MySQL 索引结构浅析
索引结构

InnoDB B 树

上面是二叉树和红黑树的结构,其实红黑树是一个自平衡二叉查找树,可以用于解决二叉树顺序插入时形成一个有序链表问题。
但是两者都有一个明显缺点,就是当数据量过大时,层级较深,检索速度慢。
下面分析一下 B树(多路平衡查找树)

名词解析:
- 度数:指的是一个节点的子节点个数。
上面这个 B 树图,度数为 5 也成为 5 阶,最多可以存储 4 个 key,5 个指针。
例如:小于 20 的会走第一个指针找到 【10,15,18】这个子节点,在 20 - 30 之间的会找到 【23,25,28】这个子节点依此推断,如果一个节点 N 个 key,那么就有 N+1 个指针。
这样的数据结构优势非常明显,每一层能存储的数据量增加了,并且有效的降低了树的层级数。

上图是一个 B 数的插入分裂演变过程。
假设这个 B 数的最大度数是 5 阶,那么最多能存储 4 key,5 个指针。
其核心在于插入顺序和分裂过程:简单来说就是按顺序插入,当插入时发现这个节点以及满足 4 个 key 了,那么此时就需要进入到向上分裂过程,这个分裂是从当前节点的中间 key 向上分裂过程。
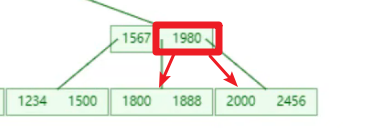
eg:待插入元素 【2456】,当前节点元素【1800,1888,1980,2000】
- 插入前发现当前节点存储的 key 已经到达最大值,此时当前节点需要向上分裂。
- 插入后节点元素为【1800,1888,1980,2000,2456】,此时挑选中间元素向上分裂成为当前节点的父节点。
- 分裂结果:【1980】(父节点元素)、【1800,1888】|【2000,2456】
- 最终效果是:小于【1980】的指针指向【1800,1888】,大于【1980】的指针指向【2000,2456】
InnoDB B+ 数
首先看看经典的 B+ 树结构:

上面这个是经典 B+ 树,其插入顺序和分裂过程跟 B 树类似,主要的区别点有 3 个:
- 分裂过程:在分裂过程中不单单是只将中间元素向上分裂,同时会将向上分裂的那个元素留在分裂后的子结点中。
- 所有的数据都在叶子节点。
- 叶子节点形成一个单线链表。
这分裂过程的特点主要结合所有数据都在叶子节点这个特点去理解。
因为可能我待插入数据他会导致节点出现向上分裂的过程,但是因为 B+ 树所有数据都在叶子节点,所以需要将待插入的数据保存在叶子节点中。
在 InnoDB 中的 B+ 树结构。

从上图中可以看到 MySQL 针对经典 B+ 树进行了优化(要根据物理存储结构以及保证查询效率)。
首先看看针对数据结构有什么优化:
- 叶子节点之间变成了环形双向链表(提高区间访问效率)
- 每个节点都存在页中(由 MySQL 中数据在磁盘I/O的基本单位)。
MySQL 表空间和数据区的概念:
表空间:从 InnoDB 逻辑存储结构来看,所有的数据都被逻辑的存放在一个空间中,这个空间就叫做表空间(tablespace)。表空间由 段(segment)、区(extent)、页(page)组成。创建一个表,磁盘中就有对应的
.ibd文件。在表空间里有很多组数据区,一组数据区(256MB)是256个数据区, 每个数据区(1MB)包含了64个数据页,每个页(16KB)
段(segment):分为索引段,数据段,回滚段等。其中索引段就是非叶子结点部分,而数据段就是叶子结点部分,回滚段用于数据的回滚和多版本控制。一个段包含256个区(256M大小)。
区(extent):区是页的集合,一个区包含64个连续的页,默认大小为 1MB (64*16K)。
页(page):页是 InnoDB 管理的最小单位,常见的有 FSP_HDR,INODE, INDEX 等类型。所有页的结构都是一样的,分为文件头(前38字节),页数据和文件尾(后8字节)。页数据根据页的类型不同而不一样。
小结:
本次简单的对 B 树,B+ 树,InnoDB B+ 树,进行了简单的一个分析。
为了更好的去理解 InnoDB B+ 树,后续可能还需要去详细理解 B+ 树的具体实现、自平衡的原理(左旋右旋)。
后面准备详细学习一下 MySQL 的调优,从建表规范、查询语句优化、索引优化、分库分表 各个方面进行学习。