输出端缓冲区

我们在使用redis过程中,处理大量的big value,那么会导致我们的输出结果过多,如果输出缓存区过大,会导致redis直接断开,而默认配置的情况下, 其实它是没有大小的,这就比较坑了,内存可能一下子被占满,会直接导致咱们的redis断开,所以解决方案有两个
- 设置一个大小
- 增加我们带宽的大小,避免我们出现大量数据从而直接超过了redis的承受能力
原理篇
涉及的Redis源码采用的版本为redis-6.2.6
Redis数据结构:SDS
Redis是C语言实现的,但C语言本身的字符串有缺陷,因此Redis就自己弄了一个字符串SDS(Simple Dynamic String 简单动态字符串)
C语言本身的字符串缺陷如下:
- 二级制不安全
C 语⾔的字符串其实就是⼀个字符数组,即数组中每个元素是字符串中的⼀个字符

奇为什么最后⼀个字符是“\0”?
在 C 语⾔⾥,对字符串操作时,char * 指针只是指向字符数组的起始位置,⽽字符数组的结尾位置就⽤“\0”表示,意思是指字符串的结束
所以,C 语⾔标准库中的字符串操作函数就通过判断字符是不是 “\0” 来决定要不要停⽌操作,如果当前字符不是 “\0” ,说明字符串还没结束,可以继续操作,如果当前字符是 “\0” 是则说明字符串结束了,就要停⽌操作
因此,C 语⾔字符串⽤ “\0” 字符作为结尾标记有个缺陷。假设有个字符串中有个 “\0” 字符,这时在操作这个字符串时就会提早结束
故C语言字符串缺陷:字符串⾥⾯不能含有 “\0” 字符,否则最先被程序读⼊的 “\0” 字符将被误认为是字符串结尾,这个限制使得 C 语⾔的字符串只能保存⽂本数据,不能保存像图⽚、⾳频、视频⽂化这样的⼆进制数据;同时C 语⾔获取字符串⻓度的时间复杂度是 O(N)
- 字符串操作函数不⾼效且不安全(可能导致发⽣缓冲区溢出)
举个例⼦,strcat 函数是可以将两个字符串拼接在⼀起
// 将 src 字符串拼接到 dest 字符串后⾯
char *strcat(char *dest, const char* src);
strcat 函数和 strlen 函数类似,时间复杂度也很⾼,也都需要先通过遍历字符串才能得到⽬标字符串的末尾。对于 strcat 函数来说,还要再遍历源字符串才能完成追加,对字符串的操作效率不⾼
C 语⾔的字符串是不会记录⾃身的缓冲区⼤⼩的,所以 strcat 函数假定程序员在执⾏这个函数时,已经为dest 分配了⾜够多的内存,可以容纳 src 字符串中的所有内容,⽽⼀旦这个假定不成⽴,就会发⽣缓冲区溢出将可能会造成程序运⾏终⽌
SDS 结构体
Redis源码:官网下载redis x.x.x.tar.gz,然后解压,src目录下即为源码所在
Redis中SDS是一个结构体,源码如下:

-
len,记录了字符串⻓度。这样获取字符串⻓度的时候,只需要返回这个成员变量值就⾏,时间复杂度只需要 O(1)
-
alloc,分配给字符数组的空间⻓度。这样在修改字符串的时候,可以通过 alloc - len 计算出剩余的空间⼤⼩,可以⽤来判断空间是否满⾜修改需求,如果不满⾜的话,就会⾃动将 SDS 的空间扩展⾄执⾏修改所需的⼤⼩,然后才执⾏实际的修改操作,所以使⽤ SDS 既不需要⼿动修改 SDS 的空间⼤⼩,也不会出现前⾯所说的缓冲区溢出的问题。
-
flags,⽤来表示不同类型的 SDS。⼀共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64
-
buf[],字符数组,⽤来保存实际数据。不仅可以保存字符串,也可以保存⼆进制数据
- 解决C语言原来字符串效率不高问题
Redis 的 SDS 结构因为加⼊了 len 成员变量,那么获取字符串⻓度的时候,直接返回这个成员变量的值就⾏,所以复杂度只有 O(1)
- 解决二进制不安全问题
SDS 不需要⽤ “\0” 字符来标识字符串结尾了,⽽是有个专⻔的 len 成员变量来记录⻓度,所以可存储包含 “\0” 的数据。但是 SDS 为了兼容部分 C 语⾔标准库的函数, SDS 字符串结尾还是会加上 “\0” 字符
因此, SDS 的 API 都是以处理⼆进制的⽅式来处理 SDS 存放在 buf[] ⾥的数据,程序不会对其中的数据做任何限制,数据写⼊的时候时什么样的,它被读取时就是什么样的
通过使⽤⼆进制安全的 SDS,⽽不是 C 字符串,使得 Redis 不仅可以保存⽂本数据,也可以保存任意格式的⼆进制数据
- 解决缓冲区可能溢出问题
Redis 的 SDS 结构⾥引⼊了 alloc 和 len 成员变量,这样 SDS API 通过 alloc - len 计算,可以算出剩余可⽤的空间⼤⼩,这样在对字符串做修改操作的时候,就可以由程序内部判断缓冲区⼤⼩是否⾜够⽤
⽽且,当判断出缓冲区⼤⼩不够⽤时,Redis 会⾃动将扩⼤ SDS 的空间⼤⼩,扩容方式如下:
- 若新字符串小于1M,则新空间为扩展后字符串长度的两倍 +1
PS:+ 1的原因是“\0”字符
- 若新字符串大于1M,则新空间为扩展后字符串长度 +1M +1。称为内存预分配
PS:内存预分配好处,下次在操作 SDS 时,如果 SDS 空间够的话,API 就会直接使⽤「未使⽤空间」,⽽⽆须执⾏内存分配,有效的减少内存分配次数
- 节省内存空间
SDS 结构中有个 flags 成员变量,表示的是 SDS 类型
Redos ⼀共设计了 5 种类型,分别是 sdshdr5、sdshdr8、sdshdr16、sdshdr32 和 sdshdr64
这 5 种类型的主要区别就在于,它们数据结构中的 len 和 alloc 成员变量的数据类型不同
如 sdshdr16 和 sdshdr32 这两个类型,它们的定义分别如下:
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len;
uint16_t alloc;
unsigned char flags;
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len;
uint32_t alloc;
unsigned char flags;
char buf[];
};
可以看到:
-
sdshdr16 类型的 len 和 alloc 的数据类型都是 uint16_t,表示字符数组⻓度和分配空间⼤⼩不能超过2 的 16 次⽅
-
sdshdr32 则都是 uint32_t,表示表示字符数组⻓度和分配空间⼤⼩不能超过 2 的 32 次⽅
之所以 SDS 设计不同类型的结构体,是为了能灵活保存不同⼤⼩的字符串,从⽽有效节省内存空间。如,在保存⼩字符串时,结构头占⽤空间也⽐较少
除了设计不同类型的结构体,Redis 在编程上还使⽤了专⻔的编译优化来节省内存空间,即在 struct 声明了 __attribute__ ((packed)) ,它的作⽤是:告诉编译器取消结构体在编译过程中的优化对⻬,按照实际占⽤字节数进⾏对⻬
⽐如,sdshdr16 类型的 SDS,默认情况下,编译器会按照 16 字节对⻬的⽅式给变量分配内存,这意味着,即使⼀个变量的⼤⼩不到 16 个字节,编译器也会给它分配 16 个字节
举个例⼦,假设下⾯这个结构体,它有两个成员变量,类型分别是 char 和 int,如下所示:
#include <stdio.h>
struct test1 {
char a;
int b;
} test1;
int main() {
printf("%lu\n", sizeof(test1));
return 0;
}
默认情况下,这个结构体⼤⼩计算出来就会是 8
这是因为默认情况下,编译器是使⽤「字节对⻬」的⽅式分配内存,虽然 char 类型只占⼀个字节,但是由于成员变量⾥有 int 类型,它占⽤了 4 个字节,所以在成员变量为 char 类型分配内存时,会分配 4 个字节,其中这多余的 3 个字节是为了字节对⻬⽽分配的,相当于有 3 个字节被浪费掉了。
如果不想编译器使⽤字节对⻬的⽅式进⾏分配内存,可以采⽤了 __attribute__ ((packed)) 属性定义结构体,这样⼀来,结构体实际占⽤多少内存空间,编译器就分配多少空间
Redis数据结构:intset
IntSet是Redis中set集合的一种实现方式,基于整数数组来实现,并且如下特征:
- Redis会确保Intset中的元素唯一、有序
- 具备类型升级机制,可以节省内存空间
- 底层采用二分查找方式来查询
Redis中intset的结构体源码如下:

其中的encoding包含三种模式,表示存储的整数大小不同:

为了方便查找,Redis会将intset中所有的整数按照升序依次保存在contents数组中,结构如图:

现在,数组中每个数字都在int16_t的范围内,因此采用的编码方式是INTSET_ENC_INT16,每部分占用的字节大小为:
- encoding:4字节
- length:4字节
- contents:2字节 * 3 = 6字节

假如,现在向其中添加一个数字:50000,这个数字超出了int16_t的范围,intset会自动升级编码方式到合适的大小
以当前案例来说流程如下:
- 升级编码为INTSET_ENC_INT32, 每个整数占4字节,并按照新的编码方式及元素个数扩容数组
- 倒序依次将数组中的元素拷贝到扩容后的正确位置。PS:倒序保证数据不乱
- 将待添加的元素放入数组末尾
- 最后,将inset的encoding属性改为INTSET_ENC_INT32,将length属性改为4

上述逻辑的源码如下:

- 问题:intset支持降级操作吗?
不⽀持降级操作,⼀旦对数组进⾏了升级,就会⼀直保持升级后的状态。如:前面已经从INTSET_ENC_INT16(2字节整数)升级到INTSET_ENC_INT32(4字节整数),就算删除50000元素,intset集合的类型也还是INTSET_ENC_INT32类型,不会降级为INTSET_ENC_INT16类型
Redis数据结构:Dict
Redis是一个键值型(Key-Value Pair)的数据库,我们可以根据键实现快速的增删改查。而键与值的映射关系正是通过Dict来实现的。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希节点(DictEntry)、字典(Dict)

哈希表(Dictht)与哈希节点(DictEntry)
- 哈希节点(DictEntry)

