MySQL-DQL
准备测试表,先跟着执行下面的SQL
#1.登录MySQL后
#2.创建test_database数据库,不存在则创建
create database if not exists test_database;
#2.1.如果test_database库存在,可以根据自己意愿删除或换个名称
drop database test_database; #删除test_database数据库
#3.进入刚创建的库
use test_databsase;
#3.1.如果新建的库存在想看库里有没有表
show tables;
#4.创建案例表
#4.1.创建部门表
create table DEPT(
DEPTNO int PRIMARY KEY,
DNAME VARCHAR(14) DEFAULT NULL,
LOC VARCHAR(13) DEFAULT NULL
);
#4.2.创建员工表
CREATE TABLE EMP (
EMPNO int NOT NULL,
ENAME varchar(10) DEFAULT NULL,
JOB varchar(9) DEFAULT NULL,
MGR int DEFAULT NULL,
HIREDATE date DEFAULT NULL,
SAL double(7,2) DEFAULT NULL,
COMM double(7,2) DEFAULT NULL,
DEPTNO int DEFAULT NULL,
PRIMARY KEY (`EMPNO`)
)
#5.插入数据
#5.1.给部门表插入数据
INSERT INTO
DEPT
VALUES
(0,NULL,NULL),
(10,'ACCOUNTING','NEW YORK'),
(20,'RESEARCH','DALLAS'),
(30,'SALES','CHICAGO'),
(40,'OPERATIONS','BOSTON');
#5.2.给员工表插入数据
INSERT INTO
EMP
VALUES
(7369,'SMITH','CLERK',7902,'1980-12-17',800.00,NULL,20),
(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600.00,300.00,30),
(7521,'WARD','SALESMAN',7698,'1981-02-22',1250.00,500.00,30),
(7566,'JONES','MANAGER',7839,'1981-04-02',2975.00,NULL,20),
(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250.00,1400.00,30),
(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850.00,NULL,30),
(7782,'CLARK','MANAGER',7839,'1981-06-09',2450.00,NULL,10),
(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000.00,NULL,20),
(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000.00,NULL,10),
(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500.00,0.00,30),
(7876,'ADAMS','CLERK',7788,'1987-05-23',1100.00,NULL,20),
(7900,'JAMES','CLERK',7698,'1981-12-03',950.00,NULL,30),
(7902,'FORD','ANALYST',7566,'1981-12-03',3000.00,NULL,20),
(7934,'MILLER','CLERK',7782,'1982-01-23',1300.00,NULL,10);
#6.查询记录
select * from DEPT;
select * from EMP;


查询语句DQL
查询语句的格式如下,SQL语句以分号;为结束标记
select columns..
from table_name
where conditions;
根据conditions条件查table_name表中的符合条件数据,只检索columns字段(结束集也只显示columns字段)。
使用 * 可以展示所有的字段。但不建议,这样查询量大,效率低
where子句
用于按需提取满足条件的数据
例:查询EMP表中部门编号为10的员工
select * from EMP where DEPTNO = 10;

SQL使用单引号标注字符串,如果使用的是数值请不要使用单引号
下面是可以在where子句中使用的运算符
| 比软运算符 | 描述 |
|---|---|
| = | 等于 |
| <> | 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 != |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| 逻辑运算符 | 描述 |
|---|---|
| AND | 同时满足左右两个条件的值 |
| OR | 满足左或右其中一个条件的值 |
| NOT | 不满足条件的值 |
| 特殊运算符 | 描述 |
|---|---|
| IS NULL | 表中的空值 |
| BETWEEN | 在某个范围内,配合and使用。这个要注意,必须遵循左小右大,结束集是包含两边的值 |
| LIKE | 搜索某种模式,又称模糊搜索。 |
| IN | 指定针对某个列的多个可能值,注意这里的值不是指一个范围,而是明确的具体值,如:10,2,20,30;也可以搭配not使用,表示不在这个子集中 |
以下是各个运算符的案例
#比较运算符
select * from EMP where DEPTNO <> 30;
select * from EMP where DEPTNO != 10;
select * from EMP where DEPTNO > 20;

