05、etcd 读请求执行流程
本篇内容主要来源于自己学习的视频,如有侵权,请联系删除,谢谢。
1、etcd读请求概览
etcd是典型的读多写少存储,在我们实际业务场景中,读一般占据2/3以上的请求。一个读 请求从client通过Round-robin(轮询)负载均衡算法,选择一个etcd server节点,发出 gRPC请 求,经过etcd server的 KVServer模块、线性读模块、MVCC的treelndex和 boltdb模块紧 密协作,完成了一个读请求。

思考:通过etcdctl执行如下命令etcd是如何工作的?
etcdctl get hello ‐‐endpoints 192.168.65.210:2379,192.168.65.211:2379,19 2.168.65.212:2379
2、详细步骤解读
2.1 Client 层
主要是对应到步骤 1
1、首先,etcdctl 会对命令中的参数进行解析。
get是请求的方法,它是 KVServer 模块的 提供的API;hello是 我们查询的 key 名;endpoints是我们后端的 etcd 地址。通常,生产环境下中需要配置多个endpoints,这样在 etcd 节点出现故障后,client 就可以自动重连到其它正常的节点,从而保证请求的正常执行。
2、在解析完请求中的参数后,etcdctl 会创建一个 clientv3 库对象,使用 KVServer 模块 的 API 来访问 etcd server。
etcd clientv3 库采用的负载均衡算法为 Round-robin。针对每一个请求,Round-robin 算法通过轮询的方式依次从 endpoint 列表中选择一个 endpoint 访问 (长连接),使 etcd server 负载尽量均衡。
2.2 KVServer 与 拦截器
主要是对应到步骤 2
client 发送 Range RPC 请求到了 server 后就进入了 KVServer 模块。
etcd 通过拦截器以非侵入式的方式实现了许多特性,例如:丰富的 metrics、日志、请求行为检查、所有请求的执行耗时及错误码、来源IP 等。拦截器提供了在执行一个请求前后 的 hook 能力,除了 debug 日志、metrics 统计、对 etcd Learner 节点请求接口和参数限制等能力,etcd 还基于它实现了以下特性:
-
要求执行一个操作前集群必须有 Leader;
-
请求延时超过指定阈值的,打印包含来源 IP 的慢查询日志 (3.5 版本)。
server 收到 client 的 Range RPC 请求后,根据 ServiceName 和 RPC Method 将请求转 发到对应的 handler 实现,handler 首先会将上面描述的一系列拦截器串联成一个拦截器再执行,在拦截器逻辑中,通过调用 KVServer 模块的 Range 接口获取数据。
2.3 串行读与线性读
流程三和四.
etcd 为了保证服务高可用,生产环境一般部署多个节点,多节点之间的数据由于延迟等关系可能会存在不一致的情况。
当 client 发起一个写请求后分为以下几个步骤:
1、Leader 收到写请求,它会将此请求持久化到 WAL 日志,并广播给各个节点;
只有 Leader 节点能处理写请求。
2、若一半以上节点持久化成功,则该请求对应的日志条目被标识为已提交;
3、etcdserver 模块异步从 Raft 模块获取已提交的日志条目,应用到状态机 (boltdb 等)。

此时若client 发起一个读取 hello 的请求,假设此请求直接从状态机中读取,如果连接到的是C节点,若C节点磁盘I/O出现波动,可能导致它应用已提交的日志条目很慢,则会出现更新 hello 为 world 的写命令,在client读 hello 的时候还未被提交到状态机,因此就可能读取到旧数据,如上图查询hello流程所示。
所以在多节点etcd集群中,各个节点的状态机数据一致性存在差异。而我们不同业务场景 的读请求对数据是否最新的容忍度是不一样的,有的场景它可以容忍数据落后几秒甚至几分 钟,有的场景要求必须读到反映集群共识的最新数据。根据业务场景对数据一致性差异的接受程度。
**etcd 中有两种读模式: **
1、串行 (Serializable) 读:
直接读状态机数据返回、无需通过 Raft 协议与集群进行交互, 它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
2、线性读:
etcd
默认读模式是线性读,需要经过 Raft 协议模块,反应的是集群共识,因 此在延时和吞吐量上相比串行读略差一点,适用于对数据一致性要求高的场景。
对数据敏感度较低的场景:
- 直接读状态机数据返回、无需通过 Raft 协议与集群进行交互的模式,在 etcd 里叫做串行 (Serializable) 读,它具有低延时、高吞吐量的特点,适合对数据一致性要求不高的场景。
对数据敏感性高的场景:
- 在 etcd 里面,提供了一种线性读模式来解决对数据一致性要求高的场景。
什么是线性读呢?