-
结构⾥不仅包含指向键和值的指针,还包含了指向下⼀个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对链接起来,以此来解决哈希冲突的问题,这就是链式哈希
-
dictEntry 结构⾥键值对中的值是⼀个「联合体 v」定义的,因此,键值对中的值可以是⼀个指向实际值的指针,或者是⼀个⽆符号的 64 位整数或有符号的 64 位整数或double 类的值。这么做的好处是可以节省内存空间,因为当「值」是整数或浮点数时,就可以将值的数据内嵌在 dictEntry
结构⾥,⽆需再⽤⼀个指针指向实际的值,从⽽节省了内存空间
- 哈希表(Dictht)
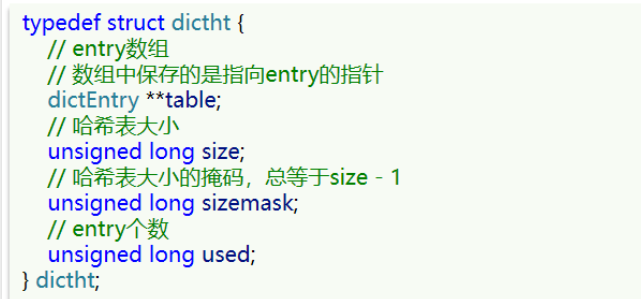
其中:
- 哈希表大小size初始值为4,而且其值总等于2^n
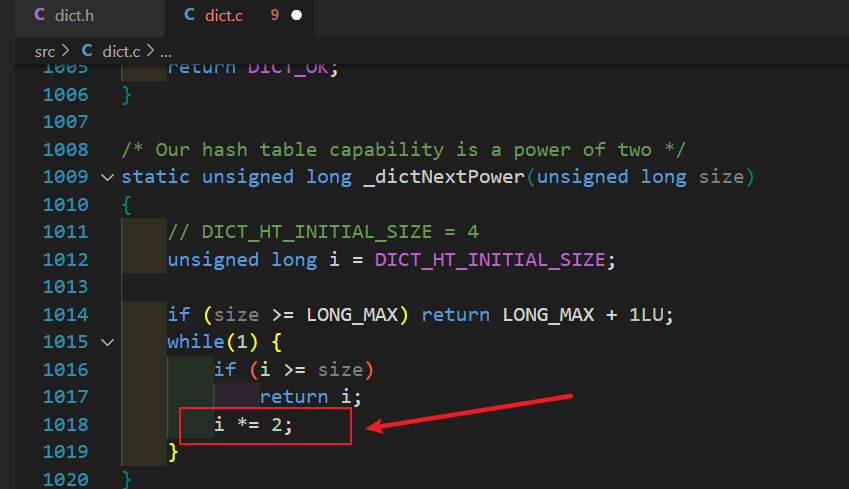
- 为什么sizemask = size -1?
因为size总等于2^n,所以size -1就为奇数,这样”key利用hash函数得到的哈希值h & sizemask”做与运算就正好得到的是size的低位,而这个低位值也正好和“哈希值 % 哈希表⼤⼩”取模一样
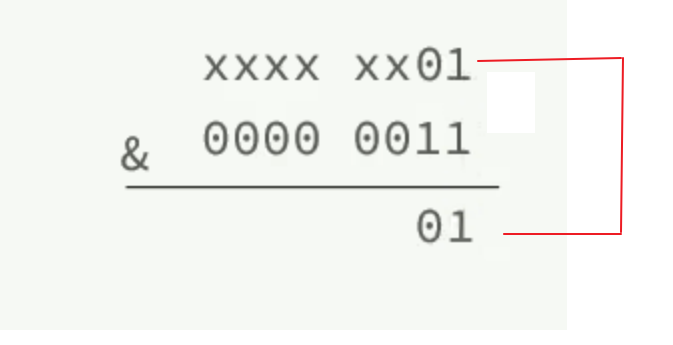
当我们向Dict添加键值对时,Redis首先根据key计算出hash值(h),然后利用 h & sizemask 来计算元素应该存储到数组中的哪个索引位置
假如存储k1=v1,假设k1的哈希值h =1,则1&3 =1,因此k1=v1要存储到数组角标1位置

假如此时又添加了一个k2=v2,那么就会添加到链表的队首

哈希冲突解决方式:链式哈希

就是每个哈希表节点都有⼀个 next 指针,⽤于指向下⼀个哈希表节点,因此多个哈希表节点可以⽤ next 指针构成⼀个单项链表,被分配到同⼀个哈希桶上的多个节点可以⽤这个单项链表连接起来
不过,链式哈希局限性也很明显,随着链表⻓度的增加,在查询这⼀位置上的数据的耗时就会增加,毕竟链表的查询的时间复杂度是 O(n),需要解决就得扩容
Dict的扩容与收缩
扩容
Dict中的HashTable就是数组结合单向链表的实现,当集合中元素较多时,必然导致哈希冲突增多,链表过长,则查询效率会大大降低
Dict在每次新增键值对时都会检查负载因子(LoadFactor = used/size,即负载因子=哈希表已保存节点数量 / 哈希表大小) ,满足以下两种情况时会触发哈希表扩容:
- 哈希表的 LoadFactor >= 1;并且服务器没有执行 bgsave或者 bgrewiteaof 等后台进程。也就是没有执⾏ RDB 快照或没有进⾏ AOF 重写的时候
- 哈希表的 LoadFactor > 5 ;此时说明哈希冲突⾮常严重了,不管有没有有在执⾏ RDB 快照或 AOF重写都会强制执行哈希扩容
源码逻辑如下:

收缩
Dict除了扩容以外,每次删除元素时,也会对负载因子做检查,当LoadFactor < 0.1 时,会做哈希表收缩
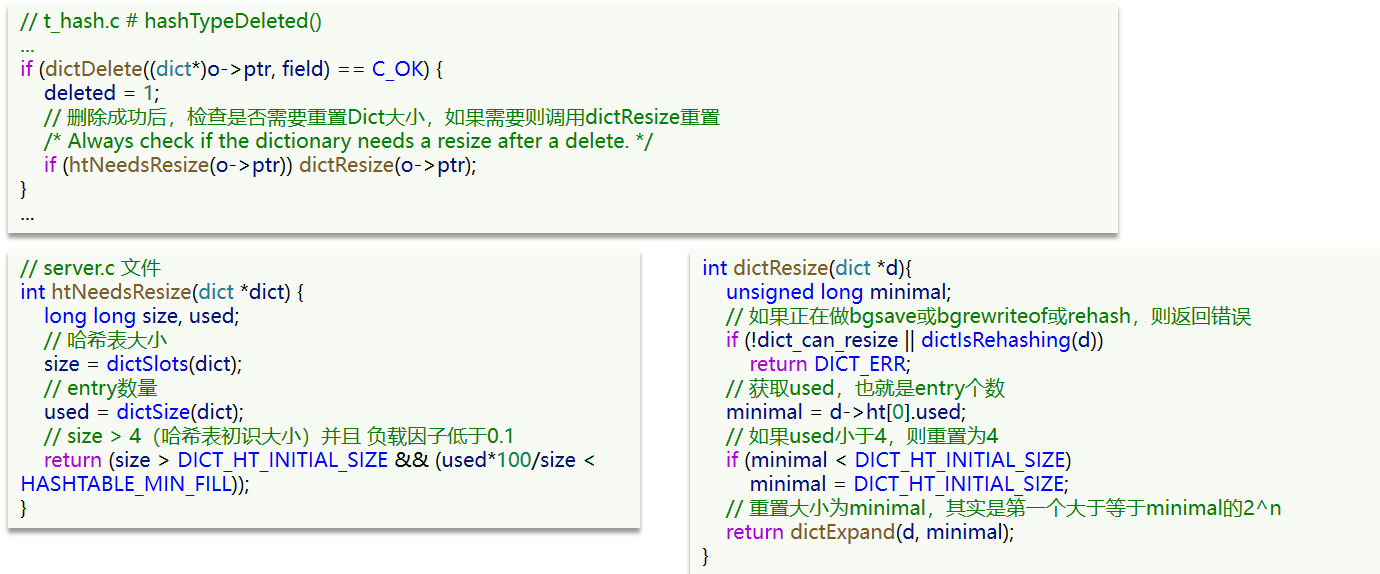
字典(Dict)

Redis 定义⼀个 dict 结构体,这个结构体⾥定义了两个哈希表(dictht ht[2])
在正常服务请求阶段,插⼊的数据,都会写⼊到「哈希表 1」,此时的「哈希表 2 」 并没有被分配空间(这个哈希表涉及到渐进式rehash)

Dict的渐进式rehash
rehash基本流程

不管是扩容还是收缩,必定会创建新的哈希表,导致哈希表的size和sizemask(sizemask = size -1)变化,而key的查询与sizemask有关(key通过hash函数计算得到哈希值h,数据存储的角标值 = h & sizemask)。因此必须对哈希表中的每一个key重新计算索引,插入新的哈希表,这个过程称为rehash
过程如下:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
- 按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
- 设置dict.rehashidx = 0,标示开始rehash
- 将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1]
- 将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
以上过程对于小数据影响小,但是对于大数据来说就有问题了,如果「哈希表 1 」的数据量⾮常⼤,那么在迁移⾄「哈希表 2 」的时候,因为会涉及⼤量的数据拷⻉,此时可能会对 Redis 造成阻塞,⽆法服务其他请求,因此就需要渐进式rehash
渐进式rehash
为了避免 rehash 在数据迁移过程中,因拷⻉数据的耗时,影响 Redis 性能的情况,所以 Redis 采⽤了渐进式 rehash,也就是将数据的迁移的⼯作不再是⼀次性迁移完成,⽽是分多次迁移
Dict的rehash并不是一次性完成的。试想一下,如果Dict中包含数百万的entry,要在一次rehash完成,极有可能导致主线程阻塞。所以Dict的rehash是分多次、渐进式的完成,因此称为渐进式rehash。过程如下:
- 计算新hash表的realeSize,值取决于当前要做的是扩容还是收缩:
- 如果是扩容,则新size为第一个大于等于dict.ht[0].used + 1的2^n
- 如果是收缩,则新size为第一个大于等于dict.ht[0].used的2^n (不得小于4)
-
按照新的realeSize申请内存空间,创建dictht,并赋值给dict.ht[1]
-
设置dict.rehashidx = 0,标示开始rehash
-
将dict.ht[0]中的每一个dictEntry都rehash到dict.ht[1] -
每次执行新增、删除、查询、修改操作时,除了执行对应操作之外,还会都检查一下dict.rehashidx是否大于 -1;若是则按顺序将dict.ht[0].table[rehashidx]的entry链表rehash到dict.ht[1],并且将rehashidx++,直至dict.ht[0]的所有资源都rehash到dict.ht[1]
PS:随着处理客户端发起的哈希表操作请求数量越多,最终在某个时间点,会把「哈希表 1 」的所有key-value 迁移到「哈希表 2」
-
将dict.ht[1]赋值给dict.ht[0],给dict.ht[1]初始化为空哈希表,释放原来的dict.ht[0]的内存
-
将rehashidx赋值为-1,代表rehash结束
-
在rehash过程中,新增操作,则直接写入ht[1],查询、修改和删除则会在dict.ht[0]和dict.ht[1]依次查找并执行。这样可以确保ht[0]的数据只减不增,随着rehash最终为空
上述流程动画图如下:

Redis数据结构:ZipList
压缩列表的最⼤特点,就是它被设计成⼀种内存紧凑型的数据结构,占⽤⼀块连续的内存空间,不仅可以利⽤ CPU 缓存,⽽且会针对不同⻓度的数据,进⾏相应编码,这种⽅法可以有效地节省内存开销
但是,压缩列表的缺陷也是有的:
- 不能保存过多的元素,否则查询效率就会降低;
- 新增或修改某个元素时,压缩列表占⽤的内存空间需要重新分配,甚⾄可能引发连锁更新的问题
压缩列表是 Redis 为了节约内存⽽开发的,它是由连续内存块组成的顺序型数据结构,有点类似于数组:

| 属性 | 类型 | 长度 | 用途 |
|---|---|---|---|
| zlbytes | uint32_t | 4 字节 | 记录整个压缩列表占⽤对内存字节数 |
| zltail | uint32_t | 4 字节 | 记录压缩列表尾节点距离压缩列表的起始地址有多少字节,通过这个偏移量,可以确定表尾节点的地址 |
| zllen | uint16_t | 2 字节 | 记录了压缩列表包含的节点数量。 最大值为UINT16_MAX (65534),如果超过这个值,此处会记录为65535,但节点的真实数量需要遍历整个压缩列表才能计算得出。 |
| entry | 列表节点 | 不定 | 压缩列表包含的各个节点,节点的长度由节点保存的内容决定。 |
| zlend | uint8_t | 1 字节 | 特殊值 0xFF (十进制 255 ),用于标记压缩列表的末端。 |

在压缩列表中,如果我们要查找定位第⼀个元素和最后⼀个元素,可以通过表头三个字段的⻓度直接定位,复杂度是 O(1)。⽽查找其他元素时,就没有这么⾼效了,只能逐个查找,此时的复杂度就是 O(N)了,因此压缩列表不适合保存过多的元素
ZipList的Entry结构
ZipList 中的Entry并不像普通链表那样记录前后节点的指针,因为记录两个指针要占用16个字节,浪费内存。而是采用了下面的结构:
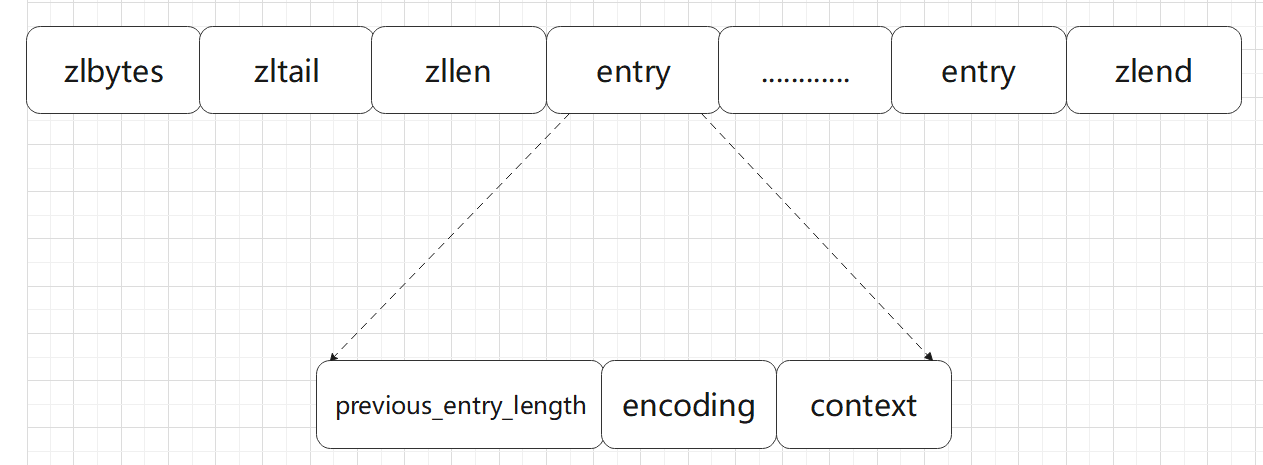
-
previous_entry_length:前一节点的长度,占1个或5个字节。PS:这个点涉及到“连锁更新”问题
- 如果前一节点的长度小于254字节,则采用1个字节来保存这个长度值
- 如果前一节点的长度大于254字节,则采用5个字节来保存这个长度值,第一个字节为0xfe,后四个字节才是真实长度数据
-
encoding:编码属性,记录content的数据类型(字符串还是整数)以及长度,占用1个、2个或5个字节
-
contents:负责保存节点的数据,可以是字符串或整数
ZipList中所有存储长度的数值均采用小端字节序,即低位字节在前,高位字节在后。例如:数值0x1234,采用小端字节序后实际存储值为:0x3412
PS:人的阅读习惯是从左到右,即大端字节序,机器读取数据是反着的,所以采用小端字节序,从而先处理低位,再处理高位
ZipList的Entry中的encoding编码
当我们往压缩列表中插⼊数据时,压缩列表就会根据数据是字符串还是整数,以及数据的⼤⼩,会使⽤不同空间⼤⼩的 previous_entry_length和 encoding 这两个元素保存的信息
previous_entry_length的规则上一节中已经提到了,接下来看看encoding
encoding 属性的空间⼤⼩跟数据是字符串还是整数,以及字符串的⻓度有关:
-
如果当前节点的数据是整数,则 encoding 会使⽤ 1 字节的空间进⾏编码。
-
如果当前节点的数据是字符串,根据字符串的⻓度⼤⼩,encoding 会使⽤ 1 字节/2字节/5字节的空间进⾏编码
- 当前节点的数据是整数
如果encoding是以“11”开始,则证明content是整数,且encoding固定只占用1个字节
| 编码 | 编码长度 | 整数类型 |
|---|---|---|
| 11000000 | 1 | int16_t(2 bytes) |
| 11010000 | 1 | int32_t(4 bytes) |
| 11100000 | 1 | int64_t(8 bytes) |
| 11110000 | 1 | 24位有符整数(3 bytes) |
| 11111110 | 1 | 8位有符整数(1 bytes) |
| 1111xxxx | 1 | 直接在xxxx位置保存数值,范围从0001~1101,减1后结果为实际值 |
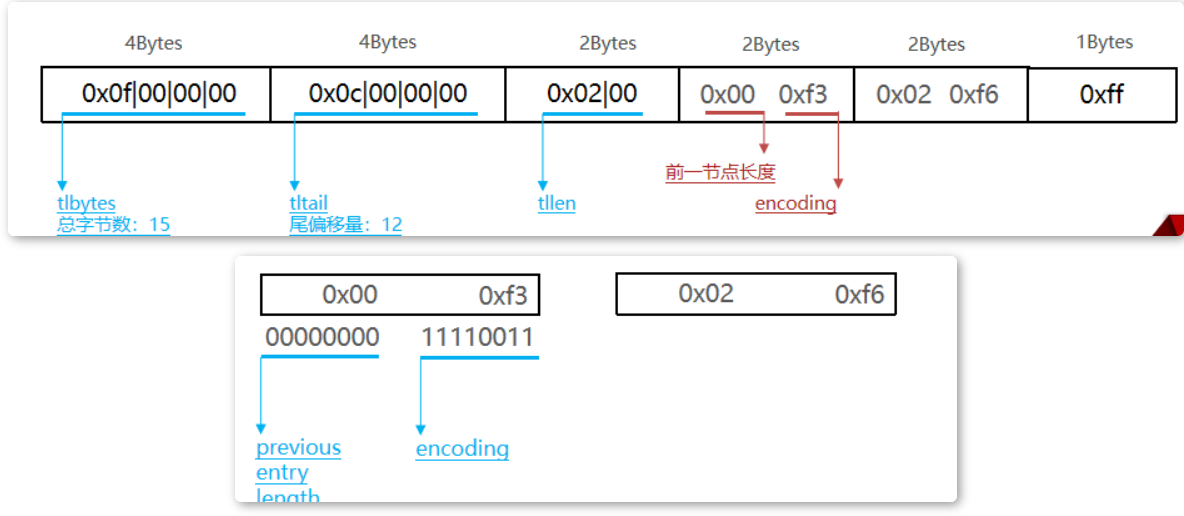
- 当前节点的数据是字符串
如果encoding是以“00”、“01”或者“10”开头(即整数是11开头,排除这种情况剩下的就是字符串),则证明content是字符串
| 编码 | 编码长度 | 字符串大小 |
|---|---|---|
| |00pppppp| | 1 bytes | <= 63 bytes |
| |01pppppp|qqqqqqqq| | 2 bytes | <= 16383 bytes |
| |10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| | 5 bytes | <= 4294967295 bytes |
如,要保存字符串:“ab”和 “bc”

ZipList的连锁更新问题
压缩列表节点的 previous_entry_length属性会根据前⼀个节点的⻓度进⾏不同的空间⼤⼩分配:
- 如前⼀个节点的⻓度⼩于 254 字节,那么 previous_entry_length属性需要⽤ 1 字节的空间来保存这个⻓度值;
- 如果前⼀个节点的⻓度⼤于等于 254 字节,那么 previous_entry_length属性需要⽤ 5 字节的空间来保存这个⻓度值
现在假设⼀个压缩列表中有多个连续的、⻓度在 250~253 之间的节点,如下图:

因为这些节点⻓度值⼩于 254 字节,所以 previous_entry_length属性需要⽤ 1 字节的空间来保存这个⻓度值
这时,如果将⼀个⻓度⼤于等于 254 字节的新节点加⼊到压缩列表的表头节点,即新节点将成为 e1 的前置节点,如下图:
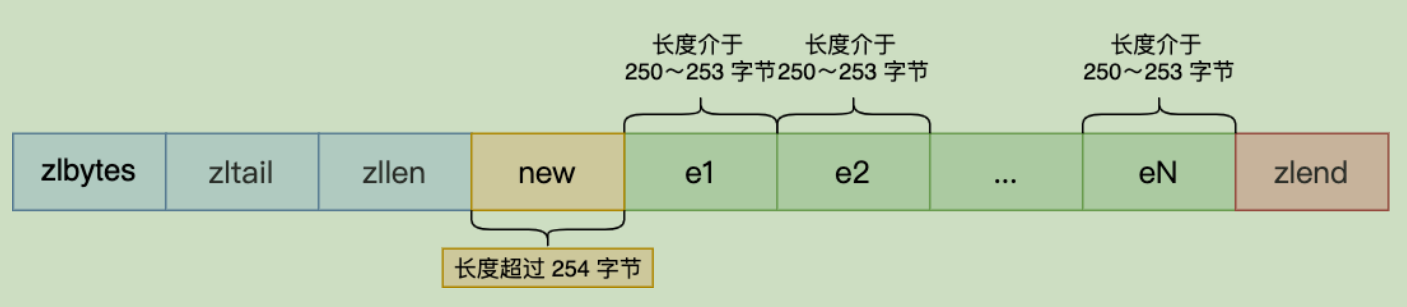
因为 e1 节点的 previous_entry_length属性只有 1 个字节⼤⼩,⽆法保存新节点的⻓度,此时就需要对压缩列表的空间重分配,并将 e1 节点的 previous_entry_length属性从原来的 1 字节⼤⼩扩展为 5 字节⼤⼩,那么多⽶诺牌的效应就此开始:
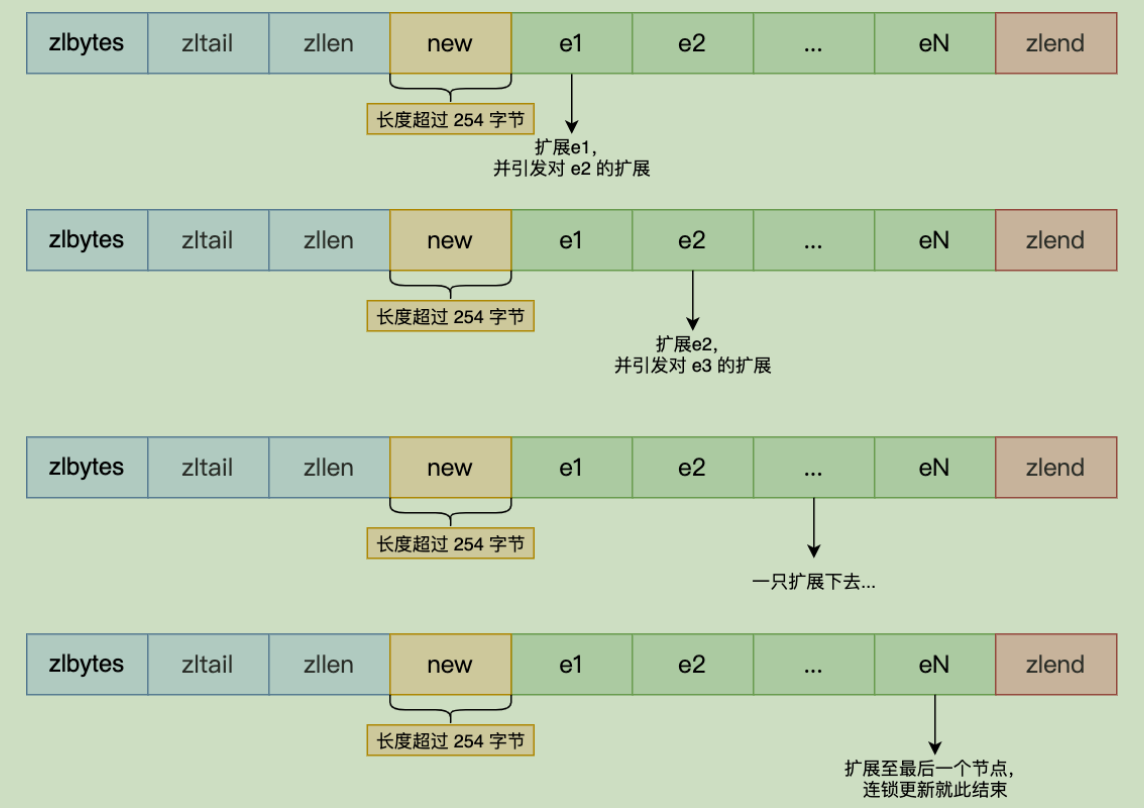
e1 原本的⻓度在 250~253 之间,因为刚才的扩展空间,此时 e1 的⻓度就⼤于等于 254 了,因此原本 e2保存 e1 的 previous_entry_length属性也必须从 1 字节扩展⾄ 5 字节⼤⼩
正如扩展 e1 引发了对 e2 扩展⼀样,扩展 e2 也会引发对 e3 的扩展,⽽扩展 e3 ⼜会引发对 e4 的扩展................⼀直持续到结尾
因此:ZipList这种特殊情况下产生的连续多次空间扩展操作称之为“连锁更新(Cascade Update)”。新增、删除都可能导致连锁更新的发生。就像多⽶诺牌的效应⼀样,第⼀张牌倒下了,推动了第⼆张牌倒下;第⼆张牌倒下,⼜推动了第三张牌倒下....
所以压缩列表(ZipList)就有了缺陷:如果保存的元素数量增加了,或是元素变⼤了,会导致内存重新分配,最糟糕的是会有「连锁更新」的问题
因此也就可以得出结论:压缩列表只会⽤于保存的节点数量不多的场景,只要节点数量⾜够⼩,即使发⽣连锁更新,也是能接受的
当然,Redis 针对压缩列表在设计上的不⾜,在后来的版本中,新增设计了两种数据结构:quicklist(Redis 3.2 引⼊) 和 listpack(Redis 5.0 引⼊)。这两种数据结构的设计⽬标,就是尽可能地保持压缩列表节省内存的优势,同时解决压缩列表的「连锁更新」的问题
Redis数据结构:QuickList
前面讲到虽然压缩列表是通过紧凑型的内存布局节省了内存开销,但是因为它的结构设计,如果保存的元素数量增加,或者元素变⼤了,压缩列表会有「连锁更新」的⻛险,⼀旦发⽣,会造成性能下降
QuickList解决办法:通过控制每个链表节点中的压缩列表的⼤⼩或者元素个数,来规避连锁更新的问题。因为压缩列表元素越少或越⼩,连锁更新带来的影响就越⼩,从⽽提供了更好的访问性能
问题1:ZipList虽然节省内存,但申请内存必须是连续空间,如果内存占用较多,申请内存效率很低。怎么办?
答:为了缓解这个问题,我们必须限制ZipList的长度和entry大小。
问题2:但是我们要存储大量数据,超出了ZipList最佳的上限该怎么办?
答:我们可以创建多个ZipList来分片存储数据。
问题3:数据拆分后比较分散,不方便管理和查找,这多个ZipList如何建立联系?
答:Redis在3.2版本引入了新的数据结构QuickList,它是一个双端链表,只不过链表中的每个节点都是一个ZipList。
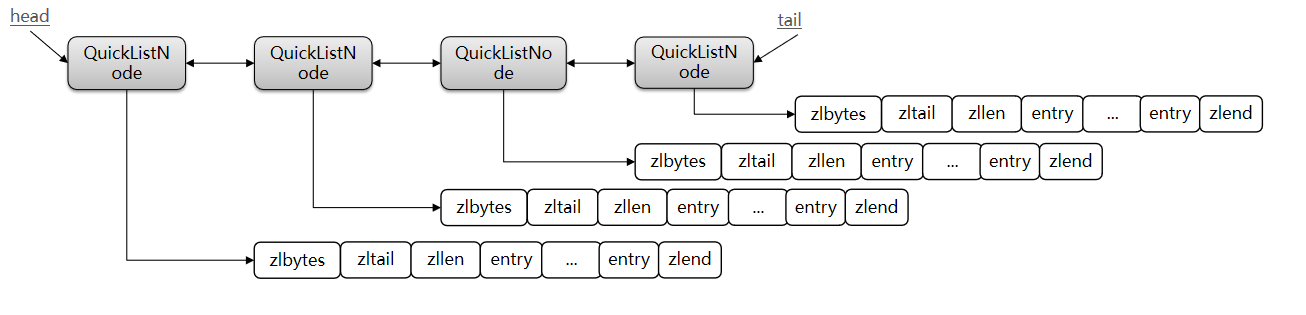
为了避免QuickList中的每个ZipList中entry过多,Redis提供了一个配置项:list-max-ziplist-size 来限制
- 如果值为正,则代表ZipList的允许的entry个数的最大值
- 如果值为负,则代表ZipList的最大内存大小,分5种情况:
| 值 | 含义 |
|---|---|
| -1 | 每个ZipList的内存占用不能超过4kb |
| -2 | 每个ZipList的内存占用不能超过8kb |
| -3 | 每个ZipList的内存占用不能超过16kb |
| -4 | 每个ZipList的内存占用不能超过32kb |
| -5 | 每个ZipList的内存占用不能超过64kb |
其默认值为 -2:

QuickList的和QuickListNode的结构源码:

方便理解,用个流程图来描述当前的这个结构:
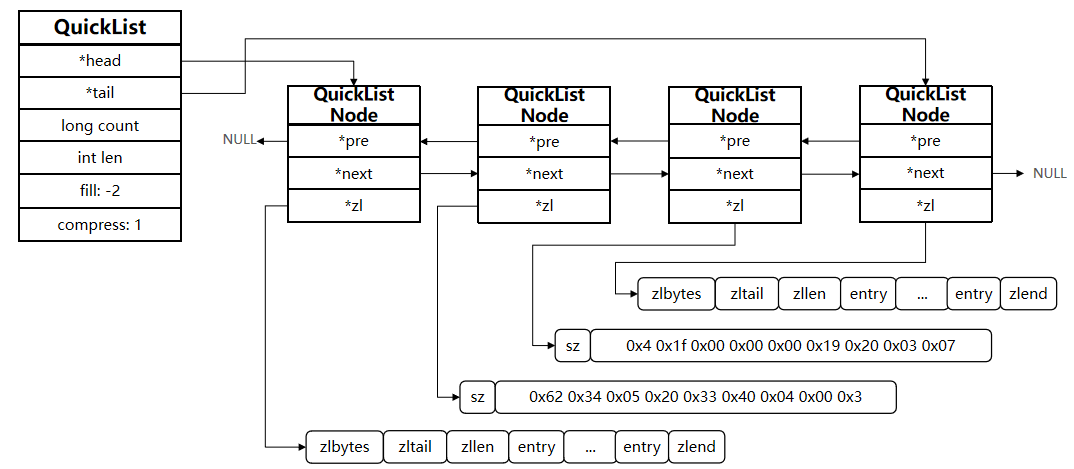
Redis数据结构:SkipList
SkipList(链表)在查找元素的时候,因为需要逐⼀查找,所以查询效率⾮常低,时间复杂度是O(N),于是就出现了跳表。跳表是在链表基础上改进过来的,实现了⼀种「多层」的有序链表,这样的好处是能快读定位数据
跳表与传统链表相比有几点差异:
- 元素按照升序排列存储
- 节点可能包含多个指针,指针跨度不同
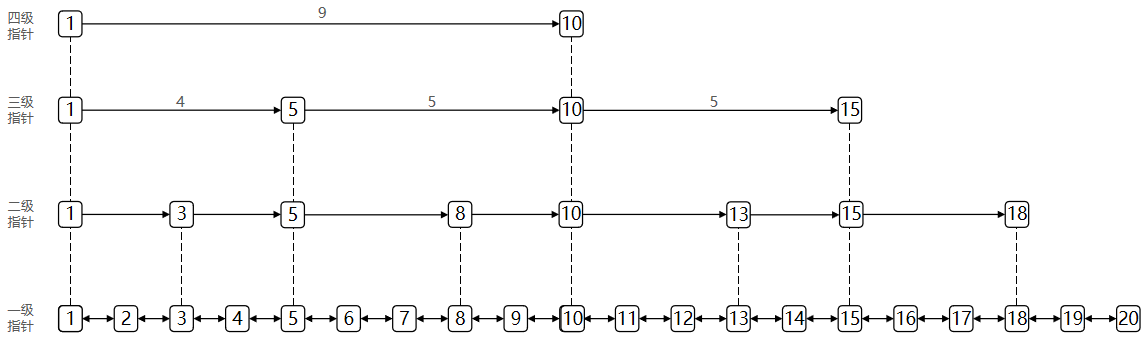
SkipList的源码与图形化示意如下:
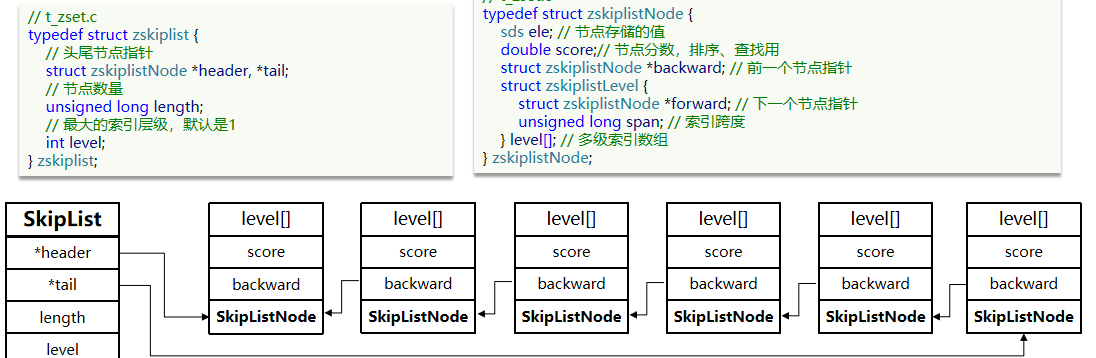
跳表是⼀个带有层级关系的链表,⽽且每⼀层级可以包含多个节点,每⼀个节点通过指针连接起来,实现这⼀特性就是靠跳表节点结构体中的zskiplistLevel 结构体类型的 level[] 数组
level 数组中的每⼀个元素代表跳表的⼀层,也就是由 zskiplistLevel 结构体表示,⽐如 leve[0] 就表示第⼀层,leve[1] 就表示第⼆层。zskiplistLevel 结构体⾥定义了「指向下⼀个跳表节点的指针」和「跨度」,跨度时⽤来记录两个节点之间的距离

跳表节点查询过程
查找⼀个跳表节点的过程时,跳表会从头节点的最⾼层开始,逐⼀遍历每⼀层。在遍历某⼀层的跳表节点时,会⽤跳表节点中的 SDS 类型的元素和元素的权重来进⾏判断,共有两个判断条件:
-
如果当前节点的权重「⼩于」要查找的权重时,跳表就会访问该层上的下⼀个节点。
-
如果当前节点的权重「等于」要查找的权重时,并且当前节点的 SDS 类型数据「⼩于」要查找的数据时,跳表就会访问该层上的下⼀个节点
-
如果上⾯两个条件都不满⾜,或者下⼀个节点为空时,跳表就会使⽤⽬前遍历到的节点的 level 数组⾥的下⼀层指针,然后沿着下⼀层指针继续查找,这就相当于跳到了下⼀层接着查找
如下图有个 3 层级的跳表:
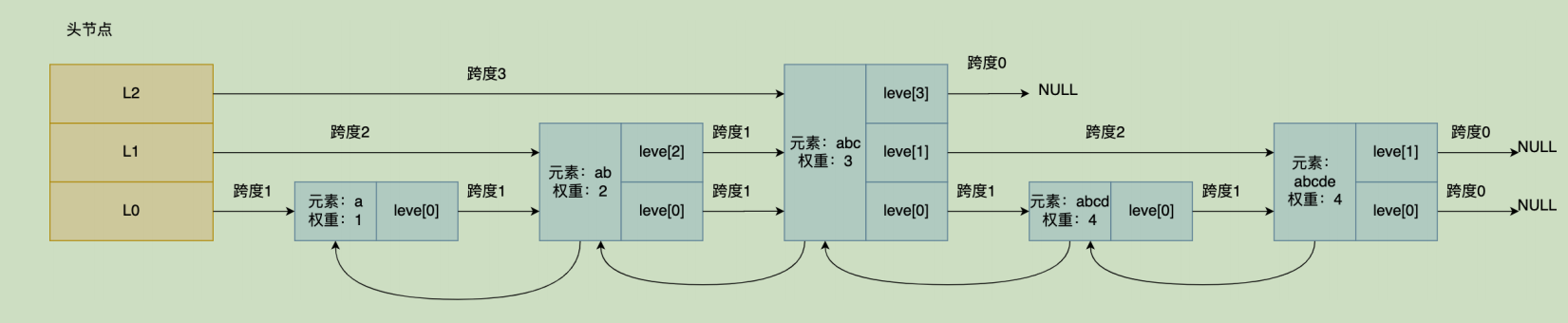
如果要查找「元素:abcd,权重:4」的节点,查找的过程是这样的:
- 先从头节点的最⾼层开始,L2 指向了「元素:abc,权重:3」节点,这个节点的权重⽐要查找节点的⼩,所以要访问该层上的下⼀个节点;
- 但是该层上的下⼀个节点是空节点,于是就会跳到「元素:abc,权重:3」节点的下⼀层去找,也就是 leve[1];
- 「元素:abc,权重:3」节点的 leve[1] 的下⼀个指针指向了「元素:abcde,权重:4」的节点,然后将其和要查找的节点⽐较。虽然「元素:abcde,权重:4」的节点的权重和要查找的权重相同,但是当前节点的 SDS 类型数据「⼤于」要查找的数据,所以会继续跳到「元素:abc,权重:3」节点的下⼀层去找,也就是 leve[0];
- 「元素:abc,权重:3」节点的 leve[0] 的下⼀个指针指向了「元素:abcd,权重:4」的节点,该节点正是要查找的节点,查询结束
跳表节点侧层数设置
跳表的相邻两层的节点数量最理想的⽐例是 2:1,查找复杂度可以降低到 O(logN)
下图的跳表就是,相邻两层的节点数量的⽐例是 2 : 1

- 怎样才能维持相邻两层的节点数量的⽐例为 2 : 1 ?
如果采⽤新增节点或者删除节点时,来调整跳表节点以维持⽐例的⽅法的话,会带来额外的开销
Redis 则采⽤⼀种巧妙的⽅法是,跳表在创建节点的时候,随机⽣成每个节点的层数,并没有严格维持相邻两层的节点数量⽐例为 2 : 1 的情况
具体的做法是:跳表在创建节点时候,会⽣成范围为[0-1]的⼀个随机数,如果这个随机数⼩于 0.25(相当于概率 25%),那么层数就增加 1 层,然后继续⽣成下⼀个随机数,直到随机数的结果⼤于 0.25 结束,最终确定该节点的层数
这样的做法,相当于每增加⼀层的概率不超过 25%,层数越⾼,概率越低,层⾼最⼤限制是 64层
Redis数据结构:RedisObject
Redis中的任意数据类型的键和值都会被封装为一个RedisObject,也叫做Redis对象
从Redis的使用者的角度来看,⼀个Redis节点包含多个database(非cluster模式下默认是16个,cluster模式下只能是1个),而一个database维护了从key space到object space的映射关系。这个映射关系的key是string类型,⽽value可以是多种数据类型,比如:string, list, hash、set、sorted set等。即key的类型固定是string,而value可能的类型是多个
⽽从Redis内部实现的⾓度来看,database内的这个映射关系是用⼀个dict来维护的。dict的key固定用⼀种数据结构来表达就够了,即SDS。而value则比较复杂,为了在同⼀个dict内能够存储不同类型的value,这就需要⼀个通⽤的数据结构,这个通用的数据结构就是robj,全名是redisObject
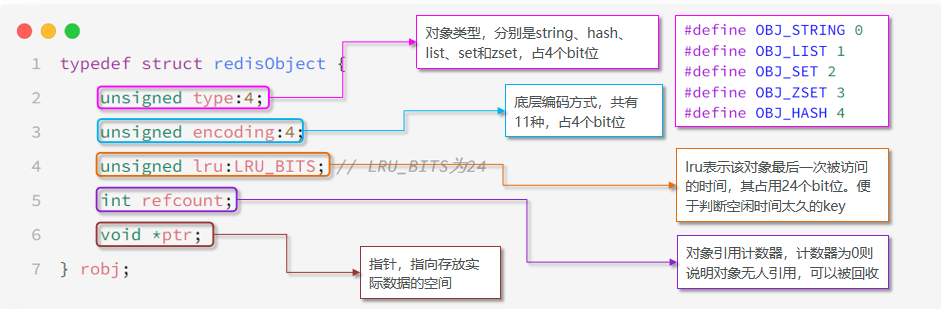
RedisObject中encoding编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式,共包含11种不同类型:
| 编号 | 编码方式 | 说明 |
|---|---|---|
| 0 | OBJ_ENCODING_RAW | raw编码动态字符串 |
| 1 | OBJ_ENCODING_INT | long类型的整数的字符串 |
| 2 | OBJ_ENCODING_HT | hash表(字典dict) |
| 3 | OBJ_ENCODING_ZIPMAP | 已废弃 |
| 4 | OBJ_ENCODING_LINKEDLIST | 双端链表 |
| 5 | OBJ_ENCODING_ZIPLIST | 压缩列表 |
| 6 | OBJ_ENCODING_INTSET | 整数集合 |
| 7 | OBJ_ENCODING_SKIPLIST | 跳表 |
| 8 | OBJ_ENCODING_EMBSTR | embstr的动态字符串 |
| 9 | OBJ_ENCODING_QUICKLIST | 快速列表 |
| 10 | OBJ_ENCODING_STREAM | Stream流 |
五种数据结构对应的编码方式
Redis中会根据存储的数据类型不同,选择不同的编码方式。每种数据类型使用的编码方式如下:
| 数据类型 | 编码方式 |
|---|---|
| OBJ_STRING | raw、embstr、int |
| OBJ_LIST | LinkedList和ZipList(3.2以前)、QuickList(3.2以后) |
| OBJ_SET | HT、intset |
| OBJ_ZSET | ZipList、HT、SkipList |
| OBJ_HASH | HT、ZipList |
Redis对象:String
String是Redis中最常见的数据存储类型,下图为SDS源码:

开发中,能用embstr编码就用,若不能则用int编码,raw编码最后考虑
- 基本编码方式是raw,基于简单动态字符串(SDS)实现,存储上限为512mb。验证方式:使用命令
object encoding key,下面说的另外情况也可通过这种方式验证
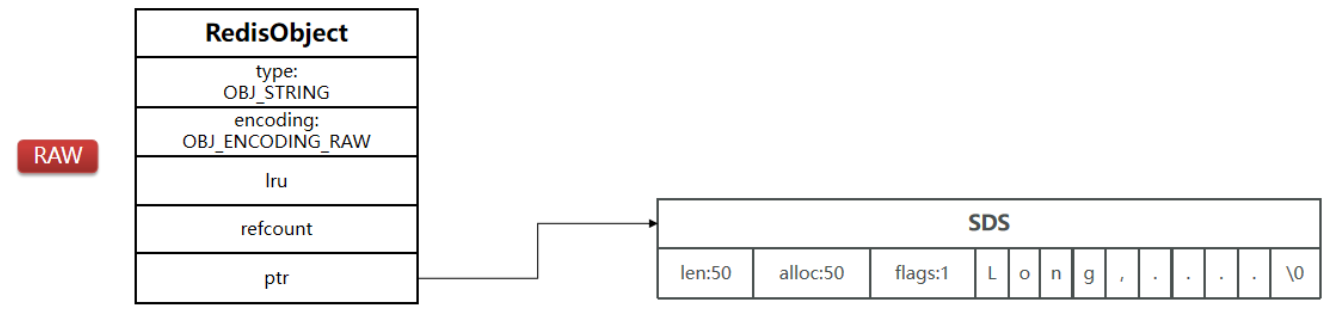
- 如果存储的SDS长度小于44字节,则会采用embstr编码,此时object head与SDS是一段连续空间。申请内存时只需要调用一次内存分配函数,效率更高

-
如果⼀个String类型的value值是数字,那么Redis内部会把它转成long类型来存储,从⽽减少内存的使用
-
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了

验证图:
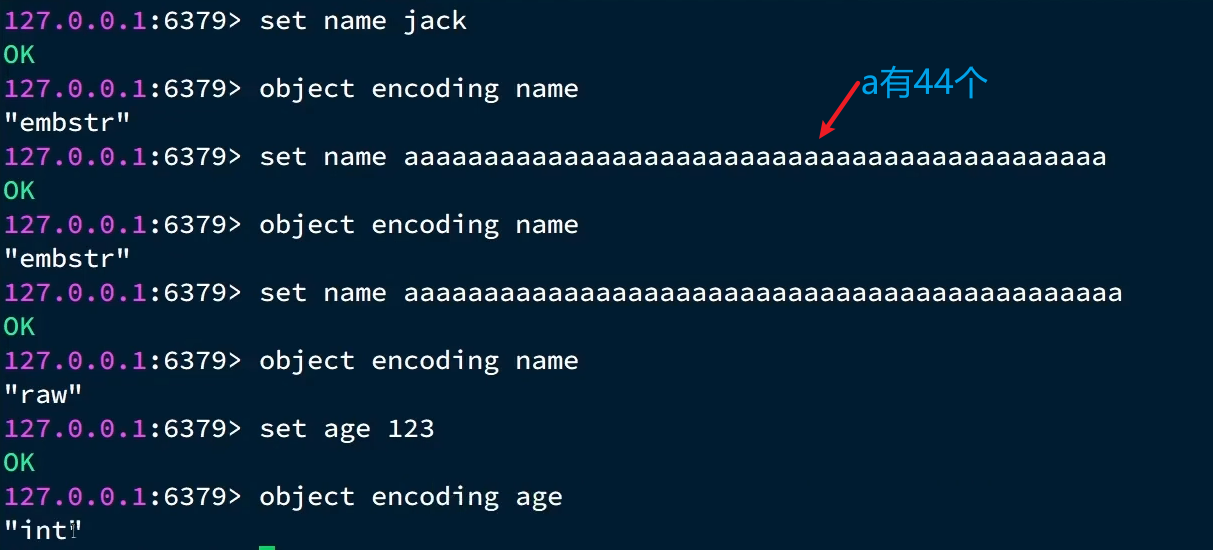
当然,确切地说,String在Redis中是⽤⼀个robj来表示的
用来表示String的robj可能编码成3种内部表⽰:OBJ_ENCODING_RAW,OBJ_ENCODING_EMBSTR,OBJ_ENCODING_INT。其中前两种编码使⽤的
是sds来存储,最后⼀种OBJ_ENCODING_INT编码直接把string存成了long型
在“对string进行incr, decr等操作时”,如果它内部是OBJ_ENCODING_INT编码,那么可以直接行加减操作;如果它内部是OBJ_ENCODING_RAW或
OBJ_ENCODING_EMBSTR编码,那么Redis会先试图把sds存储的字符串转成long型,如果能转成功,再进行加减操作
“对⼀个内部表示成long型的string执行append, setbit, getrange这些命令”,针对的仍然是string的值(即⼗进制表示的字符串),而不是针对内部表⽰的long型进⾏操作。比如字符串”32”,如果按照字符数组来解释,它包含两个字符,它们的ASCII码分别是0x33和0x32。当我们执行命令setbit key 7 0的时候,相当于把字符0x33变成了0x32,这样字符串的值就变成了”22”。⽽如果将字符串”32”按照内部的64位long型来解释,那么它是0x0000000000000020,在这个基础上执⾏setbit位操作,结果就完全不对了。因此,在这些命令的实现中,会把long型先转成字符串再进行相应的操作
Redis对象:List
Redis的List类型可以从首、尾操作列表中的元素,满足这种条件的有以下方式:
- LinkedList :普通链表,可以从双端访问,内存占用较高,内存碎片较多
- ZipList :压缩列表,可以从双端访问,内存占用低,存储上限低
- QuickList:LinkedList + ZipList,可以从双端访问,内存占用较低,包含多个ZipList,存储上限高
在3.2版本之前,Redis采用LinkedList和ZipList来实现List,当元素数量小于512并且元素大小小于64字节时采用ZipList编码,超过则采用LinkedList编码。
在3.2版本之后,Redis统一采用QuickList来实现List:

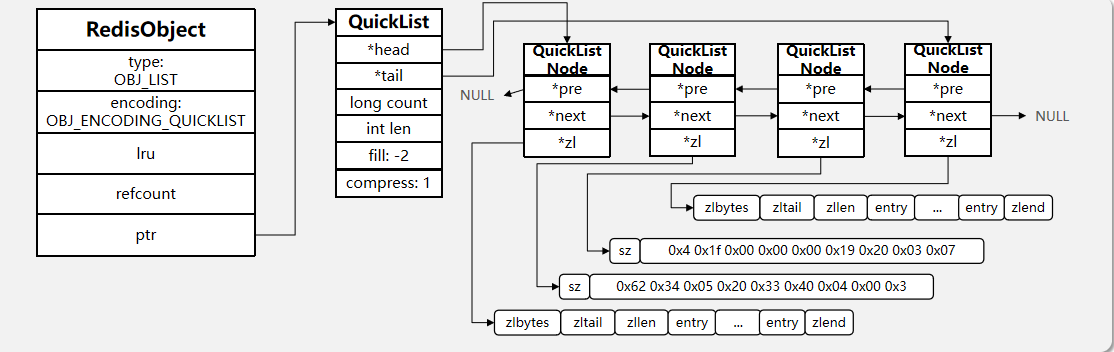
Redis对象:Set
Set是Redis中的单列集合,满足“无序不重复、查询效率高”的特点
什么样的数据结构可以满足?
HashTable,也就是Redis中的Dict,不过Dict是双列集合(可以存键、值对)
Set是Redis中的集合,不一定确保元素有序,可以满足元素唯一、查询效率要求极高。
为了查询效率和唯一性,set采用HT编码(Dict)。Dict中的key用来存储元素,value统一为null。当存储的所有数据都是整数,并且元素数量不超过 set-max-intset-entries 时,Set会采用IntSet编码,以节省内存
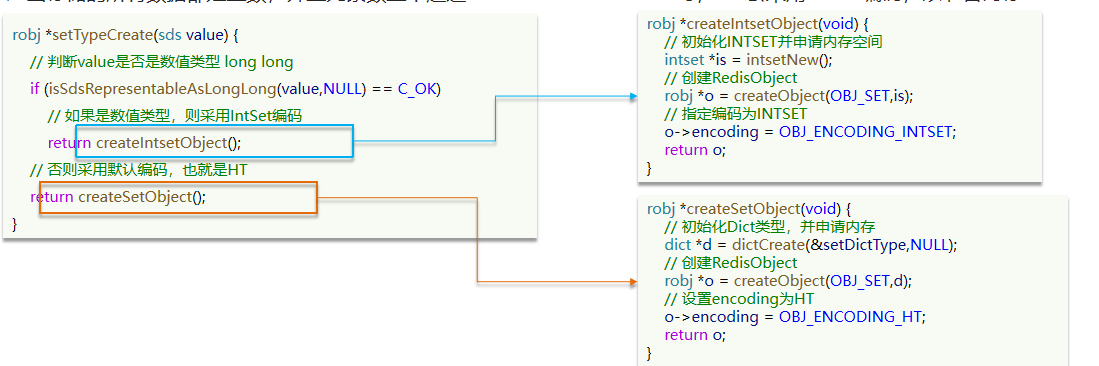
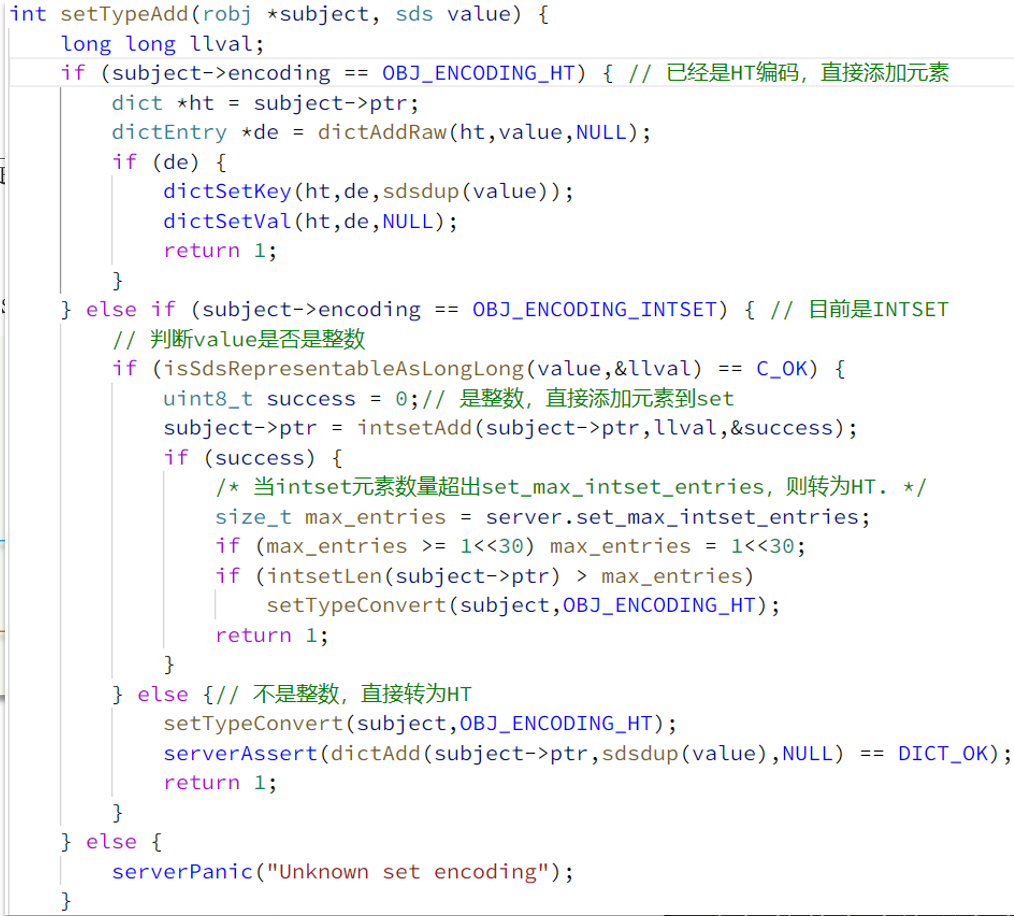
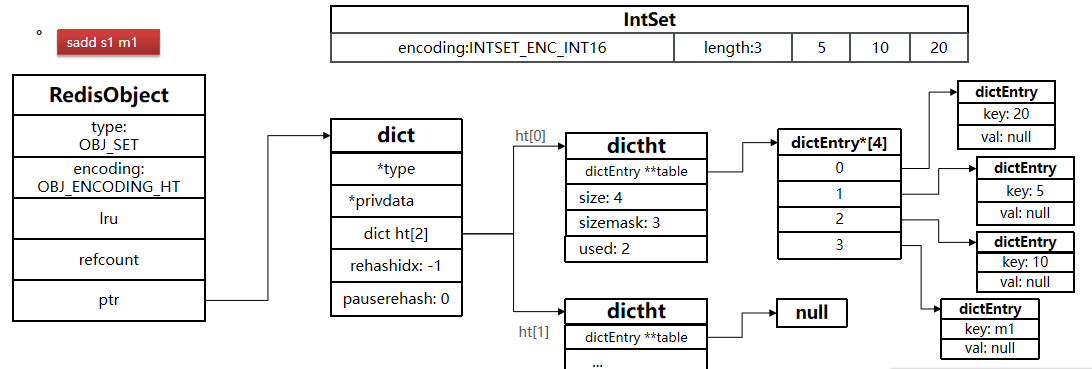
Redis对象:SortedSet
SortedSet也就是ZSet,其中每一个元素都需要指定一个score值和member值:
- 可以根据score值排序后
- member必须唯一
- 可以根据member查询分数

