手记系列之五 ----- SQL使用经验分享
前言
本篇文章主要介绍的关于本人从刚工作到现在使用Sql一些使用方法和经验,从最基本的SQL函数使用,到一些场景的业务场景SQL编写。
SQL基础函数使用
1.字段转换
CASE WHEN
意义: If(a==b) a=c;
用法:
1, CASE 字段 WHEN 字段结果1 THEN 字段显示结果1 WHEN 字段结果2 THEN 字段显示结果2 END
2, CASE WHEN 字段1=字段结果1 THEN 字段显示结果1 WHEN 字段2=字段结果2 THEN 字段显示结果2 END

2.替换空值
意义: if(a==null) a=0;
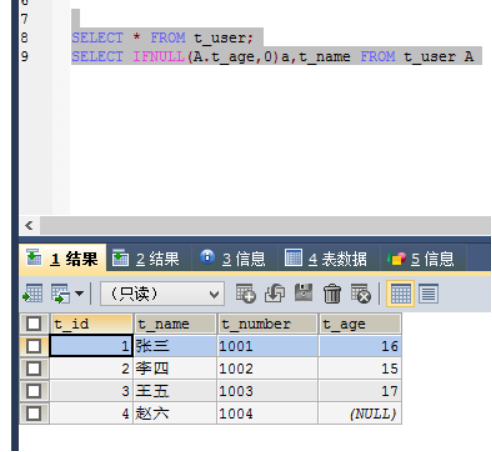
MySQL:IFNULL
用法:IFNULL(字段,0)别名
Oracle:NVL
用法:NVL(字段,0)别名
Sybase: ISNULL
用法:ISNULL(字段,0)别名

3.合计函数
GROUP BY
例:SELECT 字段1, 【如sum】函数名(字段2) FROM 表名 GROUP BY 字段1


4.取某段数据
Mysql: LIMIT
用法: select * from 表 LIMIT 数字 ----取零到数字中的数据
select * from 表 LIMIT 数字1,数字2 ----取数字1到数字2中的数据
Oracle: rownum
用法:select * from 表 rownum<=2 ----取表中的头两条数据
Sybase : TOP
用法: SELECT TOP 2 * FROM 表名 ----选取表中的头两条数据
SELECT TOP 50 PERCENT * FROM 表名 ----选取表中50%的记录

5.截取字符串
substr
例:
select substr(字段名,起始位置,长度)自定义名 from 表名

6.查询结果增加序号
SET @rownum=0;
SELECT @rownum := @rownum +1 AS aid, h.* FROM household h;

7.查询平均小于的某某的数据
group by 和having的使用
SELECT user_id FROM t_user GROUP BY user_id HAVING AVG(user_age)<22;
8.删除重复的元素,保留一条
delete from 表名 where 主键 in
(select 主键 from 表名 group by 删除的字段数据名 having count(1) > 1)
and 主键 not in (select min(主键) from 表名 group by 删除的字段数据名 having count(1)>1)
9. 日期格式使用
DATE_FORMAT 可以把日志格式化成想要的格式
DATE_FORMAT(date, format)
sql设置日期格式TO_DATE(字段名,YYYY-MM-DD)字段名
时间格式化:
SELECT DATE_FORMAT(a.`update_time`,'%Y-%m-%d %H:%i:%S') AS updateTime,
a.`update_time` FROM t_user a
例如:
SELECT DATE_FORMAT('2018-10-10 00:00:00', '%Y%m%d')
查询结果为 20181010
根据日期得到星期几DAYOFWEEK是从周日开始,所以要减一,WEEKDAY是从0开始,所有要加一
SELECT DAYOFWEEK('2021-4-22')-1,WEEKDAY('2021-4-20')+1
10.UNION和UNION All比较
UNION在进行表链接后会筛选掉重复的记录 UNION ALL只是简单的将两个结果合并后就返回
例:SELECT 字段 FROM 表1
UNION
SELECT 字段 FROM 表2
SELECT 字段 FROM 表1
UNION ALL
SELECT 字段 FROM 表2
11. sql之left join、right join、inner join的区别
left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
左表返回的值一定大于或等于右表的值