你可以理解一旦一个值更新成功,随后任何通过线性读的 client 都能及时访问到。虽然集群中有多个节点,但 client 通过线性读就如访问一个节点一样。etcd 默认读模式是线性读,因为它需要经过 Raft 协议模块,反应的是集群共识,因此在延时和吞吐量上相比串行读略差一点,适用于对数据一致性要求高的场景。
2.4 ReadIndex
在 etcd 3.1 引入了 ReadIndex 机制,保证在串行读的时候,也能读到最新的数据。
接下来看看线性读的执行流程

具体流程如下:
-
当收到一个线性读请求时,它
首先会从Leader获取集群最新的已提交的日志索引(committed index),如上图中的流程二所示。 -
Leader收到
ReadIndex请求时,为防止脑裂等异常场景,会向Follower节点发送心跳确认,一半以上节点确认Leader身份后才能将已提交的索引(committed index)返回给节点C(上图中的流程三)。 -
节点则会等待,直到
状态机已应用索引 (applied index)大于等于Leader的已提交索引时(committed Index)(上图中的流程四),然后去通知读请求,数据已赶上 Leader,你可以去状态机中访问数据了(上图中的流程五)。
以上就是线性读通过ReadIndex机制保证数据一致性原理,当然还有其它机制也能实现线性读,如在早期etcd 3.0中读请求通过走一遍Raft 协议保证一致性,这种Raft log read机制 依赖磁盘IO,性能相比 ReadIndex较差。
总体而言,KVServer模块收到线性读请求后,通过架构图中流程三向Raft模块发起 ReadIndex请求,Raft模块将Leader最新的已提交日志索引封装在流程四的ReadState结构体,通过channel层层返回给线性读模块,线性读模块等待本节点状态机追赶上Leader进度,追赶完成后,就通知KVServer模块,进行架构图中流程五,与状态机中的 MVCC模块进行进行交互了。
2.5 MVCC
流程五中的多版本并发控制(Multiversion concurrency control)模块是为了解决etcd v2不支持保存key的历史版本、不支持多key事务等问题而产生的。它核心由内存树形索引模块 (treelndex)和嵌入式的KV持久化存储库 boltdb 组成。boltdb是个基于B+ tree实现的 key-value键值库,支持事务,提供Get/Put等简易API给etcd操作。
etcd MVCC 具体方案如下:
- 每次修改操作,生成一个