因此,zset底层数据结构必须满足键值存储、键必须唯一、可排序这几个需求。哪种编码结构可以满足?
- SkipList:可以排序,并且可以同时存储score和ele值(member)
- HT(Dict):可以键值存储,并且可以根据key找value


当元素数量不多时,HT和SkipList的优势不明显,而且更耗内存。因此zset还会采用ZipList结构来节省内存,不过需要同时满足两个条件:
- 元素数量小于
zset_max_ziplist_entries,默认值128 - 每个元素都小于
zset_max_ziplist_value字 节,默认值64
ziplist本身没有排序功能,而且没有键值对的概念,因此需要有zset通过编码实现:
- ZipList是连续内存,因此score和element是紧挨在一起的两个entry, element在前,score在后
- score越小越接近队首,score越大越接近队尾,按照score值升序排列
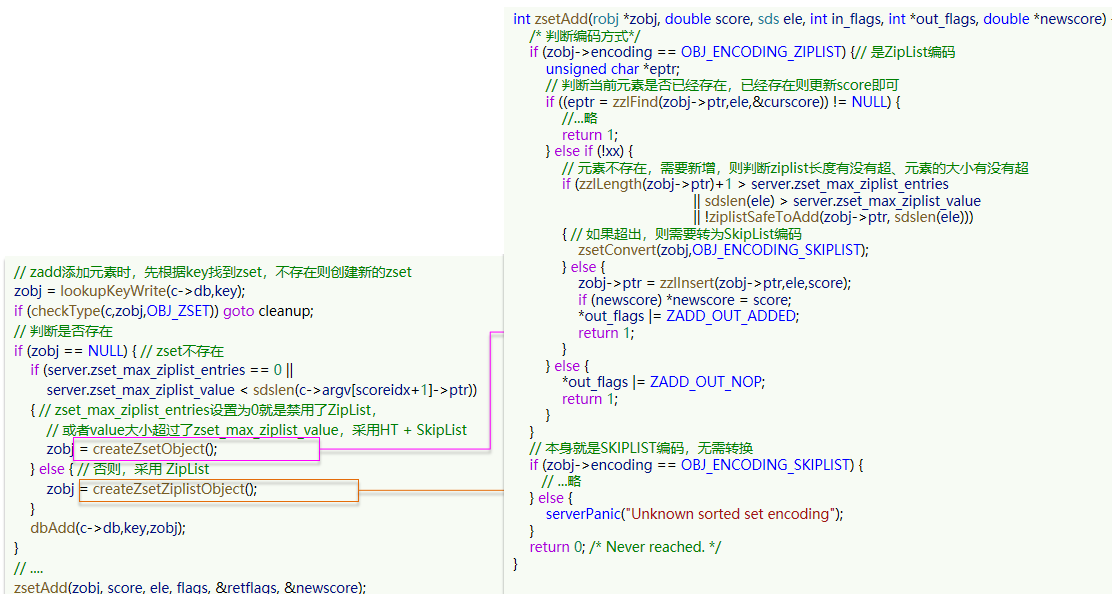

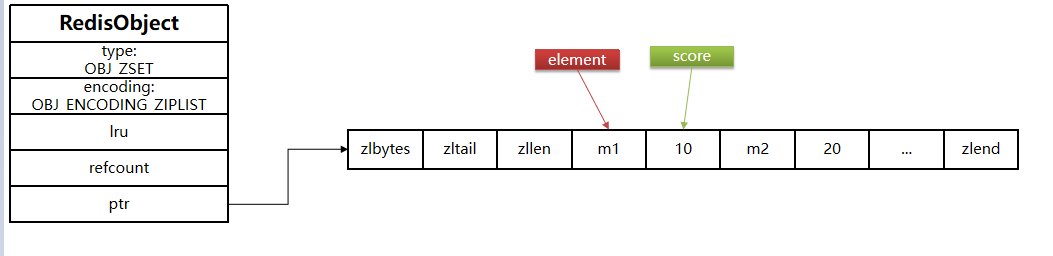
Redis对象:Hash
Hash结构与Redis中的Zset非常类似:
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别如下:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
底层实现方式:压缩列表ziplist 或者 字典dict
当Hash中数据项比较少的情况下,Hash底层才⽤压缩列表ziplist进⾏存储数据,随着数据的增加,底层的ziplist就可能会转成dict,具体配置如下:
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
当满足上面两个条件其中之⼀的时候,Redis就使⽤dict字典来实现hash。
Redis的hash之所以这样设计,是因为当ziplist变得很⼤的时候,它有如下几个缺点:
- 每次插⼊或修改引发的realloc操作会有更⼤的概率造成内存拷贝,从而降低性能。
- ⼀旦发生内存拷贝,内存拷贝的成本也相应增加,因为要拷贝更⼤的⼀块数据。
- 当ziplist数据项过多的时候,在它上⾯查找指定的数据项就会性能变得很低,因为ziplist上的查找需要进行遍历。
总之,ziplist本来就设计为各个数据项挨在⼀起组成连续的内存空间,这种结构并不擅长做修改操作。⼀旦数据发⽣改动,就会引发内存realloc,可能导致内存拷贝。
hash结构如下:

zset集合如下:

因此,Hash底层采用的编码与Zset也基本一致,只需要把排序有关的SkipList去掉即可:
Hash结构默认采用ZipList编码,用以节省内存。 ZipList中相邻的两个entry 分别保存field和value
当数据量较大时,Hash结构会转为HT编码,也就是Dict,触发条件有两个:
- ZipList中的元素数量超过了
hash-max-ziplist-entries(默认512) - ZipList中的任意entry大小超过了
hash-max-ziplist-value(默认64字节)
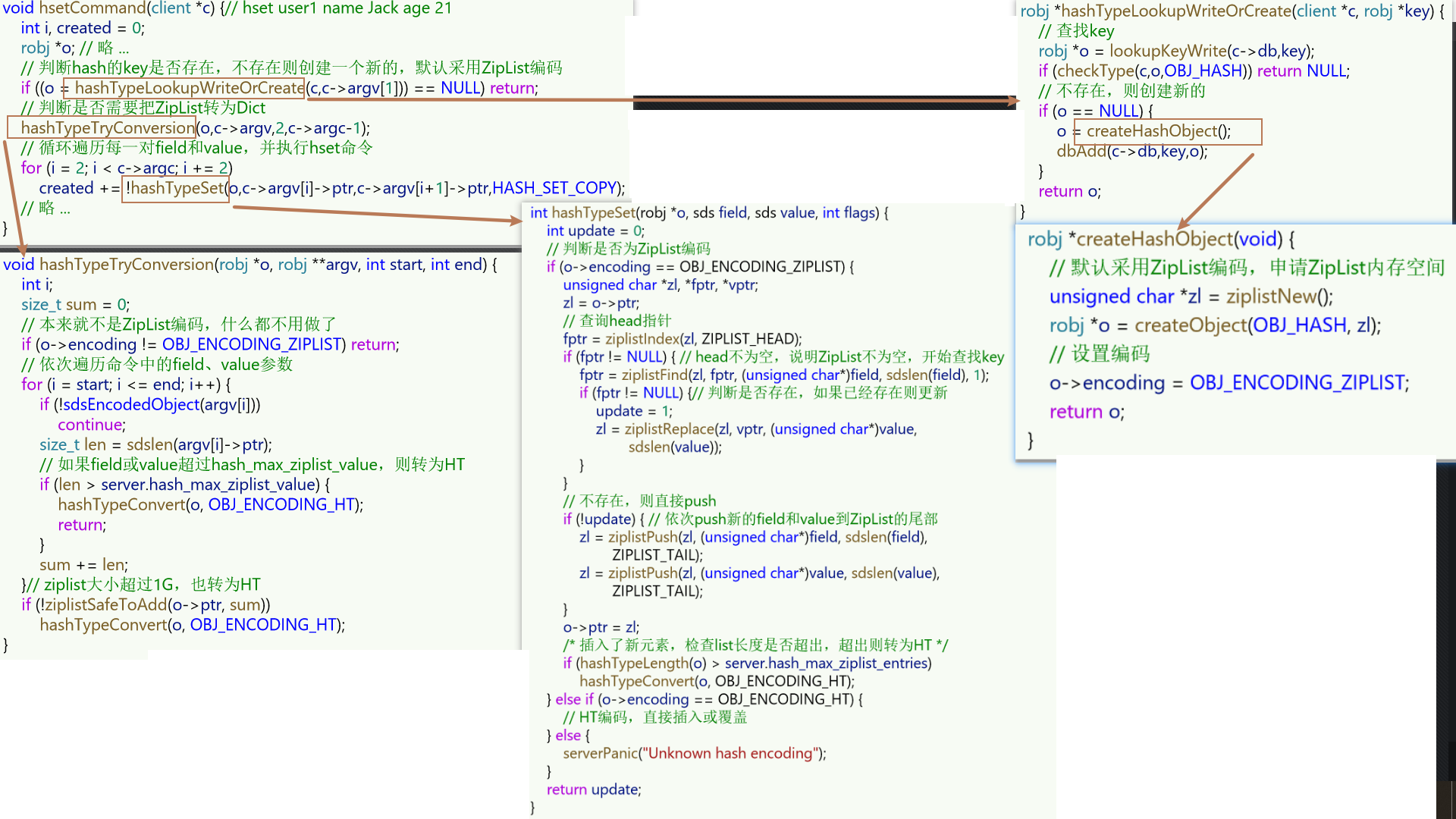

过期Key处理
Redis之所以性能强,最主要的原因就是基于内存存储。然而单节点的Redis其内存大小不宜过大,会影响持久化或主从同步性能。
我们可以通过修改配置文件来设置Redis的最大内存:

当内存使用达到上限时,就无法存储更多数据了。为了解决这个问题,Redis提供了一些策略实现内存回收
内存过期策略
通过expire命令给Redis的key设置TTL(存活时间):key的TTL到期以后,再次访问name返回的是nil,说明这个key已经不存在了,对应的内存也得到释放。从而起到内存回收的目的
Redis本身是一个典型的key-value内存存储数据库,因此所有的key、value都保存在前面玩过的Dict结构中。不过在其database结构体中,有两个Dict:一个用来记录key-value;另一个用来记录key-TTL
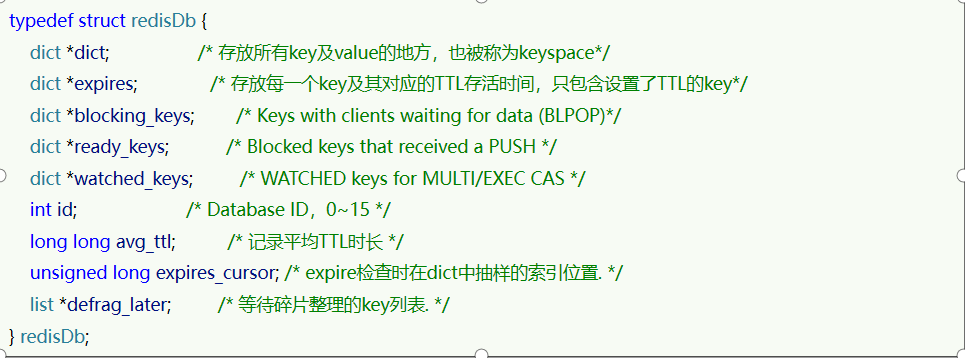
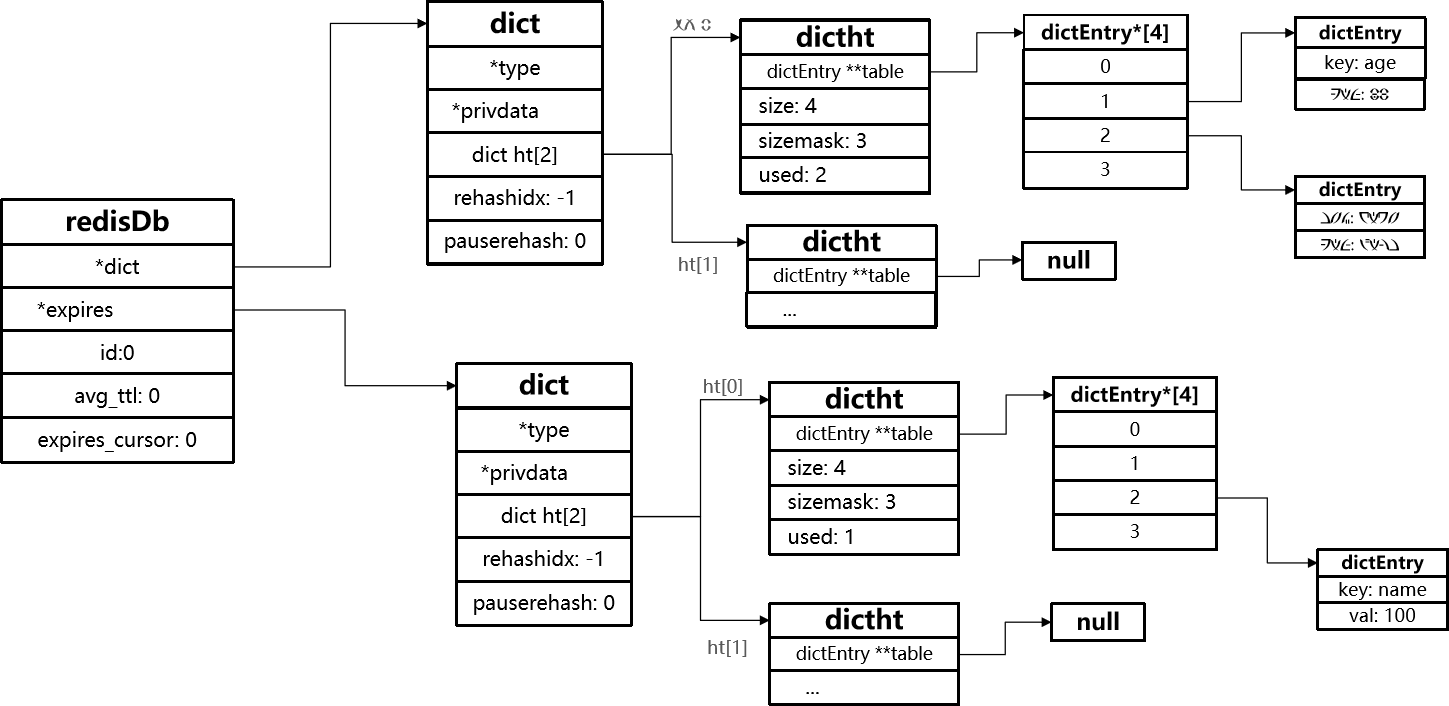
- 问题:Redis是如何知道一个key是否过期?
利用两个Dict分别记录key-value对及key-ttl对
- 问题:是不是TTL到期就立即删除了?
方式一:惰性删除:顾明思议并不是在TTL到期后就立刻删除,而是在访问一个key的时候,检查该key的存活时间,如果已经过期才执行删除

方式二:周期删除:顾明思议是通过一个定时任务,周期性的抽样部分过期的key,然后执行删除。
执行周期有两种:
- Redis服务初始化函数initServer()中设置定时任务,按照server.hz的频率来执行过期key清理,模式为SLOW
- Redis的每个事件循环前会调用beforeSleep()函数,执行过期key清理,模式为FAST
SLOW模式规则:即:低频率高时长
- 执行频率受server.hz影响,默认为10,即每秒执行10次,每个执行周期100ms。
- 执行清理耗时不超过一次执行周期的25%.默认slow模式耗时不超过25ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
- 如果没达到时间上限(25ms)并且过期key比例大于10%,再进行一次抽样,否则结束
FAST模式规则(过期key比例小于10%不执行 ):即:高频率低时长
- 执行频率受beforeSleep()调用频率影响,但两次FAST模式间隔不低于2ms
- 执行清理耗时不超过1ms
- 逐个遍历db,逐个遍历db中的bucket,抽取20个key判断是否过期
如果没达到时间上限(1ms)并且过期key比例大于10%,再进行一次抽样,否则结束
内存淘汰策略
内存淘汰:就是当Redis内存使用达到设置的上限时,主动挑选部分key删除以释放更多内存的流程
Redis会在处理客户端命令的方法processCommand()中尝试做内存淘汰:

Redis支持8种不同策略来选择要删除的key:
- noeviction: 不淘汰任何key,但是内存满时不允许写入新数据,默认就是这种策略。
- volatile-ttl: 对设置了TTL的key,比较key的剩余TTL值,TTL越小越先被淘汰
- allkeys-random:对全体key ,随机进行淘汰。也就是直接从db->dict中随机挑选
- volatile-random:对设置了TTL的key ,随机进行淘汰。也就是从db->expires中随机挑选。
- allkeys-lru: 对全体key,基于LRU算法进行淘汰
- volatile-lru: 对设置了TTL的key,基于LRU算法进行淘汰
- allkeys-lfu: 对全体key,基于LFU算法进行淘汰
- volatile-lfu: 对设置了TTL的key,基于LFI算法进行淘汰
比较容易混淆的有两个:
- LRU(Least Recently Used),最少最近使用。用当前时间减去最后一次访问时间,这个值越大则淘汰优先级越高。
- LFU(Least Frequently Used),最少频率使用。会统计每个key的访问频率,值越小淘汰优先级越高。
edis的数据都会被封装为RedisObject结构:

LFU的访问次数之所以叫做逻辑访问次数,是因为并不是每次key被访问都计数,而是通过运算:
- 生成0~1之间的随机数R
- 计算 (旧次数 * lfu_log_factor + 1),记录为P
- 如果 R < P ,则计数器 + 1,且最大不超过255
- 访问次数会随时间衰减,距离上一次访问时间每隔 lfu_decay_time 分钟,计数器 -1
结合源码整套逻辑如下:
