AMD发布GPU加速器MI300X:训练AI模型比英伟达H100最高快60%
12月7日消息,AMD在7日凌晨 2 点举办“Advancing AI”活动中,正式宣布了旗舰 AI GPU 加速器 MI300X,其性能比英伟达的 H100 高出 60%。

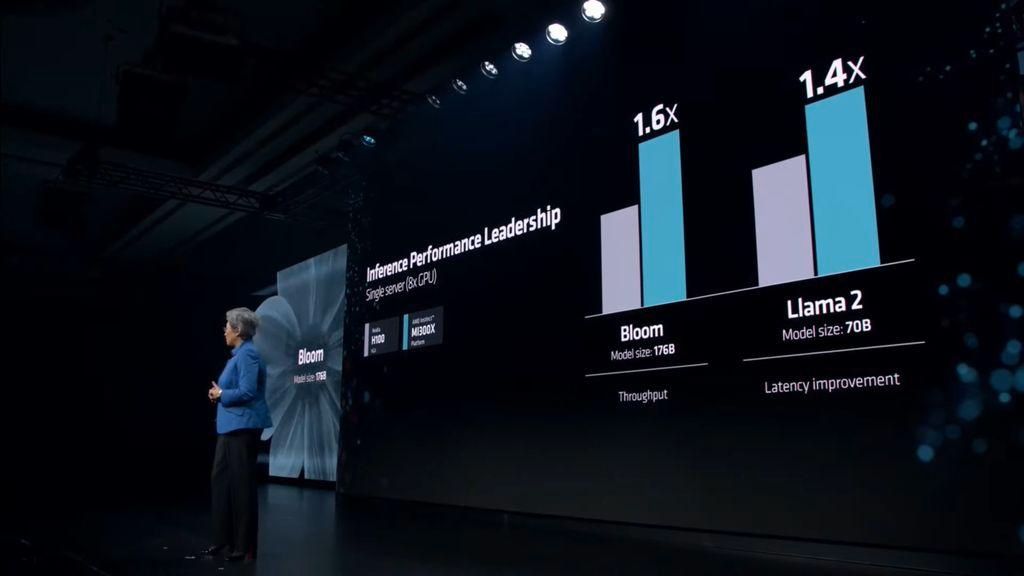
IT之家报道,AMD 提到,在训练性能方面,MI300X 与竞争对手(H100)不相上下,并提供具有竞争力的价格 / 性能,同时在推理工作负载方面表现更为出色。
该芯片完全基于 CDNA 3 架构设计,混合使用 5nm 和 6nm IP,晶体管数量达到 1530 亿个。

设计方面,主中介层采用无源芯片布局,该芯片使用第 4 代 Infinity Fabric 解决方案容纳互连层。中介层总共包括 28 个芯片,其中包括 8 个 HBM3 封装、16 个 HBM 封装之间的虚拟芯片和 4 个有源芯片,每个有源芯片都有 2 个计算芯片。

每个基于 CDNA 3 GPU 架构的 GCD 总共有 40 个计算单元,相当于 2560 个内核。总共有八个计算芯片 (GCD),因此总共有 320 个计算和 20,480 个核心单元。
在良率方面,AMD 将缩减这些内核的一小部分,我们将看到总共 304 个计算单元(每个 GPU 小芯片 38 个 CU),总共有 19,456 个流处理器。
内存方面,MI300X 采用 HBM3 内存,容量最高 192GB,比前代 MI250X(128 GB)高 50%。该内存将提供高达 5.3 TB / s 的带宽和 896 GB/s 的 Infinity Fabric 带宽。
AMD 为 MI300X 配备了 8 个 HBM3 堆栈,每个堆栈为 12-Hi,同时集成了 16 Gb IC,每个 IC 为 2 GB 容量或每个堆栈 24 GB。
相比之下,NVIDIA 即将推出的 H200 AI 加速器提供 141 GB 容量,而英特尔的 Gaudi 3 将提供 144 GB 容量。
在功耗方面,AMD Instinct MI300X 的额定功率为 750W,比 Instinct MI250X 的 500W 增加了 50%,比 NVIDIA H200 增加了 50W。

其中一种配置是技嘉的 G593-ZX1 / ZX2 系列服务器,提供多达 8 个 MI300X GPU 加速器和两个 AMD EPYC 9004 CPU。这些系统将配备多达 8 个 3000W 电源,总功率为 18000W。