新的版本号 (revision),以版本号为 key, value 为用户 key-value 等信息组成的结构体存储到 blotdb。 - 读取时·先从 treeIndex 中获取 key 的版本号·,再以版本号作为 boltdb 的 key,从 boltdb 中获取其 value 信息。
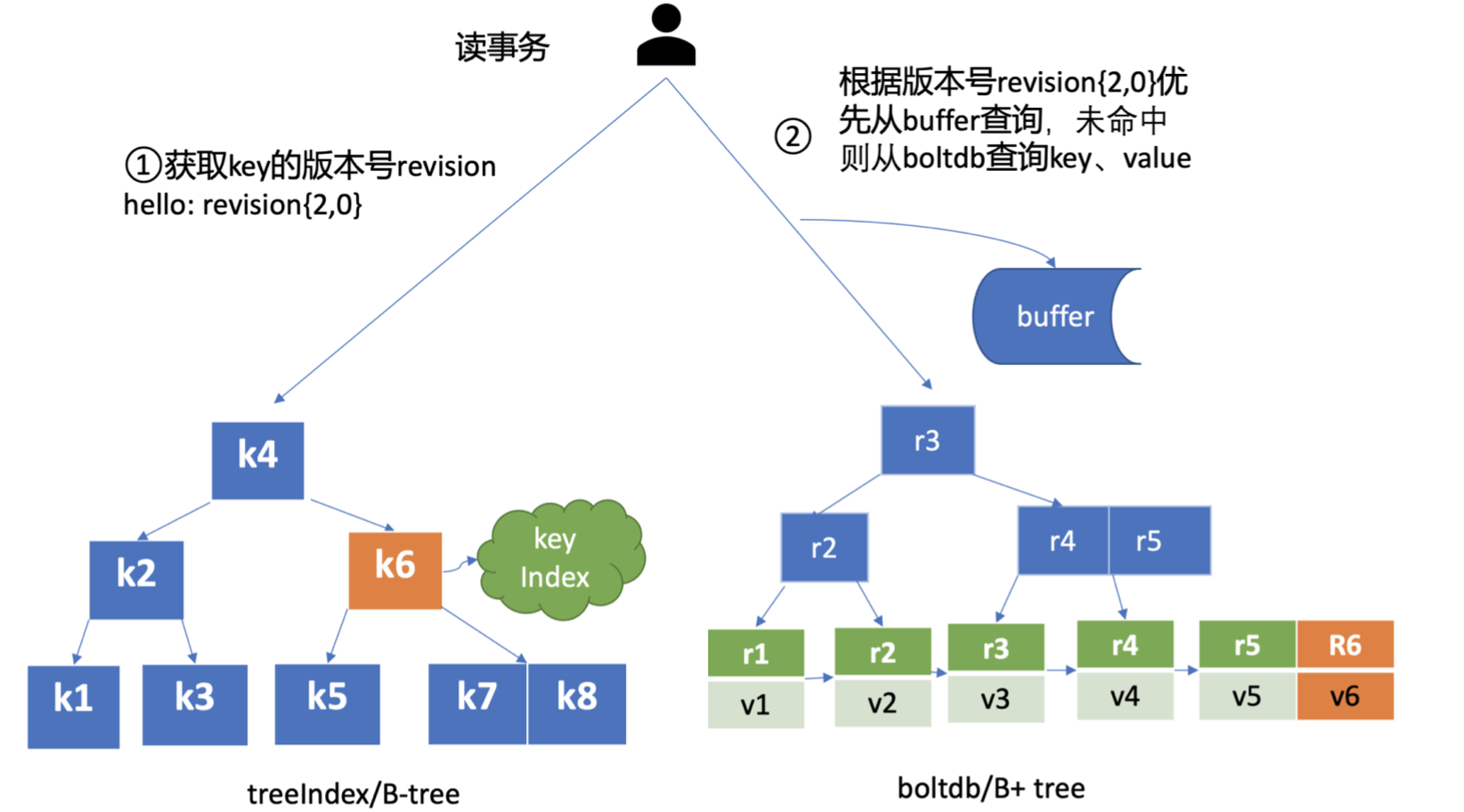
2.6 treelndex
treelndex模块是基于Google开源的内存版btree 库实现的,treeIndex模块只会保存用户的key和相关版本号信息,用户 key 的value数据存储在boltdb里面,相比ZooKeeper和 etcd v2全内存存储,etcd v3对内存要求更低。
简单介绍了etcd如何保存 key的历史版本后,架构图中流程六也就非常容易理解了,它需要从treelndex模块中获取 hello这个 key对应的版本号信息。treeIndex模块基于 B-tree快速查找此 key,返回此 key对应的索引项keyIndex即可。索引项中包含版本号等信息。
2.7 buffer
在获取到版本号信息后,就可从boltdb模块中获取用户的key-value数据了。不过并不是所有请求都—定要从 boltdb 获取数据。etcd出于数据一致性、性能等考虑,在访问boltdb前,首先会从一个内存读事务 buffer中,二分查找你要访问key是否在 buffer里面,若命中则直接返回。
2.8 boltdb
若buffer未命中,此时就真正需要向boltdb模块查询数据了,进入了流程七。 我们知道MySQL通过 table 实现不同数据逻辑隔离,那么在boltdb是如何隔离集群元数据 与用户数据的呢?答案是bucket。
boltdb 里每个 bucket 类似对应 MySQL 一个表,用户的 key 数据存放的 bucket 名字的是 key,etcd MVCC 元数据存放的 bucket 是 meta。
我猜测这里的意思是每个key都当做一个 bucket,然后bucket的名字是 key。这里是猜测的,待验证,若有知道的朋友,请不吝赐教,十分感谢。
因boltdb使用B+ tree来组织用户的key-value数据,获取 bucket key对象后,通过boltdb 的游标Cursor可快速在B+ tree找到 key hello对应的value数据,返回给client。 到这里,一个读请求之路执行完成。
文章来源:
热门相关:有个人爱你很久 回眸医笑,冷王的神秘嫡妃 前任无双 道君 半仙