#逻辑运算符
select * from EMP where DEPTNO > 10 and DEPTNO != 30;
select * from EMP where JOB = 'SALESMAN' or JOB = 'ANALYST';
select * from EMP where not DEPTNO > 20;

#特殊运算符
select * from EMP where MGR between 7500 and 7700;
select * from EMP where ENAME in ('ALLEN','WARD');
select * from EMP where MGR is null;

like的匹配规则
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
- 使用%和_,代表占位符,其中%表示多个字符,_表示一个字符
A%表示匹配以A开头的任意字符串A_表示匹配二个字符的字符串,以A开头_A%表示匹配二个字符的字符串是A的字符串
select * from EMP where HIREDATE like '1981-0%';

当查询条件为0和1时,SQL会发生隐式转换。0会转换为false,而1即为true。
select * from student where 0;
当条件为false时,返回的结果集为空,因为表中没有符合条件的数据
select * from student where 1;
相反当条件为true时会返回表中的所有记录,因为表中所有记录都满足这个条件
![]()
除了like模糊查询,MySQL还支持其他正则表达式匹配。使用regexp进行正则表达式匹配
| 模式 | 描述 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 '\n' 或 '\r' 之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 '\n' 或 '\r' 之前的位置。 |
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用像 '[.\n]' 的模式。 |
| [...] | 字符集合。匹配所包含的任意一个字符。例如, '[abc]' 可以匹配 "plain" 中的 'a'。 |
| [^...] | 负值字符集合。匹配未包含的任意字符。例如, '[^abc]' 可以匹配 "plain" 中的'p'。 |
| p1 | p2 |
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 | |
| m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
查询ENAME中以A开头的记录
select * from EMP where ENAME regexp '^A';
查询ENAME中以R结束的记录
select * from EMP where ENAME regexp 'R$';
查询ENAME中包含ING的记录
select * from EMP where ENAME regexp 'ING';
当时他们也可以联合使用,如查询以M开头或N结尾的记录
select * from EMP where ENAME regexp '^M|N$';

若存在多个条件时,把每个子条件用括号包裹
假设要把EMP表中领导工号MGR在7800以上,并且员工部门是10和20的查询出来。
select * from EMP where MGR > 7800 and DEPTNO = 20 or DEPTNO = 10;
以上的语句会存在把MGR > 7800 and DEPTNO = 20 当成一个子条件,再把这个子条件的结果与or DEPTNO = 10 去匹配,这样的结果集就与原本要查询的结果不同。存在多个子条件时应该把子条件以括号包裹
select * from EMP where MGR > 7800 and ( DEPTNO = 20 or DEPTNO = 10 );

排序
ORDER BY 用于对结果集按照多个或一个列进行排序
SELECT columns FROM table_name ORDER BY columns [ASC|DESC];
其中 [ASC|DESC] 指定升序或降序排序,默认是ASC升序
查询EMP,结果集按照领导工号MGR升序,如果存在同相的MGR再按照COMM降序排序
select * from EMP order by MGR asc,COMM desc;
查询EMP,结果集按照入职时间HIREDATE升序,如果存在相同时间再按照COMM降序排序
select * from EMP order by HIREDATE asc,COMM desc;

聚合查询
聚合查询,也叫分组查询是根据一个或多个列对结果集进行分组
SELECT customer_name, SUM(sales_amount) FROM sales_orders GROUP BY customer_name;
聚合查询是指对一组数据进行统计分析,例如求和、平均值、最小值、最大值等。而聚合函数则是在执行聚合查询时使用的函数,用于对一组数据进行汇总计算。
GROUP BY语句会将表格中指定列中相同值的行数据分为一组,然后对每组数据执行聚合函数操作(例如求和、计数等),最终将每组的数据在结果集中合并展示。因此,GROUP BY语句可以用于多个列数据的分类汇总统计
聚合函数
常用SQL自常的函数有:
- COUNT(): 计算指定列数据行数
- SUM(): 指定列数据的总和
- AVG(): 指定列数据的平均值
- MAX(): 指定列数据的最大值
- MIN(): 指定列数据的最小值
这些函数要配合group by 一起使用
统计名个部门下人数个数
select DEPTNO,count(ENAME) from EMP group by DEPTNO;

求名个部门的平均工资
select DEPTNO,AVG(SAL) from EMP group by DEPTNO;

SQL函数
与聚合函数不同,SQL不用与其他子句配合使用,他们是对列中每个值分析处理
下面是有关数值的函数:
- ABS():返回一个数的绝对值
- CEIL():向上取整
- FLOOR():向下取整
- ROUND():四舍五入
- MOD():求两个值的余数
- TRUNC():截断
下面是对字符串二次处理的函数:
- CONCAT():连接字符串
- LENGTH():返回字符串长度
- LEFT():返回字符串左边指定长度的子串
- RIGHT():返回字符串右边指定长度的子串
- SUBSTRING():返回部分字符串
- LOWER():将字符串转换为小写字符
- UPPER():将字符串转换为大写字符
- TRIM():去掉字符串首尾空格或指定字符
下面是日期和时间的函数:
- CURRENT_TIME: 返回当前时间
- CURRENT_DATE: 返回当前日期
- DAYOFWEEK():根据日期获取星期几
- DATEPART():返回日期的指定部分
- DATEDIFF():计算两个日期之间的差距
其他:
- COALESCE():选择第一个非空表达式
- NULLIF():如果两个表达式相同,返回null,否则返回第一个表达式
- EXISTS():测试一个子查询是否有结果集
他们中有些函数不需要参数
例:求部门平均工资,取整
select DEPTNO,CEIL(AVG(SAL)) from EMP group by DEPTNO;
select DEPTNO,FLOOR(AVG(SAL)) from EMP group by DEPTNO;

例:求部门平均工资,取余
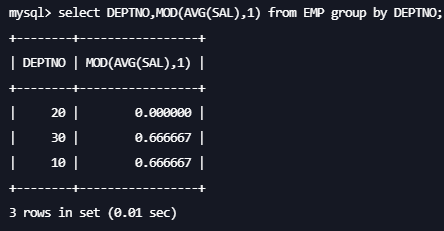
select DEPTNO,MOD(AVG(SAL),1) from EMP group by DEPTNO;
别名
在SQL中,表名称或列名称可以指定别名。这个别名不会改定原来表中的数据,只是为了加强列名称的可读性。
select ENAME as '员工姓名',JOB as '岗位' from EMP e;
在列名称或表名称后加上 as alias_name 。也可以不用显式使用 as ,可以直接在列名或表名后跟上别名即可。