right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
右表返回的值一定大于或等于左表的值
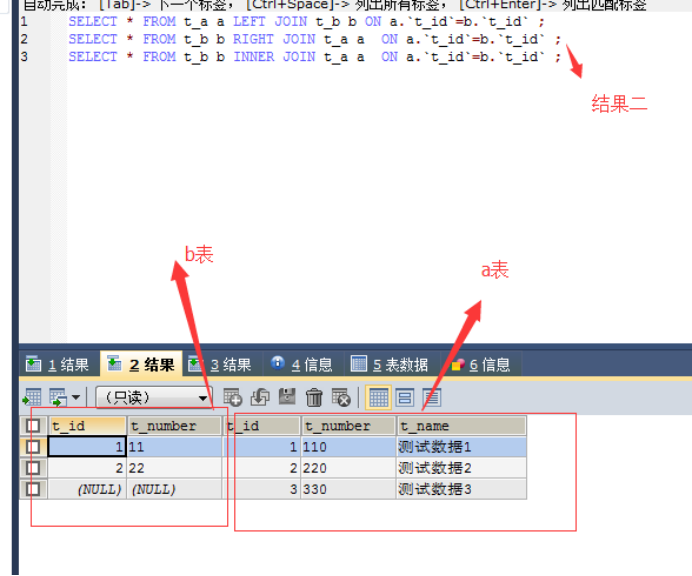
inner join(等值连接) 只返回两个表中联结字段相等的行
左表返回的值一定等于右表返回的值

