关于在数据库系统MMAP的使用
问题引出
在数据库系统中对于文件I/O管理,通常有两种选择
- 开发者自己实现buffer bool来管理文件I/O读入内存的数据
- 使用Linux操作系统实现的MMAP系统调用映射到用户地址空间,并且利用对开发者透明的page cache来实现页面的换入换出
理论介绍
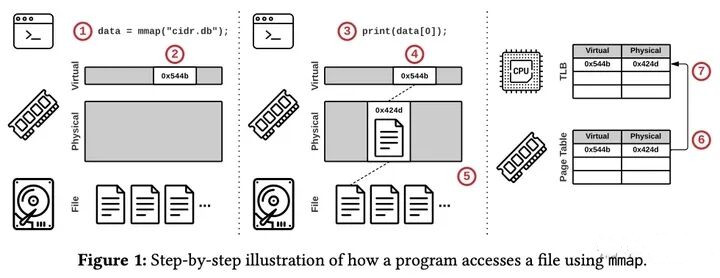
- 程序调用MMAP返回了指向文件内容的指针
- 操作系统保留了一部分虚拟地址空间,但是并没有开始加载文件
- 程序开始使用指针获取文件的内容
- 操作系统尝试在物理内存获取内存页
- 由于内存页此时不存在,因此触发了页错误,开始从物理存储将第3步获取的那部分内容加载到物理内存页中
- 操作系统将虚拟地址映射到物理地址的页表项(Page Table Entry)加入到页表中
- 上述操作使用的CPU核心会将页表项加载到页表缓存(TLB)中
mmap的问题
问题1 事务安全
由于MMAP中页面写回存储的时机不受程序控制,因此当commit还没有发生时,可能会有一部分脏页面已经写回存储了。此时原子性就会失效,在过程中的查询会看到中间状态。
问题2 I/O停顿
由于MMAP将文件加载到内存的过程是操作系统控制的,所以无法保证将要查询的页面在内存中,这时就会出现page cache的换入换出,导致I/O停顿。
问题3 错误处理
首先是MMAP对文件内容的校验要以单个页面为单位,不能基于多个页面来做,因为有可能要使用的页面会被换出。另外,对于一些使用内存不安全语言写的数据库系统(感觉大部分都是用内存不安全的C++写的),指针错误可能导致页面问题。使用buffer pool可以通过写入前的检查规避这个问题,但是MMAP会默默将错误的页面写到存储中。
还有,MMAP要应对的系统调用会出现的SIGBUS信号报错,相比之下使用其他I/O方式的buffer pool就能比较轻松的处理I/O错误。
问题4 性能问题
业界里面大家普遍认为MMAP比传统read/write更快,这主要基于以下两点原因:
- 负责文件映射操作,并且处理page fault的是内核,而不是应用程序
- MMAP帮助避免了用户空间中的额外的复制操作,相应的也减少了内存的占用
MMAP相对于传统read/write I/O在目前高带宽的存储设备上是更差的。,原因如下:
- 单线程的页面换出: 页面换出是单线程的(使用kswapd),这点与CPU相关
- TLB shootdowns 当一个页面失效时,每个核心的TLB都需要一次中断来做刷新操作,这个操作可能会消耗几千个时钟周期,是非常耗时的。
RavenDB的CEO Reply
在构建数据库时,使用 mmap 具有以下优点,操作系统将负责:
- 从磁盘读取数据
- 读取相同数据的不同线程之间的并发性
- 缓存和缓冲区管理
- 从内存中逐出页
- 与机器中的其他进程很好地配合
- 跟踪脏页并写入磁盘
对于 mmap 版本,我们需要计算页面的地址,仅此而已。对于手动缓冲池,我们需要处理的任务列表很长。其中一些要求我们确保线程安全。例如,如果我们将一个页面交给一个事务,我们需要跟踪该页面的状态是否正在使用中。在交易完成之前,我们无法逐出此页面。这意味着我们可能需要进行原子引用计数,这可能会非常高的成本。
实际上,数据库中的数据访问实际上并不是随机的,即使您正在执行随机读取也是如此。有些页面几乎总是会被引用。B+树中的根页面就是一个很好的例子。它总是会被使用。在原子引用计数下,该页面将成为瓶颈。
忽略缓冲池管理的这种开销意味着您实际上并没有比较等效的结构。我还应该指出,我可能忘记了缓冲池还需要管理的其他一些任务,这使它的生命周期大大复杂化。 这一点的原因是那里有一个互斥锁(以及锁下的 I/O),这对于许多缓冲池来说是相当典型的。不考虑缓冲池管理的开销会严重扭曲论文的结果。
解决4个问题
问题1 事务安全
作者并不在乎数据是否在我背后写入内存,而关心的是 MVCC(一个与缓冲区管理完全分开的问题)
当事务提交并且较旧的事务不再需要旧版本的数据时,我可以将数据从修改后的缓冲区推送到 mmap 区域。这往往相当快(考虑到我基本上是在做 memcpy(),它以内存速度运行),除非必须将数据分页
问题2 I/O停顿
作者实际措施是用一个专用线程来处理这种情况。实际上,这与使用异步 I/O 处理它的方式并没有太大区别。
另一个要处理的考虑因素是在内核级别映射的成本。我不是在谈论 I/O 成本,但是如果您有许多线程出错页面,则会遇到页表锁定问题。我们之前遇到过这种情况,这被认为是操作系统级别的错误,但它显然对数据库有影响。但实际上,在大多数情况下,内存管理的开销是相同的。如果您通过 mmap 阅读或直接分配,则需要编排一些事情。请注意,如果您正在大量分配/释放,则相同的页表锁定也会生效,因为您也在修改流程页表。
问题3 错误处理
作者认为对于数据库,处理 I/O 错误只有一个正确答案。崩溃,然后从头开始运行恢复。如果 I/O 系统返回了错误,则不再有任何方法可以知道该错误的状态。恢复的唯一方法是停止,重新加载所有内容(应用 WAL、运行恢复等)并恢复到稳定状态。
问题4 性能问题
- 页表争用
- 单线程页面逐出
- TLB击落
第一个问题是我过去遇到过的问题。这是操作系统中的一个错误,已修复。在Windows和Linux中不再有单页表。
另一方面,单线程驱逐是我们从未遇到过的事情。使用 Voron,我们使用MAP_SHARED映射内存,大多数时候,内存并不脏。如果系统需要内存,则只需丢弃未修改的共享页面的内存即可在分配页面时执行此操作。在此模型中,我们通常将大部分内存视为共享的、干净的。因此,驱逐事物的压力并不大,可以根据需要进行。
TLB击落问题不是我们曾经遇到过的问题。我们已经在具有4GB RAM的Raspberry PI上运行TB范围数据库,并在基准测试中对其进行了测试(远远超过内存容量)。有趣的是,B+Tree 性质意味着树的上层已经在内存中,所以我们最终每个请求都有一个页面错误。为了以显着的方式实际观察TLS击落的成本,您需要具备:
- 非常快的 I/O
- 显著超出内存的工作集
- 无需执行其他处理请求的工作
热门相关:有个人爱你很久 隔壁女孩 大妆 买妻种田:山野夫君,强势宠! 大妆