Apache Arrow DataFusion原理与架构
本篇主要介绍了一种使用Rust语言编写的查询引擎——DataFusion,其使用了基于Arrow格式的内存模型,结合Rust语言本身的优势,达成了非常优秀的性能指标
DataFusion是一个查询引擎而非数据库,因此其本身不具备存储数据的能力。但正因为不依赖底层存储的格式,使其成为了一个灵活可扩展的查询引擎。它原生支持了查询CSV,Parquet,Avro,Json等存储格式,也支持了本地,AWS S3,Azure Blob Storage,Google Cloud Storage等多种数据源。同时还提供了丰富的扩展接口,可以方便的让我们接入自定义的数据格式和数据源。
DataFusion具有以下特性:
- 高性能:基于Rust,不用进行垃圾回收;基于Arrow内存模型,列式存储,方便向量化计算
- 连接简单:能够与Arrow的其他生态互通
- 集成和定制简单:可以扩展数据源,方法和算子等
- 完全基于Rust编写:高质量
基于DataFusion我们可以轻松构建高性能、高质量、可扩展的数据处理系统。
DBMS 与 Query Engine 的区别
DBMS: DataBase Management System
DBMS是一个包含完整数据库管理特性的系统,主要包含以下几个模块:
- 存储系统
- 元数据(Catalog)
- 查询引擎(Query Engine)
- 访问控制和权限
- 资源管理
- 管理工具
- 客户端
- 多节点管理
Query Engine
DataFusion是一种查询引擎,查询引擎属于数据库管理系统的一部分。查询引擎是用户与数据库交互的主要接口,主要作用是将面向用户的高阶查询语句翻译成可被具体执行的数据处理单元操作,然后执行操作获取数据。
DataFusion架构
架构详情