常用SQL
1.解锁sql表
MySql
1.查看是否有锁表
SHOW OPEN TABLES WHERE In_use > 0;
2.查询产生锁的具体sql
select a.trx_id 事务id ,a.trx_mysql_thread_id 事务线程id,a.trx_query 事务sql from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id;
3.杀死产生锁的事物线程
根据具体的sql判断是不是死锁,具体是什么业务,是否可以进行kill。
然后根据结果 kill掉产生锁的事物线程:
select concat('KILL ',a.trx_mysql_thread_id ,';') from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id;
批量kill :
select concat('KILL ',a.trx_mysql_thread_id ,';') from INFORMATION_SCHEMA.INNODB_LOCKS b,INFORMATION_SCHEMA.innodb_trx a where b.lock_trx_id=a.trx_id into outfile '/tmp/kill.txt';
SqlServer
查看被锁表:
select request_session_id spid,OBJECT_NAME(resource_associated_entity_id) tableName from sys.dm_tran_locks where resource_type='OBJECT'
spid 锁表进程
tableName 被锁表名
解锁:
declare @spid int Set @spid = 57
declare @sql varchar(1000)set @sql='kill '+cast(@spid as varchar)
exec(@sql)
2.查看一个字段的在那些表中
SELECT DISTINCT TABLE_NAME FROM information_schema.`COLUMNS` WHERE COLUMN_NAME='ip' AND TABLE_SCHEMA='guard_scan' AND TABLE_NAME NOT LIKE 'vm%';
SqlServer:
select table_name from user_tab_columns where COLUMN_NAME='字段'
3. 查询所有表及其字段和备注
SELECT t.table_name,
t.colUMN_NAME,
t.DATA_TYPE || '(' || t.DATA_LENGTH || ')',
t1.COMMENTS
FROM User_Tab_Cols t, User_Col_Comments t1
WHERE t.table_name = t1.table_name
AND t.column_name = t1.column_name;
4.sql数据自我复制
insert into test(name,age,gender)
select name,age,gender from test
5.删除重复数据,保留最小id的那一条
delete from table_name as ta where ta.唯一键 <> ( select max(tb.唯一键) from table_name as tb where ta.判断重复的列 = tb.判断重复的列);
6.SQL查询相隔天数语句
--今天
select * from 表名 where to_days(时间字段名) = to_days(now());
--昨天
SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) = 1
--本周
SELECT * FROM 表名 WHERE YEARWEEK( date_format( 时间字段名,'%Y-%m-%d' ) ) = YEARWEEK( now() ) ;
--本月
SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) ,'%Y%m' )
--上一个月
SELECT * FROM 表名 WHERE PERIOD_DIFF(date_format(now(),'%Y%m'),date_format(时间字段名,'%Y%m') =1
--本年
SELECT * FROM 表名 WHERE YEAR( 时间字段名 ) = YEAR( NOW( ) )
--上一月
SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1
--查询本季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
--查询上季度数据
select * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
--查询本年数据
select * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
--查询上年数据
select * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
--查询当前这周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
--查询上周的数据
SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
--查询当前月份的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(now(),'%Y-%m')
--查询距离当前现在6个月的数据
select name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
--查询上个月的数据
select name,submittime from enterprise where date_format(submittime,'%Y-%m')=date_format(DATE_SUB(curdate(), INTERVAL 1 MONTH),'%Y-%m')
7.mysql经纬度圆周计算
单位为米
SELECT st_distance_sphere(POINT('114.43107891381024', '30.52764363752110'), POINT('114.42638694658900', '30.54681469735225')) AS distcance
8.mysql的ip地址段查询判断
ip查询前三段
SELECT SUBSTRING_INDEX(ip,'.',3) FROM t_ip
示例:
SELECT SUBSTRING_INDEX(tia.ip_addr,'.',3),ip_addr FROM t_ip_all tia
WHERE SUBSTRING_INDEX(tia.ip_addr,'.',3) = '192.168.21'
9.mysql的地址段大小查询判断
使用INET_ATON函数进行转换
SELECT
*
FROM
表名
WHERE
INET_ATON(ip) between INET_ATON("192.168.21.0")
AND INET_ATON("192.168.1.255")
其他
MySQL
1.查询所有数据库
show databases;
2.查询指定数据库中所有表名
select table_name from information_schema.tables where table_schema='database_name' and table_type='base table';
3.查询指定表中的所有字段名
select column_name from information_schema.columns where table_schema='database_name' and table_name='table_name';
4.查询指定表中的所有字段名和字段类型
select column_name,data_type from information_schema.columns where table_schema='database_name' and table_name='table_name';
SQLServer
1.查询所有数据库
select * from sysdatabases;
2.查询当前数据库中所有表名
select * from sysobjects where xtype='U';
xtype='U':表示所有用户表,xtype='S':表示所有系统表。
3.查询指定表中的所有字段名
select name from syscolumns where id=Object_Id('table_name');
4.查询指定表中的所有字段名和字段类型
select sc.name,st.name from syscolumns sc,systypes st where sc.xtype=st.xtype and sc.id in(select id from sysobjects where xtype='U' and name='table_name');
Oracle
1.查询所有数据库
由于Oralce没有库名,只有表空间,所以Oracle没有提供数据库名称查询支持,只提供了表空间名称查询。
select * from v$tablespace;--查询表空间(需要一定权限)
2.查询当前数据库中所有表名
select * from user_tables;
3.查询指定表中的所有字段名
select column_name from user_tab_columns where table_name = 'table_name';--表名要全大写
4.查询指定表中的所有字段名和字段类型
select column_name, data_type from user_tab_columns where table_name = 'table_name';--表名要全大写
业务场景SQL
这是在一些常见的场景中个人编写以及收集的一些SQL,从刚开始工作的时候就有记录,如有不妥或有更好的写法,欢迎指出~
学生排名统计
一张表t,有class(班级)、name(学生)、score(成绩)字段
查询每个班级成绩最高的学生
思路:根据分组函数 group by 和最大值 max来实现。
Select name,class,max(score) from t group by class;
查找出每个班级成绩前三的学生
思路: 通过双重子查询来查找
先对学生的成绩进行排名,相同的为一列,然后在跟进这个结果得到前三成绩的学生。
SELECT *
FROM( SELECT NAME,score , class,(SELECT COUNT(*)+1 FROM t WHERE score>b.score AND class = b.class ) rank
FROM t b) e
WHERE e.rank<=3
ORDER BY class,rank ASC;
思路二
直接找到每个班级学生的排名然后进行比较得出前三成绩的学生
SELECT * FROM t a
WHERE 4 >(SELECT count(*)+1 FROM t WHERE class = a.class and score>a.score)
ORDER BY a.class,a.score DESC;
查找出每个班级成绩第二的学生。
思路: 在条件里面发现最大的,然后去除最大的就是第二大的
SELECT class, MAX(score) FROM t WHERE score NOT IN (SELECT MAX(score) FROM t GROUP BY class) GROUP BY class
查询每名学生的学科总分并排名
思路: 先用group by和sum得到总分排名,然后再利用order by将结果进行排名
SELECT *,SUM(scroe)scroe FROM a GROUP BY sID ORDER BY scroe DESC;
查询用一条SQL 语句 查询出每门课都大于80 分的学生姓名
思路一:利用group by和having 函数来查询
SELECT * FROM a GROUP BY scroe HAVING AVG(scroe) >80;
思路二:利用子查询来查询
SELECT * FROM a c WHERE scroe NOT IN (SELECT scroe FROM a b WHERE scroe<='80') GROUP BY sID;
在学生成绩表中进行排名,相同的成绩在同一列
场景一、分数相同排名相同(如果有两个第二,就没有第三名)
思路: 通过子查询的分数进行查询比较,然后在通过子查询的结果进行排序
不包含班级
SELECT id,NAME,score, (SELECT COUNT(*)+1 FROM t_student WHERE score>t.score) rank FROM t_student t ORDER BY rank ASC;
根据班级进行区分
SELECT class,NAME,score,(SELECT COUNT(*)+1 FROM t WHERE score>b.`score` AND class=b.`class` )rank FROM t b ORDER BY class,rank;
场景二、分数相同排名相同(如果有两个第二,有第三名)
思路:需要使用一个额外的变量进行查询比较
SELECT id, NAME, score ,
CASE
WHEN @prevRank = score THEN @curRank
WHEN @prevRank := score THEN @curRank := @curRank + 1
END AS rank
FROM t_student t,
(SELECT @curRank :=0, @prevRank := NULL) r
ORDER BY score
组织部门查询
一张部门表,有id(主键)、name(名称)、parent_id(父级ID)字段
建表语句和测试数据
CREATE TABLE `department` (
`id` int(11) NOT NULL,
`parent_id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO department (id, parent_id, NAME) VALUES
(1, NULL, '总公司'),
(2, 1, '人事部'),
(3, 1, '财务部'),
(4, 1, '市场部'),
(5, 2, '招聘组'),
(6, 2, '培训组'),
(7, 5, '招聘一部'),
(8, 5, '招聘二部'),
(9, 6, '培训一部'),
(10, 6, '培训二部'),
(11, 4, '推广组'),
(12, 11, '线上推广部'),
(13, 11, '线下推广部'),
(14, 12, 'SEM'),
(15, 12, 'SEO');
根据部门ID查询该部门下面所有的子部门
思路: 由于不清楚部门层级,这里需要使用递归查询,需要定义一个变量和FIND_IN_SET函数来实现递归查询。当查询到一个部门时,将其ID添加到一个变量中,然后继续查询其子部门,直到所有子部门都被查询到为止。
SELECT au.id, au.name, au.parent_id
FROM (SELECT * FROM department WHERE parent_id IS NOT NULL) au,
(SELECT @pid := ?) pd
WHERE FIND_IN_SET(parent_id, @pid) > 0
AND @pid := CONCAT(@pid, ',', id)
UNION
SELECT id, NAME, parent_id
FROM department
WHERE id = ?
ORDER BY id;
如果是MySql8.0,可以使用WITH RECURSIVE关键字实现递归查询
WITH RECURSIVE cte AS (
SELECT id, name, parent_id
FROM department
WHERE id = ?
UNION ALL
SELECT d.id, d.name, d.parent_id
FROM department d
INNER JOIN cte ON d.parent_id = cte.id
)
SELECT *
FROM cte;
根据一个部门ID,查询所有的上级部门
思路: 这篇的作者讲得很详细,这里就不在赘述了.
https://www.cnblogs.com/liuxiaoji/p/15219091.html
SELECT t2.id, t2.name, t2.parent_id
FROM (SELECT @r as _id,
(SELECT @r := parent_id FROM department WHERE id = _id) as pid,
@l := @l + 1 as lvl
FROM (SELECT @r := ?, @l := 0) vars, dept as h
WHERE @r <> 0) t1
JOIN department t2
ON t1._id = t2.id
ORDER BY T1.lvl DESC;
如果是MySql8.0,可以使用WITH RECURSIVE关键字实现递归查询
WITH RECURSIVE cte AS ( SELECT id, name, parent_id FROM department WHERE id = ? UNION ALL SELECT d.id, d.name, d.parent_id FROM department d JOIN cte ON cte.parent_id = d.id ) SELECT id, name, parent_id FROM cte WHERE id <> ?;
其他
手记系列
记载个人从刚开始工作到现在各种杂谈笔记、问题汇总、经验累积的系列。
- 手记系列之一 ----- 关于微信公众号和小程序的开发流程
- 手记系列之二 ----- 关于IDEA的一些使用方法经验
- 手记系列之三 ----- 关于使用Nginx的一些使用方法和经验
- 手记系列之四 ----- 关于使用MySql的经验
一首很带感的动漫钢琴曲~
原创不易,如果感觉不错,希望给个推荐!您的支持是我写作的最大动力!
版权声明:
作者:虚无境
博客园出处:http://www.cnblogs.com/xuwujing
CSDN出处:http://blog.csdn.net/qazwsxpcm
个人博客出处:https://xuwujing.github.io/
热门相关:骑士归来 法医娇宠,扑倒傲娇王爷 特工重生:快穿全能女神 战神 朕是红颜祸水