别名的作用:
- 在查询中涉及超过一个表
- 在查询中使用了函数
- 列名称很长或者可读性差
- 需要把两个列或者多个列结合在一起
多表查询(*JOIN连接*)
把来自两个或多个表的行结合起来,基于这些表之间的共同字段,把他们的结果集整合到一张表中
select
columns
from
table_name a
join
table_name b
on
a.column = b.column;
其中,
a.column = b.column是连接条件
select e.ENAME,d.DNAME,d.LOC from EMP as e cross join DEPT as d;
多表查询时,要用
table_name.columns这样的方式避免结果集的列名重复问题;其中,cross join可以省略,以逗号分隔student s,tencher t
上面查出来的结果集是把student表的每一条记录都与tencher表中的记录连接,查询后的结果集记录数是表A总记录数和表B总记录数的乘积。这样的结果毫无意义,这种又被称为笛卡尔积查询。如果没限制他们记录连接的条件,会产生“数据爆炸”。
mysql> select e.ENAME,d.DNAME,d.LOC from EMP as e cross join DEPT as d;
+--------+------------+----------+
| ENAME | DNAME | LOC |
+--------+------------+----------+
| SMITH | OPERATIONS | BOSTON |
| SMITH | SALES | CHICAGO |
| SMITH | RESEARCH | DALLAS |
| SMITH | ACCOUNTING | NEW YORK |
| SMITH | NULL | NULL |
| ALLEN | OPERATIONS | BOSTON |
| ALLEN | SALES | CHICAGO |
| ALLEN | RESEARCH | DALLAS |
| ALLEN | ACCOUNTING | NEW YORK |
| ALLEN | NULL | NULL |
| WARD | OPERATIONS | BOSTON |
| WARD | SALES | CHICAGO |
| WARD | RESEARCH | DALLAS |
| WARD | ACCOUNTING | NEW YORK |
| WARD | NULL | NULL |
| JONES | OPERATIONS | BOSTON |
| JONES | SALES | CHICAGO |
| JONES | RESEARCH | DALLAS |
| JONES | ACCOUNTING | NEW YORK |
| JONES | NULL | NULL |
| MARTIN | OPERATIONS | BOSTON |
| MARTIN | SALES | CHICAGO |
| MARTIN | RESEARCH | DALLAS |
| MARTIN | ACCOUNTING | NEW YORK |
| MARTIN | NULL | NULL |
| BLAKE | OPERATIONS | BOSTON |
| BLAKE | SALES | CHICAGO |
| BLAKE | RESEARCH | DALLAS |
| BLAKE | ACCOUNTING | NEW YORK |
| BLAKE | NULL | NULL |
| CLARK | OPERATIONS | BOSTON |
| CLARK | SALES | CHICAGO |
| CLARK | RESEARCH | DALLAS |
| CLARK | ACCOUNTING | NEW YORK |
| CLARK | NULL | NULL |
| SCOTT | OPERATIONS | BOSTON |
| SCOTT | SALES | CHICAGO |
| SCOTT | RESEARCH | DALLAS |
| SCOTT | ACCOUNTING | NEW YORK |
| SCOTT | NULL | NULL |
| KING | OPERATIONS | BOSTON |
| KING | SALES | CHICAGO |
| KING | RESEARCH | DALLAS |
| KING | ACCOUNTING | NEW YORK |
| KING | NULL | NULL |
| TURNER | OPERATIONS | BOSTON |
| TURNER | SALES | CHICAGO |
| TURNER | RESEARCH | DALLAS |
| TURNER | ACCOUNTING | NEW YORK |
| TURNER | NULL | NULL |
| ADAMS | OPERATIONS | BOSTON |
| ADAMS | SALES | CHICAGO |
| ADAMS | RESEARCH | DALLAS |
| ADAMS | ACCOUNTING | NEW YORK |
| ADAMS | NULL | NULL |
| JAMES | OPERATIONS | BOSTON |
| JAMES | SALES | CHICAGO |
| JAMES | RESEARCH | DALLAS |
| JAMES | ACCOUNTING | NEW YORK |
| JAMES | NULL | NULL |
| FORD | OPERATIONS | BOSTON |
| FORD | SALES | CHICAGO |
| FORD | RESEARCH | DALLAS |
| FORD | ACCOUNTING | NEW YORK |
| FORD | NULL | NULL |
| MILLER | OPERATIONS | BOSTON |
| MILLER | SALES | CHICAGO |
| MILLER | RESEARCH | DALLAS |
| MILLER | ACCOUNTING | NEW YORK |
| MILLER | NULL | NULL |
+--------+------------+----------+
70 rows in set (0.00 sec)
内连接(交叉连接)

内连接是多表查询中最常用的连接操作。
select * from EMP e inner join DEPT d;
在多表查询中使用 on 子句,限制连接条件,从而避免产生笛卡尔积
select
e.ENAME,d.DNAME,d.LOC
from
EMP as e
cross join
DEPT as d
on
e.DEPTNO = d.DEPTNO;
当EMP表DEPTNO字段的值等于DEPT表DEPTNO的值时,两条记录才能连接

where和on的区别。on是在连接时指定的条件,当条件满足时,两条记录才会建立连接;where则是在连接后用于过滤结果集的,使用where还是会存笛卡尔积现象。
where和on可以配合使用
select
*
from
EMP as e
cross join
DEPT as d
on
e.DEPTNO = d.DEPTNO
where
e.SAL > 2000;
当满足 e.DEPTNO = d.DEPTNO 时记录才能连接,对连接后的结果集过滤 e.SAL > 2000