DataFusion查询引擎主要由以下几部分构成:
- 前端
- 语法解析
- 语义分析
- Planner:语法树转换成逻辑计划
主要涉及
DFParser和SqlToRel这两个struct
- 查询中间表示
- Expression(表达式)/ Type system(类型系统)
- Query Plan / Relational Operators(关系算子)
- Rewrites / Optimizations(逻辑计划优化)
主要涉及
LogicalPlan和Expr这两个枚举类
- 查询底层表示
- Statistics(物理计划算子的统计信息,辅助物理计划优化)
- Partitions(分块,多线程执行物理计划算子)
- Sort orders(物理计划算子对数据是否排序)
- Algorithms(物理计划算子的执行算法,如Hash join和Merge join)
- Rewrites / Optimizations(物理计划优化)
主要涉及
PyhsicalPlanner这个trait实现的逻辑计划到物理计划的转换,其中主要的关键点是ExecutionPlan和PhysicalExpr
- 执行运行时(算子)
- 分配资源
- 向量化计算
主要涉及所有执行算子,如
GroupedHashAggregateStream
扩展点
DataFusion查询引擎的架构还是比较简单的,其中的扩展点也非常清晰,我们可以从以下几个方面对DataFusion进行扩展:
用户自定义函数UDF
无状态方法
/// 逻辑表达式枚举类
pub enum Expr {
...
ScalarUDF {
/// The function
fun: Arc<ScalarUDF>,
/// List of expressions to feed to the functions as arguments
args: Vec<Expr>,
},
...
}
/// UDF的逻辑表达式
pub struct ScalarUDF {
/// 方法名
pub name: String,
/// 方法签名
pub signature: Signature,
/// 返回值类型
pub return_type: ReturnTypeFunction,
/// 方法实现
pub fun: ScalarFunctionImplementation,
}
/// UDF的物理表达式
pub struct ScalarFunctionExpr {
fun: ScalarFunctionImplementation,
name: String,
/// 参数表达式列表
args: Vec<Arc<dyn PhysicalExpr>>,
return_type: DataType,
}
用户自定义聚合函数UADF
有状态方法
/// 逻辑表达式枚举类
pub enum Expr {
...
AggregateUDF {
/// The function
fun: Arc<AggregateUDF>,
/// List of expressions to feed to the functions as arguments
args: Vec<Expr>,
/// Optional filter applied prior to aggregating
filter: Option<Box<Expr>>,
},
...
}
/// UADF的逻辑表达式
pub struct AggregateUDF {
/// 方法名
pub name: String,
/// 方法签名
pub signature: Signature,
/// 返回值类型
pub return_type: ReturnTypeFunction,
/// 方法实现
pub accumulator: AccumulatorFunctionImplementation,
/// 需要保存的状态的类型
pub state_type: StateTypeFunction,
}
/// UADF的物理表达式
pub struct AggregateFunctionExpr {
fun: AggregateUDF,
args: Vec<Arc<dyn PhysicalExpr>>,
data_type: DataType,
name: String,
}
用户自定义优化规则
Optimizer定义了承载优化规则的结构体,其中optimize方法实现了逻辑计划优化的过程。优化规则列表中的每个优化规则会被以TOP-DOWN或BOTTOM-UP方式作用于逻辑计划树,优化规则列表会被实施多个轮次。我们可以通过实现OptimizerRule这个trait来实现自己的优化逻辑。
pub struct Optimizer {
/// All rules to apply
pub rules: Vec<Arc<dyn OptimizerRule + Send + Sync>>,
}
pub trait OptimizerRule {
/// Try and rewrite `plan` to an optimized form, returning None if the plan cannot be
/// optimized by this rule.
fn try_optimize(
&self,
plan: &LogicalPlan,
config: &dyn OptimizerConfig,
) -> Result<Option<LogicalPlan>>;
...
}
用户自定义逻辑计划算子
/// 逻辑计划算子枚举类
pub enum LogicalPlan {
...
Extension(Extension),
...
}
/// 自定义逻辑计划算子
pub struct Extension {
/// The runtime extension operator
pub node: Arc<dyn UserDefinedLogicalNode>,
}
/// 自定义逻辑计划算子需要实现的trait
pub trait UserDefinedLogicalNode: fmt::Debug + Send + Sync { ... }
用户自定义物理计划算子
/// 为自定义的逻辑计划算子`UserDefinedLogcialNode`生成对应的物理计划算子
pub trait ExtensionPlanner {
async fn plan_extension(
&self,
planner: &dyn PhysicalPlanner,
node: &dyn UserDefinedLogicalNode,
logical_inputs: &[&LogicalPlan],
physical_inputs: &[Arc<dyn ExecutionPlan>],
session_state: &SessionState,
) -> Result<Option<Arc<dyn ExecutionPlan>>>;
}
/// DataFusion默认的逻辑计划到物理计划的转换器提供了自定义转换过程的结构体
pub struct DefaultPhysicalPlanner {
extension_planners: Vec<Arc<dyn ExtensionPlanner + Send + Sync>>,
}
/// 自定义物理计划算子需要实现的trait
pub trait ExecutionPlan: Debug + Send + Sync { ... }
用户自定义数据源
可以看出,自定义数据源其实就是生成一个对应的ExecutionPlan执行计划,这个执行计划实施的是扫表的任务。如果数据源支持下推的能力,我们在这里可以将projection filters limit等操作下推到扫表时。
/// 自定义数据源需要实现的trait
pub trait TableProvider: Sync + Send {
...
async fn scan(
&self,
state: &SessionState,
projection: Option<&Vec<usize>>,
filters: &[Expr],
limit: Option<usize>,
) -> Result<Arc<dyn ExecutionPlan>>;
...
}
用户自定义元数据
pub trait CatalogProvider: Sync + Send {
...
/// 根据名称获取Schema
fn schema(&self, name: &str) -> Option<Arc<dyn SchemaProvider>>;
/// 注册Schema
fn register_schema(
&self,
name: &str,
schema: Arc<dyn SchemaProvider>,
) -> Result<Option<Arc<dyn SchemaProvider>>> {
// use variables to avoid unused variable warnings
let _ = name;
let _ = schema;
Err(DataFusionError::NotImplemented(
"Registering new schemas is not supported".to_string(),
))
}
}
pub trait SchemaProvider: Sync + Send {
...
/// 根据表名获取数据源
async fn table(&self, name: &str) -> Option<Arc<dyn TableProvider>>;
/// 注册数据源
fn register_table(
&self,
name: String,
table: Arc<dyn TableProvider>,
) -> Result<Option<Arc<dyn TableProvider>>> {
Err(DataFusionError::Execution(
"schema provider does not support registering tables".to_owned(),
))
}
...
}
逻辑计划(LogicalPlan)
逻辑计划其实就是数据流图,数据从叶子节点流向根节点
let df: DataFrame = ctx.read_table("http_api_requests_total")?
.filter(col("path").eq(lit("/api/v2/write")))?
.aggregate([col("status")]), [count(lit(1))])?;
这里我们就使用DataFusion的API接口构造了一个数据流,首先read_table节点会从数据源中扫描数据到内存中,然后经过filter节点按照条件进行过滤,最后经过aggregate节点进行聚合。数据流过最后的节点时,就生成了我们需要的数据。
上述链式调用的API接口实际上并没有真正执行对数据的操作,这里实际上是使用了建造者模式构造了逻辑计划树。最终生成的DataFrame实际上只是包含了一下信息:
pub struct DataFrame {
/// 查询上下文信息,包含了元数据,用户注册的UDF和UADF,使用的优化器,使用的planner等信息
session_state: SessionState,
/// 逻辑计划树的根节点
plan: LogicalPlan,
}
支持的逻辑计划算子
点击查看代码
Projection
Filter
Window
Aggregate
Sort
Join
TableScan
Repartition
Union
Subquery
Limit
Extension
Distinct
Values
Explain
Analyze
SetVariable
Prepare
Dml(...)
CreateExternalTable
CreateView
CreateCatalogSchema
CreateCatalog
DropTable
DropView
逻辑计划优化
目标:确保结果相同的情况下,执行更快
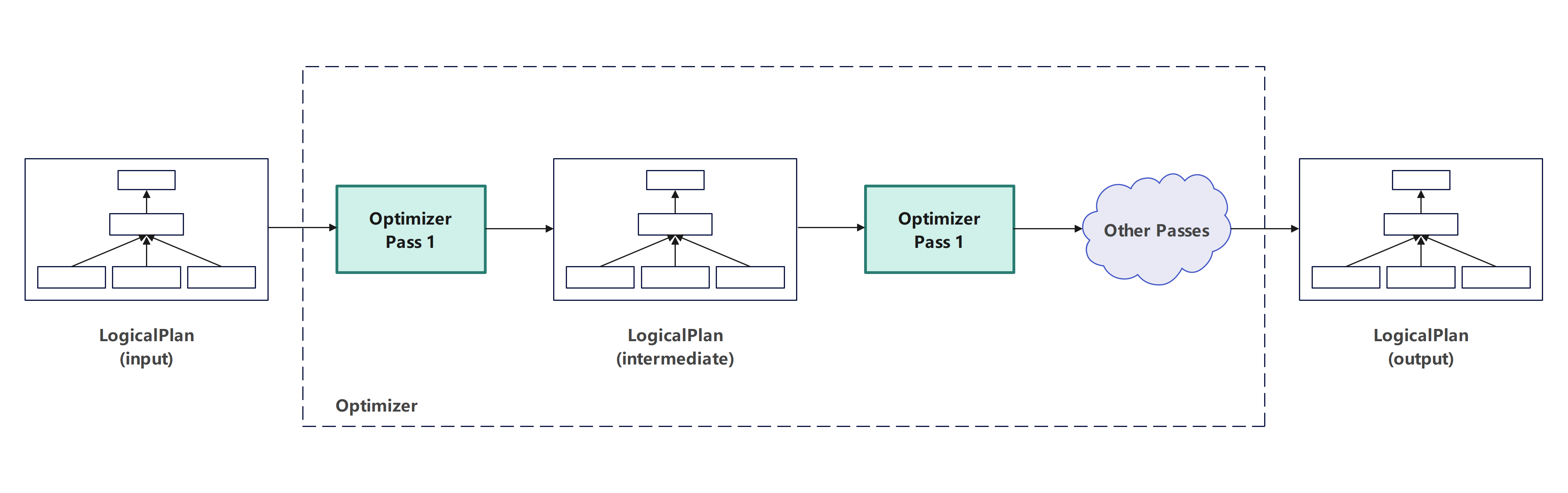
初始的逻辑计划,需要经过多个轮次的优化,才能生成执行效率更高的逻辑计划。DataFusion本身的优化器内置了很多优化规则,用户也可以扩展自己的优化规则。
内置优化轮次
-
下推(Pushdown):减少从一个节点到另一个节点的数据的行列数
PushDownProjectionPushDownFilterPushDownLimit
-
简化(Simplify):简化表达式,减少运行时的运算。例如使用布尔代数的法则,将
b > 2 AND b > 2简化成b > 2。SimplifyExpressionsUnwrapCastInComparison
-
简化(Simplify):删除无用的节点
-
平铺子查询(Flatten Subqueries):将子查询用join重写
DecorrelateWhereExistsDecorrelatedWhereInScalarSubqueryToJoin
-
优化join:识别join谓词
ExtractEqualJoinPredicateRewriteDisjunctivePredicateFilterNullJoinKeys
-
优化distinct
SingleDistinctToGroupByReplaceDistinctWithAggregate
表达式运算(Expression Evaluation)
假设现在有这样一个谓词表达式
path = '/api/v2/write' or path is null
经过语法解析和转换后,可以用如下表达式树表示:

DataFusion在实施表达式运算时,使用了Arrow提供的向量化计算方法来加速运算

物理计划(ExecutionPlan)

调用DataFusion提供的DefaultPhysicalPlanner中的create_physical_plan方法,可以将逻辑计划树转换成物理计划树。其中物理计划树中的每个节点都是一个ExecutionPlan。执行物理计划树时,会从根节点开始调用execute方法,调用该方法还没有执行对数据的操作,仅仅是将每个物理计划算子转换成一个RecordBatchStream算子,形成数据流算子树。这些RecordBatchStream算子都实现了future包提供的Stream特性,当我们最终调用RecordBatchStream的collect方法时,才会从根节点开始poll一次来获取一下轮要处理的数据,根节点的poll方法内会调用子节点的poll方法,最终每poll一次,整棵树都会进行一次数据从叶子节点到根节点的流动,生成一个RecordBatch。

DataFusion实现的物理计划算子具有以下特性:
- 异步:避免了阻塞I/O
- 流式:数据是流式处理的
- 向量化:每次可以向量化地处理一个
RecordBatch - 分片:每个算子都可以并行,可以产生多个分片
- 多核
结语
DataFusion本身只是一个简单,高效,可扩展的查询引擎框架,用户可以将DataFusion作为开发大型数据中台的基础组件,也可以轻易地将DataFusion嵌入服务中作为查询引擎,也可以使用DataFusion构建自己的数据库系统。如果期望使用分布式的查询引擎,可以关注基于Arrow和DataFusion搭建的分布式查询引擎Ballista。