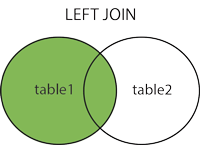
左连接
左连接 left join 又叫左外连接,意思是把join 左边表的全部记录与右表中符合条件的记录连接,右表中没有满足匹配条件的记录,左表的记录照样展示,但对应右表的记录即为null
select
*
from
EMP e
left join
DEPT d
on
d.DEPTNO = e.DEPTNO;

左连接就是把left join 左边的表所有的记录都拿出来,然后把符合 on 条件的右表记录与左表的记录拼接。如果左表的记录在右表中没有符合的记录,那么,其右表的记录表达方式则为null 。
也就是join左边的表记录必须展示,而右表则是按需on 展示拼接。
右连接
右连接 right join 也叫右外连接。和左外连接相同,左边表没有符合条件的则以null 方式展示。

select
*
from
EMP e
right join
DEPT d
on
d.DEPTNO = e.DEPTNO;

右连接就是把right join 右边表的所有记录与左表符合条件 on 的拼接。左表没有符合条件的以null展示。上图中,第一条和最后一条,由于EMP 表中没有DEPTNO=0 和DEPTNO=40 的记录,所以左边的记录显示为NULL
全连接
全连接 full join ,是把两个表相互匹配,也就是左连接和右连接的记录组合在一个表中展示。目前MySQL不支持全连接

select
*
from
EMP e
full join
DEPT d
on
d.DEPTNO = e.DEPTNO;
+------+------+------+---------+----------+------+-------+----------+
| id | name | age | country | class_id | id | name | class_id |
+------+------+------+---------+----------+------+-------+----------+
| 1 | chen | 16 | CN | 10-05 | 11 | zhang | 10-05 |
| 2 | chen | 17 | CN | 10-05 | 11 | zhang | 10-05 |
| 3 | ji | 18 | US | 11-05 | 12 | zhong | 11-05 |
| 4 | ci | 17 | JP | 12-02 | 9 | wen | 12-02 |
| 5 | li | 17 | CN | 11-01 | 7 | li | 11-01 |
| 6 | en | 18 | US | 11-02 | NULL | NULL | NULL |
| 7 | wan | 17 | JP | 12-07 | NULL | NULL | NULL |
| 8 | kan | 17 | CN | 12-08 | NULL | NULL | NULL |
| 9 | suo | 18 | US | 11-01 | 7 | li | 11-01 |
| 10 | ge | 17 | JP | 10-08 | NULL | NULL | NULL |
| 9 | suo | 18 | US | 11-01 | 7 | li | 11-01 |
| 5 | li | 17 | CN | 11-01 | 7 | li | 11-01 |
| NULL | NULL | NULL | NULL | NULL | 8 | lin | 11-08 |
| 4 | ci | 17 | JP | 12-02 | 9 | wen | 12-02 |
| NULL | NULL | NULL | NULL | NULL | 10 | huen | 10-11 |
| 2 | chen | 17 | CN | 10-05 | 11 | zhang | 10-05 |
| 1 | chen | 16 | CN | 10-05 | 11 | zhang | 10-05 |
| 3 | ji | 18 | US | 11-05 | 12 | zhong | 11-05 |
+------+------+------+---------+----------+------+-------+----------+
union操作符
用于合并多个select 语句的结果。要注意,多个select 语句必须要拥有相同数量的字段,字段的数据类型也要相似。
select id,name,class_id from studet
union
select id,name,class_id from tencher;

如果多个查询语句的字段数不同,则提示
ERROR 1222 (21000): The used SELECT statements have a different number of columns
limit
分页查询,如果查询到的记录过多时,可以分页显示
select * from EMP limit 5;
查询结果显示前5条记录

还可以指定从哪条记录开始显示
select * from EMP limit 0,5;
从第一条记录开始显示,向后展示5条记录。

通用的分页公式
limit ((pageNo - 1) * pageSize) , pageSize
pageNo要从哪条数据开始,pageSize每页多少条数据